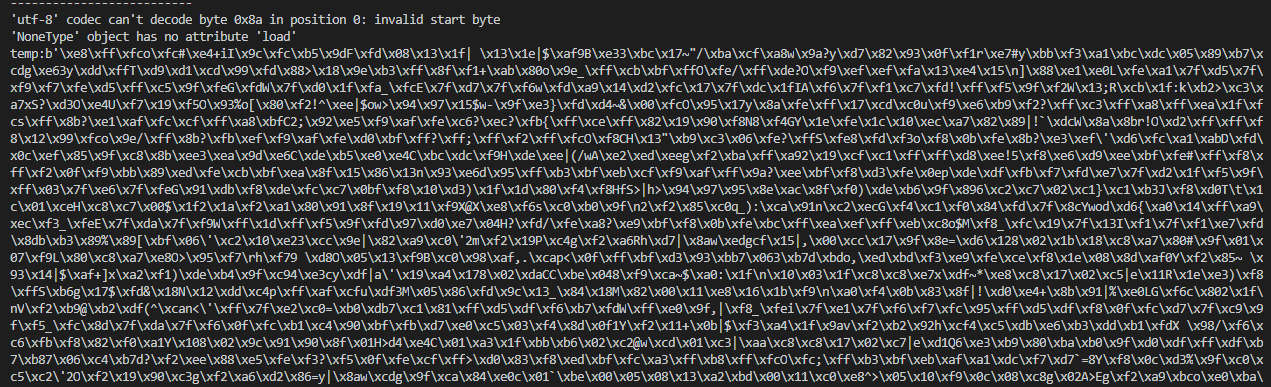
请问我用scapy抓包,好像网页返回的信息不多的时候能正常显示,网页返回的信息一旦多了,就成了下面这样,请问是什么问题?
dpkg = sniff(filter="host 192.168.1.100 and tcp",iface="Intel(R) Ethernet Connection (2) I219-LM",prn=deal,count=0)
def deal(pkt):
try:
temp=(pkt.getlayer(Raw).load)
print("temp:"+str(temp))
......
少的时候会显示{'Id': None, 'Nid': '8C1811D1-E1B8-4E9D-B0E6-EFD913980D65', 'TemplateId': 254, 'InstanceId': 80550, 'ModuleId': 254, 'DataId': '0c50d0bd-6a40-4276-a310-de33c4ed7077', 'Title': '公
司绩效考核审批流程', 'TargetUrl': '/kh_assess.aspx?sid=0c50d0bd-6a40-4276-a310-de33c4ed7077&f=2', 'ModuleName': '专业管理', 'UStatus': '已终止', 'TaskUsers': '', 'TaskUserIds': None, 'NodeName': '提报部门经理审批', 'NodeId': 1402, 'RejectType': 0, 'InstanceCreateTime': '2020-12-15 08:54:22', 'GroupName': '其它调用BPM', 'TotalCount': 4}
都是正常的,多的时候就图片那样
我猜测是不是信息被分成多个包?那么如何组合起来呢?
其实我的根本需求是像浏览器的开发者工具那样,获得网站传过来的response信息,获得其中的json,应该怎么做?



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
