

81,092
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享--- User1: 士大夫消费 --- -- Mon Nov 23 19:47:20 2020
--- User2: 士大夫 --- -- Mon Nov 23 19:47:20 2020
$: 0, e$: 50000 -- Mon Nov 23 19:47:20 2020
--- User1: 洞洞2 --- -- Sun May 09 15:08:10 2021
--- User2: 女战士 --- -- Sun May 09 15:08:10 2021
[id=58709530], dur=1, max_dur=1, gemhole=[0,0], addtion=[0], antimonster=[0], dec_dmg=[0], add_life=[0] -- Sun May 09 15:08:10 2021
[id=6473413], dur=1, max_dur=1, gemhole=[0,0], addtion=[0], antimonster=[0], dec_dmg=[0], add_life=[0] -- Sun May 09 15:08:10 2021
[id=6470717], dur=1, max_dur=1, gemhole=[0,0], addtion=[0], antimonster=[0], dec_dmg=[0], add_life=[0] -- Sun May 09 15:08:10 2021
[id=6534954], dur=1, max_dur=1, gemhole=[0,0], addtion=[0], antimonster=[0], dec_dmg=[0], add_life=[0] -- Sun May 09 15:08:10 2021
[id=6547606], dur=1, max_dur=1, gemhole=[0,0], addtion=[0], antimonster=[0], dec_dmg=[0], add_life=[0] -- Sun May 09 15:08:10 2021
--- User1: 洞洞2 --- -- Sun May 09 15:18:06 2021
--- User2: 李达康同志 --- -- Sun May 09 15:18:06 2021
[id=5200240], dur=10000, max_dur=10000, gemhole=[13,13], addtion=[0], antimonster=[0], dec_dmg=[1], add_life=[0] -- Sun May 09 15:18:06 2021
[id=1885128], dur=6640, max_dur=7099, gemhole=[13,13], addtion=[8], antimonster=[0], dec_dmg=[0], add_life=[0] -- Sun May 09 15:18:06 2021
[id=58226605], dur=1, max_dur=1, gemhole=[0,0], addtion=[0], antimonster=[0], dec_dmg=[0], add_life=[0] -- Sun May 09 15:18:06 2021
--- User1: 士大夫消费 --- -- Mon Nov 23 19:47:21 2020
--- User2: 士大夫 --- -- Mon Nov 23 19:47:21 2020
$: 0, e$: 50000 -- Mon Nov 23 19:47:20 2021
--- User1: 是佛山 --- -- Sun May 09 15:28:00 2021
[id=5083968], dur=6874, max_dur=7099, gemhole=[13,13], addtion=[8], antimonster=[0], dec_dmg=[3], add_life=[0] -- Sun May 09 15:28:00 2021
--- User2: 洞洞2 --- -- Sun May 09 15:28:00 2021
--- User1: 是佛山 --- -- Sun May 09 15:28:32 2021
--- User2: 洞洞2 --- -- Sun May 09 15:28:32 2021

User1: 士大夫消费 --- -- Mon Nov 23 19:47:20 2020
User2: 士大夫 --- -- Mon Nov 23 19:47:20 2020
$: 0, e$: 50000 -- Mon Nov 23 19:47:20 2020
User1: 洞洞2 --- -- Sun May 09 15:08:10 2021
User2: 女战士 --- -- Sun May 09 15:08:10 2021
User1: 洞洞2 --- -- Sun May 09 15:18:06 2021
User2: 李达康同志 --- -- Sun May 09 15:18:06 2021
User1: 士大夫消费 --- -- Mon Nov 23 19:47:21 2020
User2: 士大夫 --- -- Mon Nov 23 19:47:21 2020
$: 0, e$: 50000 -- Mon Nov 23 19:47:20 2021
User1: 是佛山 --- -- Sun May 09 15:28:00 2021
User2: 洞洞2 --- -- Sun May 09 15:28:00 2021
User1: 是佛山 --- -- Sun May 09 15:28:32 2021
public static List<String> getLines(File target, String[] keys) throws IOException {
List<String> result = new ArrayList<>();
try(BufferedReader reader = new BufferedReader(new FileReader(target))) {
String line = null;
for (int lineNumber = 1; (line=reader.readLine())!=null; lineNumber++) {
for (String key : keys) {
if (line.contains(key)) {
result.add(line);
break;
}
}
}
}
return result;
}
public static void main(String[] args) throws IOException {
final File target = new File("/path/to/file");
final String[] keys = new String[]{"User1", "User2", "e$:", "$:"};
List<String> result = getLines(target, keys);
// 注意,target 文件太大的话,会爆掉内存的。
}


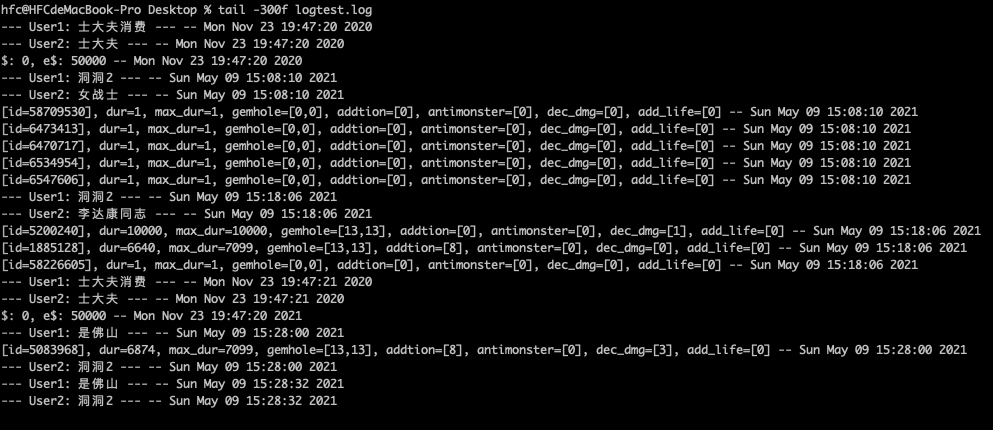 关键词导出子文件
关键词导出子文件
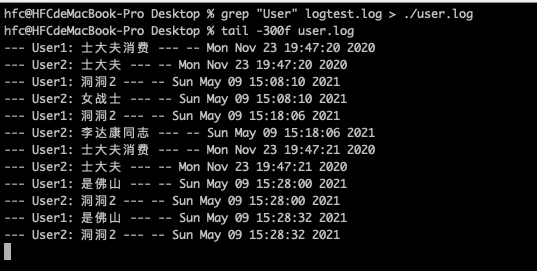 再直接读子文件即可
再直接读子文件即可 那要是有1g 大小,也要一行行判断吗,
这太不科学了吧
那要是有1g 大小,也要一行行判断吗,
这太不科学了吧 
 在线等
在线等