

22,296
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
if object_id('tempdb.dbo.#test1') is not null drop table #test1
go
create table #test1([notext] nvarchar(20))
DECLARE @sql NVARCHAR(MAX), @i INT;
SELECT @sql = N'', @i = 119;
WHILE @i > 0
BEGIN
SET @sql = N'BULK INSERT #test1 FROM ''E:\LOTTData\hellome\' + CONVERT(VARCHAR(2), @i)
+ N'.txt'' WITH
(
FIELDTERMINATOR ='' '',
ROWTERMINATOR = ''\n''
)' ;
PRINT @sql;
EXEC (@sql);
SET @i = @i - 1;
END;


--- 先导入 #t
if object_id('tempdb.dbo.#t') is not null drop table #t
go
create table #t ([notext] nvarchar(20)) ----- 先导入 #t
DECLARE @sql NVARCHAR(MAX), @i INT;
SELECT @sql = N'', @i = 147;
WHILE @i > 0
BEGIN
SET @sql = N'BULK INSERT #test1 FROM ''E:\LOTTData\hellome\' + CONVERT(VARCHAR(2), @i)
+ N'.txt'' WITH
(
FIELDTERMINATOR ='' '',
ROWTERMINATOR = ''\n''
)' ;
PRINT @sql;
EXEC (@sql);
SET @i = @i - 1;
END;
--- 再替换处理
;WITH CTE_1
AS
(SELECT *,ROW_NUMBER() OVER (ORDER BY (SELECT 1)) AS RN,REPLACE(REPLACE(Note,', ',','),' ',',') AS NOTE_NEW FROM #T),
CTE_2
AS
(SELECT A.*,B.NUMBER,RIGHT('0'+SUBSTRING(NOTE_NEW,number,CHARINDEX(',',NOTE_NEW+',',NUMBER)-NUMBER),2) AS SINGLE_CHAR
FROM CTE_1 A
JOIN master.dbo.spt_values B ON number=CHARINDEX(',',','+NOTE_NEW,NUMBER)
WHERE TYPE='P')
SELECT RN,STUFF((SELECT ' '+SINGLE_CHAR FROM CTE_2 WHERE RN=A.RN ORDER BY number FOR XML PATH('')),1,1,'') AS NOTE_FINAL
FROM CTE_2 AS A
GROUP BY RN




declare @n varchar(max)
set @n = '1,4,11,23,32,55
3 5 11 12 21 27
11,15,21,23,27,39
1,2,3,4,5,9
3,5,11,12,21,27
11 15 21 23 27 39
1 2 3 4 5 39
22 24 25 29 31 32
1 4 11 23 32 55'
select distinct *,master.dbo.regexreplace('0'+no1+' 0'+no2+' 0'+no3+' 0'+no4+' 0'+no5+' 0'+no6,'\d*(\d{2})(?!\d)','$1')
from (
select [1] as no1,[2] as no2,[3] as no3,[4] as no4,[5] as no5,[6] as no6
from (
select sn,convert(varchar(3),match) as match,[group] as grp
from master.dbo.regexmatcheswithgroup(@n,'(\d+)[^\d\r\n]+(\d+)[^\d\r\n]+(\d+)[^\d\r\n]+(\d+)[^\d\r\n]+(\d+)[^\d\r\n]+(\d+)') a
) a
pivot(max(match) for grp in ([0],[1],[2],[3],[4],[5],[6])) p
) a
no1 no2 no3 no4 no5 no6
---- ---- ---- ---- ---- ---- -------------------------------------------------------------
1 2 3 4 5 39 01 02 03 04 05 39
1 2 3 4 5 9 01 02 03 04 05 09
1 4 11 23 32 55 01 04 11 23 32 55
11 15 21 23 27 39 11 15 21 23 27 39
22 24 25 29 31 32 22 24 25 29 31 32
3 5 11 12 21 27 03 05 11 12 21 27
(6 行受影响)

