社区
CSS
帖子详情
爬虫问题
xbdwswww
2021-02-09 08:19:29
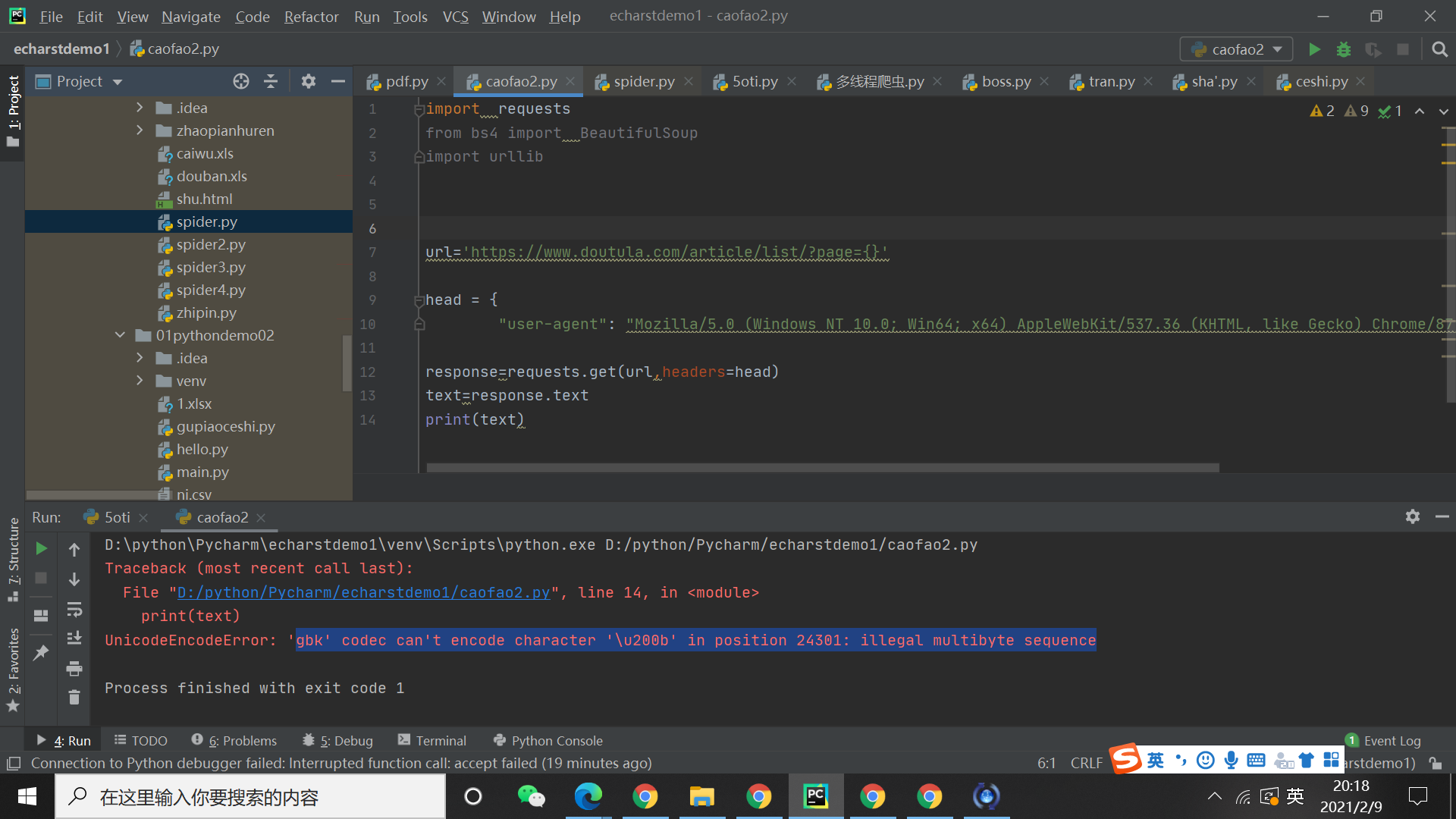
为什么之前不会,现在打印的时候出现这个问题??????????????????????????????????????急
...全文
471
5
打赏
收藏
爬虫问题
为什么之前不会,现在打印的时候出现这个问题??????????????????????????????????????急
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
5 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
xbdwswww
2021-02-20
打赏
举报
回复
是UTF8环境啊
坚持不懈的大白
2021-02-19
打赏
举报
回复
博客链接为:https://blog.csdn.net/qq_45404396/article/details/104854399
sxysoft_csdn
2021-02-19
打赏
举报
回复
编码改成utf-8
xbdwswww
2021-02-10
打赏
举报
回复
咋解决啊大佬?
