社区
Hadoop生态社区
帖子详情
hadoop排序问题
Embedded宋小平
2021-04-13 08:00:44
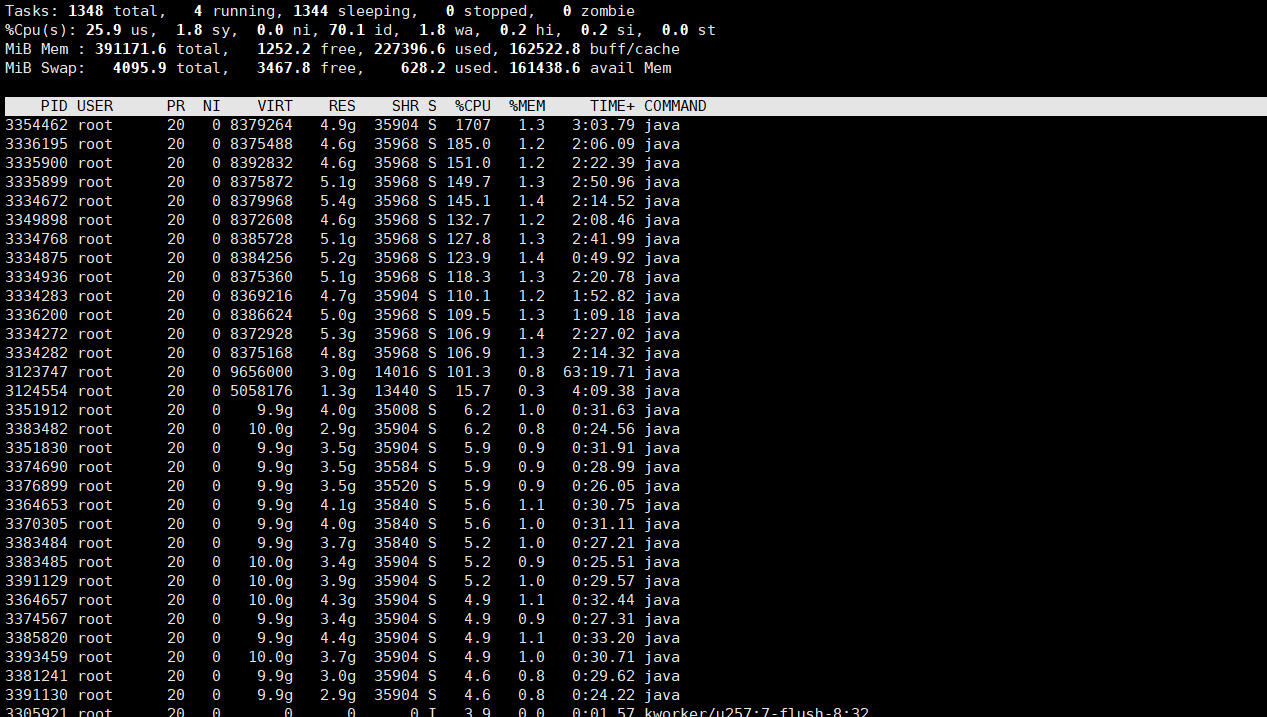
对1T数据量进行排序,在reduce阶段,使用top查看了一下CPU,发现
有部分reduce的CPU基本空闲,感觉不太正常,不是应该忙于拷贝和排序的吗?
求助为什么会出现这种现象。。。。
...全文
1003
2
打赏
收藏
hadoop排序问题
对1T数据量进行排序,在reduce阶段,使用top查看了一下CPU,发现 有部分reduce的CPU基本空闲,感觉不太正常,不是应该忙于拷贝和排序的吗? 求助为什么会出现这种现象。。。。
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
chongchongone
2021-04-25
打赏
举报
回复
可以自定义Partitioner,根据数据的特点,进行自定义分区,会适当调整CPU的合理使用。
不烦人的阙
2021-04-15
打赏
举报
回复
这种是出现数据倾斜
Hadoop
入门和大数据应用
Hadoop
入门和大数据应用视频教程,该课程主要分享
Hadoop
基础及大数据方面的基础知识。 讲师介绍:翟周伟,就职于百度,
Hadoop
技术讲师,专注于
Hadoop
&大数据、数据挖掘、自然语言处理等领域。2009年便开始利用...
hadoop
实现数据
排序
hadoop
实现数据
排序
Hadoop
学习之路(四):
Hadoop
排序
之全
排序
的原理及实现
Hadoop
实现全
排序
一、全
排序
简介二、全
排序
的原理三、准备数据四、全
排序
的实现1.创建Java工程,添加Maven支持2.编写Map类3.编写Reduce类4.编写作业主类5.将代码打包提交到集群6.运行程序五、总结 一、全
排序
简介 ...
hadoop
排序
之二次
排序
默认情况下,在MapReduce中的shuffer阶段会自动进行
排序
,而且是根据key进行
排序
的。但是有时候需要对 Key
排序
的同时再对 Value 进行
排序
,这时候就要用到二次
排序
了。 我们把二次
排序
分为以下几个阶段。 Map输出...
Hadoop
中的各种
排序
可以看到,这本身就是一个二次
排序
。shuffle
排序
综述:如果只定义了map函数,没有定义reduce函数,那么输入数据经过shuffle的
排序
后,结果为key值相同的输出挨在一起,且key值小的一定在前面,这样整体来看key值有序...
Hadoop生态社区
20,808
社区成员
4,690
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


