

250
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
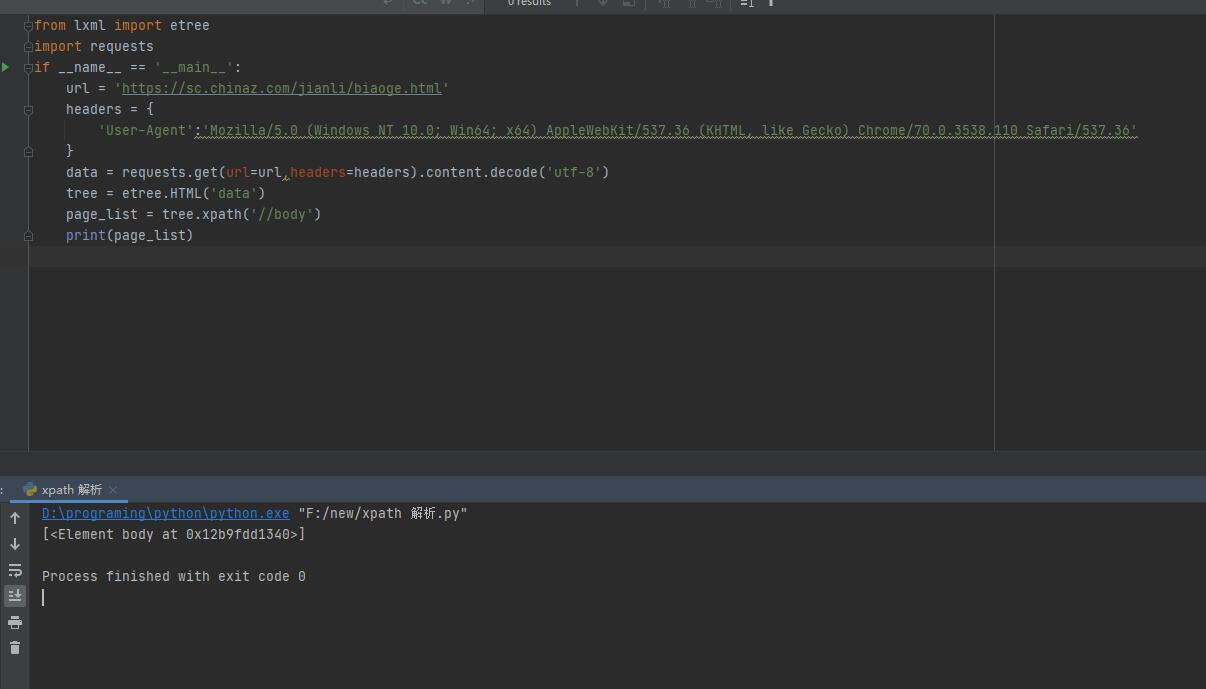
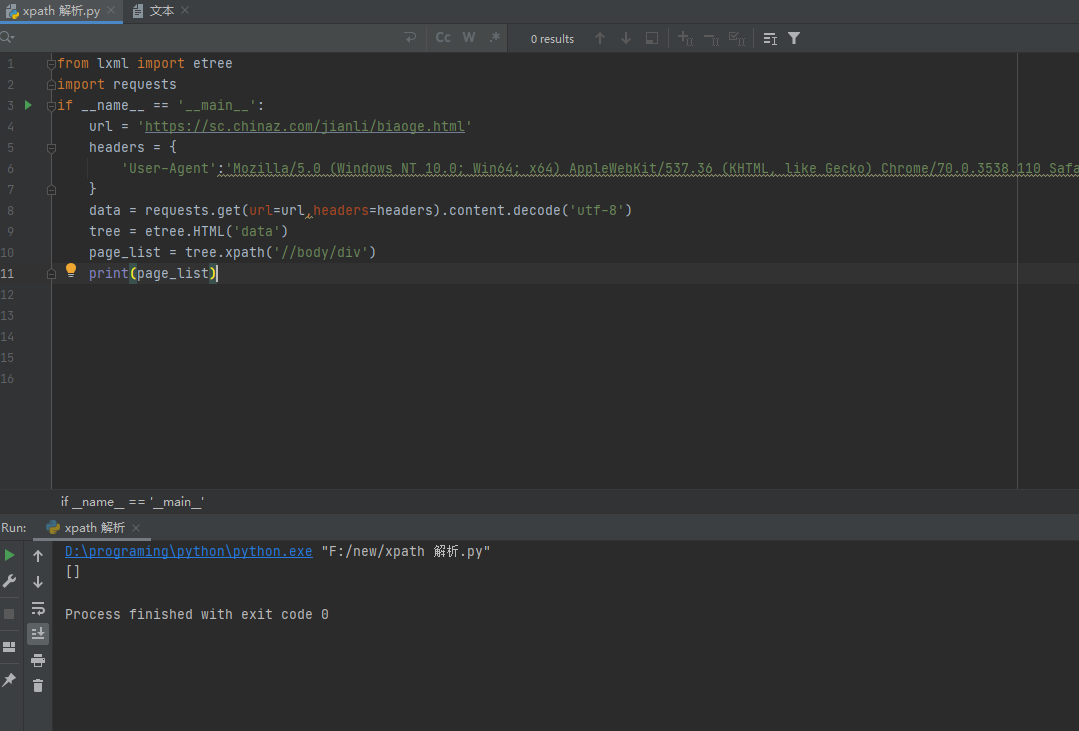
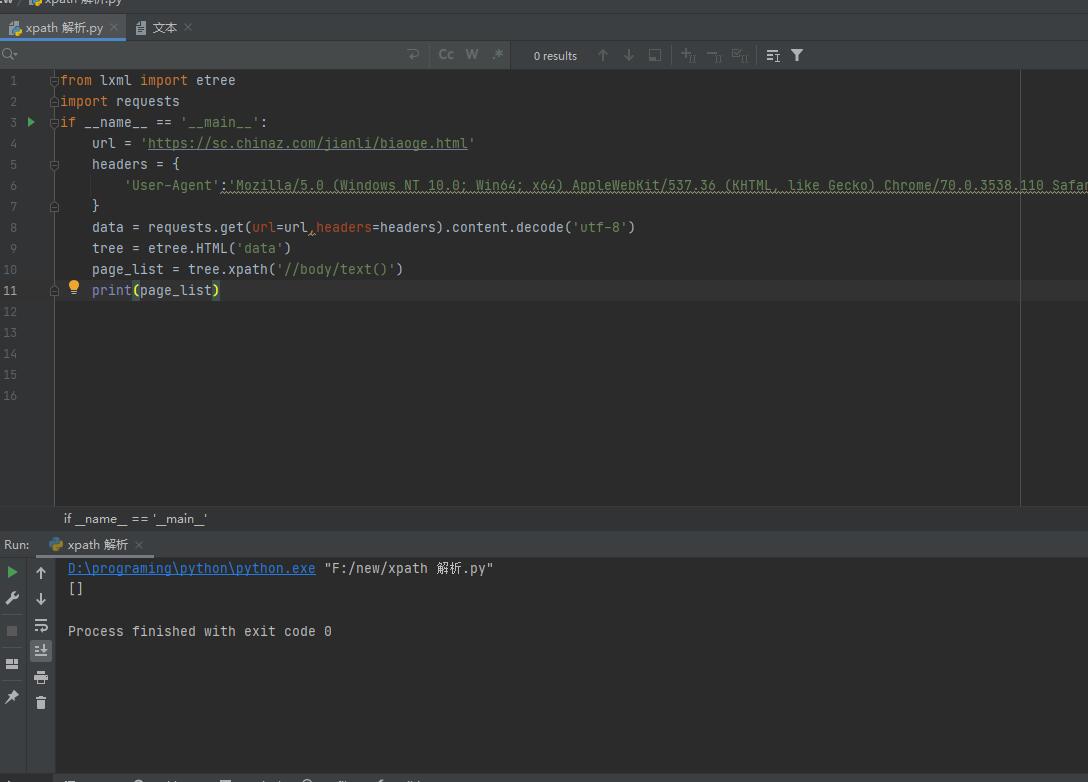
from lxml import etree
import requests
if __name__ == '__main__':
url = 'https://sc.chinaz.com/jianli/biaoge.html'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
data = requests.get(url=url,headers=headers).content.decode('utf-8')
tree = etree.HTML('data')
page_list = tree.xpath('//body/text()')
print(page_list)


