社区
其他开发语言
帖子详情
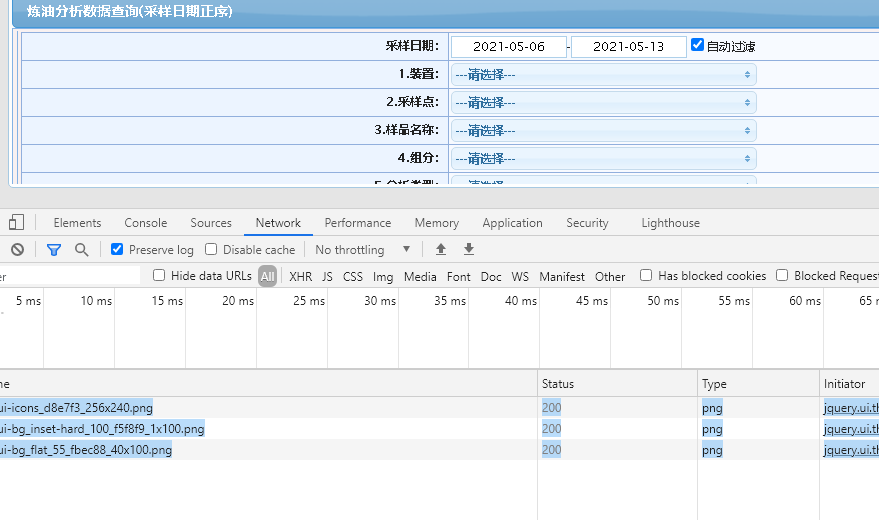
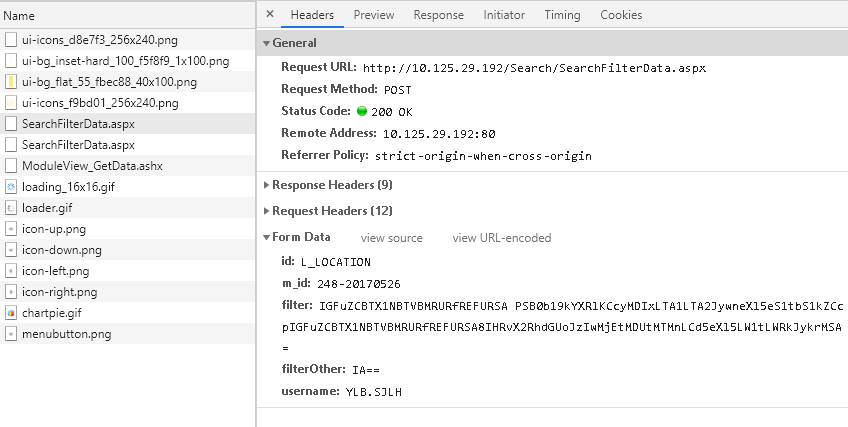
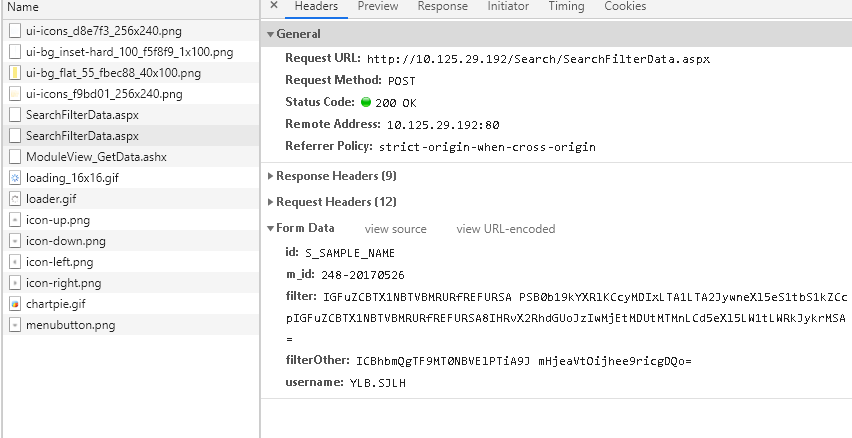
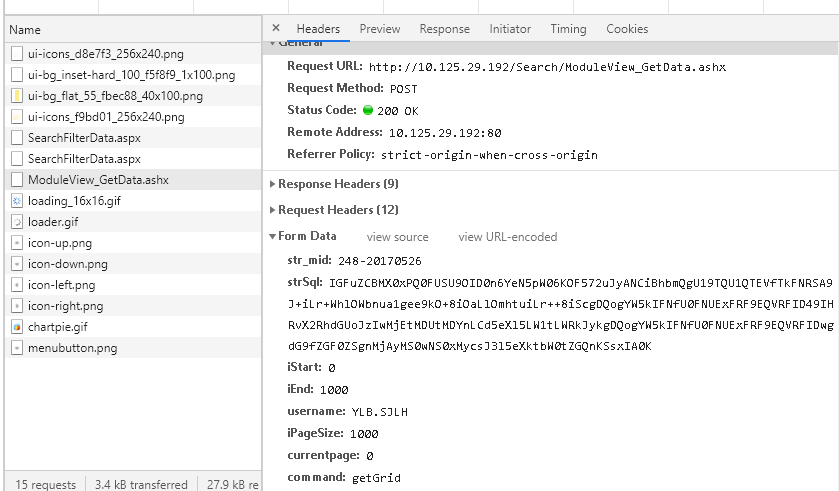
在爬取数据时得到的网页无法获取日期信息
杨雷波
2021-05-10 09:48:05
如题,在爬取公司产品数据时,选择好时间和其他限制条件后,在得到的页面network中,没有找到时间参数,怎么确定不同日期之间的区别
...全文
84
回复
打赏
收藏
在爬取数据时得到的网页无法获取日期信息
如题,在爬取公司产品数据时,选择好时间和其他限制条件后,在得到的页面network中,没有找到时间参数,怎么确定不同日期之间的区别
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
Python爬虫
爬取
马蜂窝旅游景点评分、评论、评论
日期
(针对只能
爬取
五页评论做了改动)
①马蜂窝景点的评论只能看到五页内容,因此按评论的主题对其进行
爬取
(虽然每个主题也只能看到五页,但
爬取
的结果总归是比五页多很多),
爬取
字段有景点评分、评论、评论
日期
。 ②以马蜂窝某景点为例,其评论高达3000多条,但这3000多条并非是完全向用户展示的,向用户展示的只有5页,数了一下每页15条评论,也就是75条评论,有点太少了吧! ③因此想了个办法尽可能多
爬取
一些评论,根据我对爬虫
爬取
数据
法律法规的相关了解,
爬取
看
得到
的
数据
是合法的,而在评论最开始的这个地方有对评论的分类,当然每个分类主题也是最多能看到5页内容,但是肯定会比我们被动的只
爬取
5页多很多内容,因此我们选择按主题分类去
爬取
评论。
长江中游水文
爬取
信息
