我用python爬取大麦网的演出信息,采用以下思路:
1、进入 https://search.damai.cn/search.htm?spm=a2oeg.home.top.dcategory.591b23e1ieUFdq&order=1
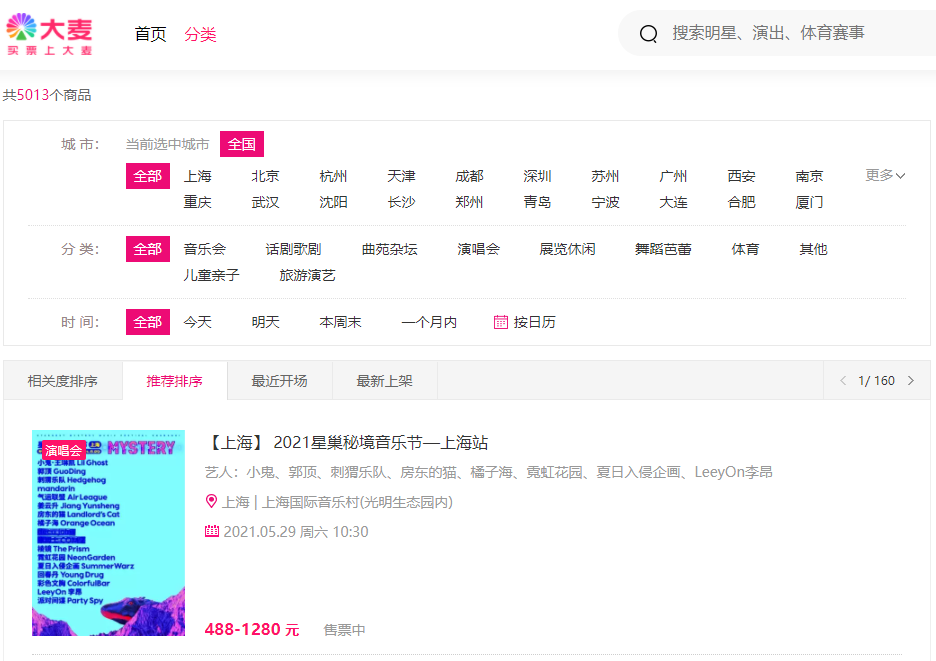
爬取每个单页的20条演出信息;
2、找到往后每一页的连接,重复爬取每页的演出信息
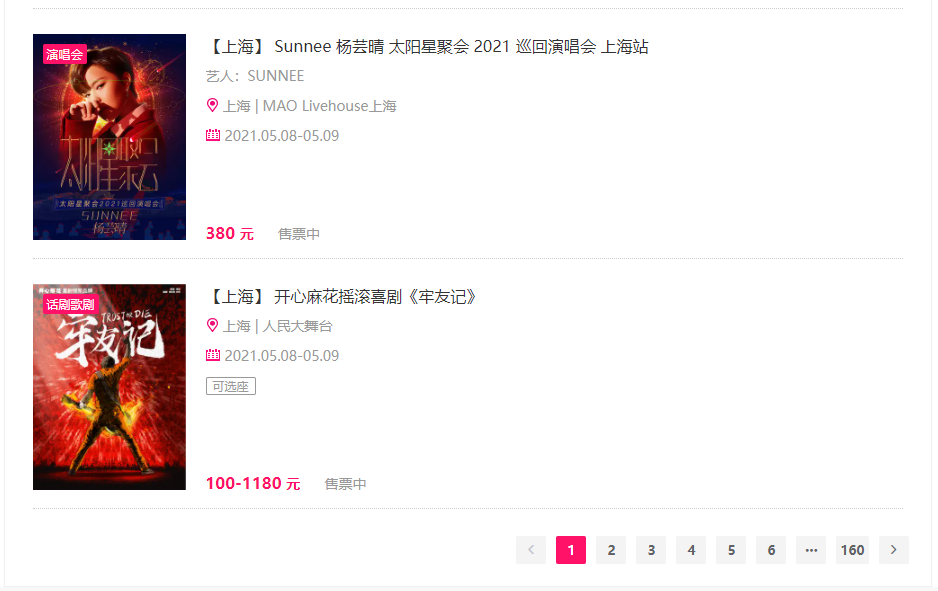
但是进程卡在了这里:
这个下一页网址信息不会改变。用chrome浏览器检查半天也不得其法。
请各位朋友进入大麦网帮我看看,怎样找到下一页的链接信息?或者我的这个爬虫思路有问题,需要改进?






 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享