

22,209
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

with t as (
select *,'t1' as tb from #a
union all
select *,'t2' as tb from #b
union all
select *,'t3' as tb from #c
)
select * from (
select match,tb,dense_rank() over(order by match,rid) as rnk
from (
select *,ROW_NUMBER() over(partition by match,tb order by @@rowcount) as rid from t
) a
) a
pivot(max(match) for tb in (t1,t2,t3)) p

SELECT * FROM (
SELECT A.ID,ROW_NUMBER() OVER(PARTITION BY A.ID ORDER BY (SELECT 1)) RN FROM #A A) A1 FULL JOIN (
SELECT A.ID,ROW_NUMBER() OVER(PARTITION BY A.ID ORDER BY (SELECT 1)) RN FROM #B A) B1 ON A1.ID = B1.ID AND A1.RN = B1.RN FULL JOIN(
SELECT A.ID,ROW_NUMBER() OVER(PARTITION BY A.ID ORDER BY (SELECT 1)) RN FROM #C A) C1 ON
(C1.ID = B1.ID AND C1.RN = B1.RN) OR (C1.ID = A1.ID AND C1.RN = A1.RN)
ORDER BY COALESCE(A1.ID,B1.ID,C1.ID)
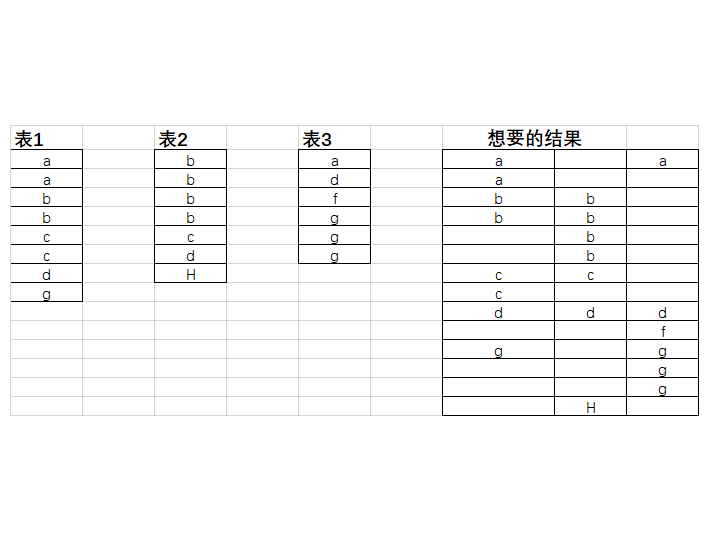
CREATE TABLE #A(
ID VARCHAR(2)
)
CREATE TABLE #B(
ID VARCHAR(2)
)
CREATE TABLE #C(
ID VARCHAR(2)
)
INSERT INTO #A VALUES ('A'),('A'),('B'),('B'),('C'),('C'),('D'),('G')
INSERT INTO #B VALUES ('B'),('B'),('B'),('B'),('C'),('D'),('H')
INSERT INTO #C VALUES ('A'),('D'),('F'),('G'),('G'),('G')
SELECT A,B,ID FROM (
SELECT A1.ID A,A1.RN,B1.ID B FROM (
SELECT A.ID,ROW_NUMBER() OVER(PARTITION BY A.ID ORDER BY (SELECT 1)) RN FROM #A A) A1
FULL JOIN (
SELECT A.ID,ROW_NUMBER() OVER(PARTITION BY A.ID ORDER BY (SELECT 1)) RN FROM #B A) B1 ON A1.ID = B1.ID AND A1.RN = B1.RN ) A2
FULL JOIN(
SELECT A.ID,ROW_NUMBER() OVER(PARTITION BY A.ID ORDER BY (SELECT 1)) RN FROM #C A) C1 ON A2.A = C1.ID AND A2.RN = C1.RN
ORDER BY COALESCE(A,B,ID)
DROP TABLE #A,#B,#C