几年的长江中游水文
数据
信息
,分为多个
时
段,有站点
信息
,水位
信息
,流量
信息
,
日期
信息
等一系列的
信息
的
python 基金
数据
爬取
python 基金
数据
爬取
源码 可运行
Python实现天天基金
数据
爬取
获取
全量基金
信息
(基金代码、基金名、类型...)
获取
基金指定
日期
内单位净值、累计净值、日增长率等
获取
基金指定
日期
内单位净值、累计净值、日增长率等
python爬虫课设,
爬取
51job网站岗位基本
信息
,大学开展python
数据
获取
与预处理的小伙伴们,可以直接拿来用
该课题要求
爬取
目标网站:https://www.51job.com中,输入关键字后工作岗位的基本
信息
如岗位名字、岗位薪资、base地、福利、岗位要求、岗位需求公司、发布
日期
、公司所属行业、公司性质、招聘岗位简介、公司简介等,
爬取
过程中需要注意
网页
反爬机制。 (1)编写代码,模仿浏览器人为操作,通过关键字
爬取
人才网的职位
信息
; (2)将
爬取
到的
网页
信息
进行
信息
预处理、清洗等。 (3)将处理完的
数据
存储在Mysql
数据
库中,
数据
库名为job,或者
数据
存储在名为job的Excel表格或名为job的记事本文件中。 (4)用
数据
可视化处理
数据
,生成岗位在地图上面的热力图、热门地区岗位薪资待遇柱状图、热门地区岗位招聘个数折线图以及以招聘地区出现次数的云图,从而反馈出岗位的热门地区以及薪资待遇。 (5)设计对抓取
数据
的备份还原机制,确保
数据
安全。
其他开发语言
3,423
社区成员
15,635
社区内容
发帖
与我相关
我的任务
其他开发语言
其他开发语言 其他开发语言
复制链接
扫一扫
分享
社区描述
其他开发语言 其他开发语言
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享