HuangHe201691
2021-02-10
打赏
举报
回复
看下是不是编码有问题
全球各国汇率、短长期、政策利率数据(1914-2024.3)
根据国际货币基金组织(IMF)等平台的数据,整理了全球各国的兑美元汇率,短期利率、长期利率、政策利率数据,时间范围最新至2024年3月,希望对大家有所帮助 一、数据介绍 数据名称:全球各国汇率、短长期、政策利率数据 数据范围:全球国家 样本数量:76403条 数据年份:1914-2024.3 数据说明:包含兑美元汇率、短期利率、长期利率、政策利率 更新时间:2024年3月 二、指标范围 单位 国家 年份 兑美元汇率-月度均值 兑美元汇率-年度均值 短期利率 长期利率 政策利率
YOLO算法实验室电子仪器电源状态目标检测数据集-60张-标注类别为关机状态-开机状态.zip
YOLOv11目标检测实战项目
样本--2026-2032中国舆情监控系统市场现状研究分析与发展前景预测报告--Wangliu.pdf
样本--2026-2032中国舆情监控系统市场现状研究分析与发展前景预测报告--Wangliu.pdf
pip-matplotlib-3.6.3-pp38-pypy38_pp73-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.zip
pip-matplotlib-3.6.3-pp38-pypy38_pp73-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.zip
【显示驱动技术】SSD2828QN4 MIPI主桥接芯片数据手册:支持高速串行接口与传统RGB并行接口转换,适用于移动显示设备中的图像数据传输应用
内容概要:SSD2828QN4是一款MIPI主桥接芯片,用于连接应用处理器与传统并行LCD接口及支持MIPI从属接口的LCD驱动器。该芯片支持最高每通道1Gbps的串行链路速度,最多可配置4个数据通道,显著减少了信号数量。它支持多种接口模式,包括RGB+SPI组合接口,适用于驱动智能或非智能显示面板,并能通过命令模式和视频模式传输数据。芯片内置时钟和复位模块、外部接口、协议控制单元(PCU)、包处理单元(PPU)、错误校正码/循环冗余校验(ECC/CRC)模块、长包和命令缓冲区、D-PHY控制器、模拟收发器以及内部锁相环(PLL),确保了高效的数据传输和系统稳定性。此外,文档详细描述了芯片的引脚分配、寄存器设置、操作模式、电源序列、时序特性等关键参数,为开发者提供了全面的技术指导。 适合人群:具备一定硬件设计基础,从事嵌入式系统开发、显示技术研究的研发人员。 使用场景及目标:①实现应用处理器与MIPI兼容显示屏之间的高速数据传输;②优化显示系统的功耗表现,减少电磁干扰(EMI);③通过灵活配置不同接口模式来适应各种显示设备的需求。 阅读建议:此文档面向具有一定电子工程背景的专业人士,建议读者结合实际项目需求深入理解各章节内容,特别是关于寄存器配置、时序要求等方面的具体说明。对于初次接触此类技术的开发者而言,建议先熟悉基本概念再逐步掌握高级功能的应用方法。
CSS
61,120
社区成员
60,701
社区内容
发帖
与我相关
我的任务
CSS
层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。
复制链接
扫一扫
分享
社区描述
层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