CREATE TABLE #T (Note NVARCHAR(MAX))
INSERT #T VALUES
('1, 4, 11, 23, 32, 55'),('3 5 11 12 21 27'),('11,15,21,23,27,39'),
('1,2,3,4,5,9'),('3,5,11,12,21,27'),('11 15 21 23 27 39'),
('1 2 3 4 5 39'),('22 24 25 29 31 32'),('1 4 11 23 32 55')
WITH CTE_1
AS
(SELECT *,ROW_NUMBER() OVER (ORDER BY (SELECT 1)) AS RN,REPLACE(REPLACE(Note,', ',','),' ',',') AS NOTE_NEW FROM #T),
CTE_2
AS
(SELECT A.*,B.NUMBER,RIGHT('0'+SUBSTRING(NOTE_NEW,number,CHARINDEX(',',NOTE_NEW+',',NUMBER)-NUMBER),2) AS SINGLE_CHAR
FROM CTE_1 A
JOIN master.dbo.spt_values B ON number=CHARINDEX(',',','+NOTE_NEW,NUMBER)
WHERE TYPE='P')
SELECT RN,STUFF((SELECT ' '+SINGLE_CHAR FROM CTE_2 WHERE RN=A.RN ORDER BY number FOR XML PATH('')),1,1,'') AS NOTE_FINAL
FROM CTE_2 AS A
GROUP BY RN
--去掉重复项
SELECT DISTINCT STUFF(S.NewNote,1,1,'') AS NewNote
FROM @t t
OUTER APPLY ( SELECT CASE WHEN LEN(newNote.value) = 1 THEN ' 0' + newNote.value
ELSE ' ' + newNote.value
END
FROM STRING_SPLIT(REPLACE(REPLACE(note, ',', ' '), ',', ' '), ' ') AS newNote
FOR XML PATH('')) S(NewNote);
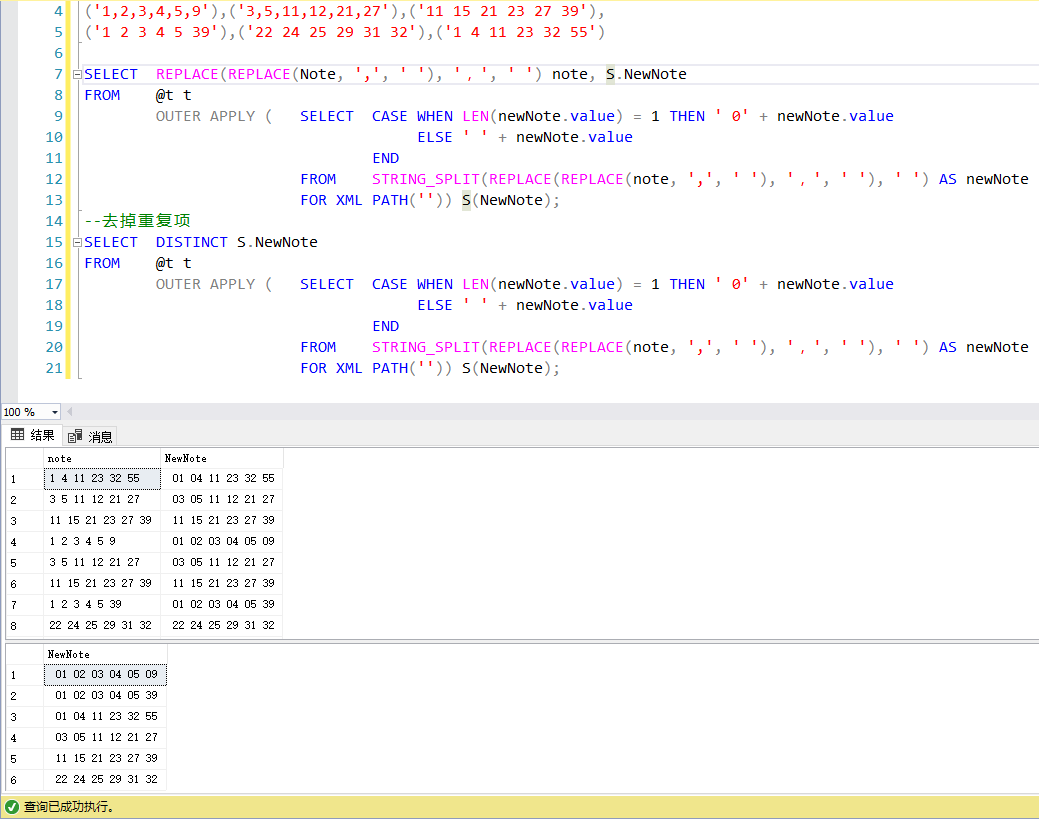
DECLARE @t TABLE(Note NVARCHAR(MAX))
INSERT @t (Note) VALUES
('1,4,11,23,32,55'),('3 5 11 12 21 27'),('11,15,21,23,27,39'),
('1,2,3,4,5,9'),('3,5,11,12,21,27'),('11 15 21 23 27 39'),
('1 2 3 4 5 39'),('22 24 25 29 31 32'),('1 4 11 23 32 55')
SELECT REPLACE(REPLACE(Note, ',', ' '), ',', ' ') note, S.NewNote
FROM @t t
OUTER APPLY ( SELECT CASE WHEN LEN(newNote.value) = 1 THEN ' 0' + newNote.value
ELSE ' ' + newNote.value
END
FROM STRING_SPLIT(REPLACE(REPLACE(note, ',', ' '), ',', ' '), ' ') AS newNote
FOR XML PATH('')) S(NewNote);
--去掉重复项
SELECT DISTINCT S.NewNote
FROM @t t
OUTER APPLY ( SELECT CASE WHEN LEN(newNote.value) = 1 THEN ' 0' + newNote.value
ELSE ' ' + newNote.value
END
FROM STRING_SPLIT(REPLACE(REPLACE(note, ',', ' '), ',', ' '), ' ') AS newNote
FOR XML PATH('')) S(NewNote);
create function f_split(@SourceSql varchar(8000),@StrSeprate varchar(10))
returns @temp table(a varchar(100))
--实现split功能 的函数
--date :2018-5-14
as
begin
declare @i int
set @SourceSql=rtrim(ltrim(@SourceSql))
set @i=charindex(@StrSeprate,@SourceSql)
while @i>=1
begin
insert @temp values(left(@SourceSql,@i-1))
set @SourceSql=substring(@SourceSql,@i+1,len(@SourceSql)-@i)
set @i=charindex(@StrSeprate,@SourceSql)
end
if @SourceSql<>''
insert @temp values(@SourceSql)
return
end
