

22,296
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

CREATE TABLE #T
(ID INT IDENTITY(1,1),
NAME_1 NVARCHAR(10),
NAME_2 NVARCHAR(10))
INSERT INTO #T
SELECT '张三','李四' UNION ALL
SELECT '李四','张三' UNION ALL
SELECT '刘晶','周杰'
SELECT MIN(ID) AS ID,NAME_1,NAME_2
FROM
(SELECT ID,
CASE WHEN NAME_1<NAME_2 THEN NAME_1 ELSE NAME_2 END AS NAME_1,
CASE WHEN NAME_1>NAME_2 THEN NAME_1 ELSE NAME_2 END AS NAME_2
FROM #T) AS A
GROUP BY NAME_1,NAME_2

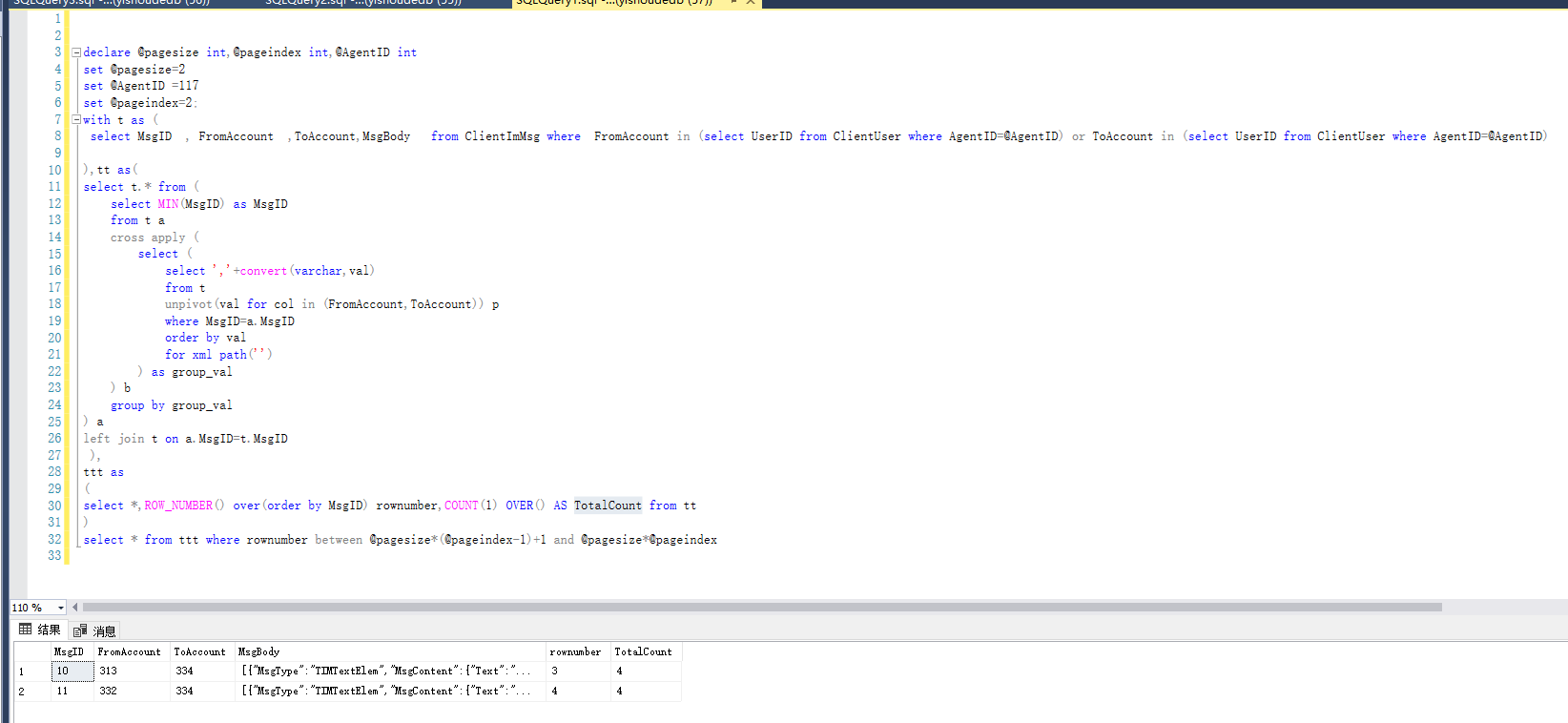
with t as (
select 4 as id,'1' as a,'2' as b
union all select 5,'2','1'
union all select 1,'张三','李四'
union all select 2,'李四','张三'
union all select 3,'刘晶','周杰'
)
select t.* from (
select MIN(id) as id
from t a
cross apply (
select (
select ','+convert(varchar,val)
from t
unpivot(val for col in (a,b)) p
where id=a.id
order by val
for xml path('')
) as group_val
) b
group by group_val
) a
left join t on a.id=t.id
order by t.idwith t as (
select 1 as id,1 as a,2 as b
union all
select 2,2,1
)
select * from t a
cross apply (
select (
select ','+convert(varchar,val)
from t
unpivot(val for col in (a,b)) p
where id=a.id
order by val
for xml path('')
) as group_val
) b

select top 1 * from yourtable

