


259
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享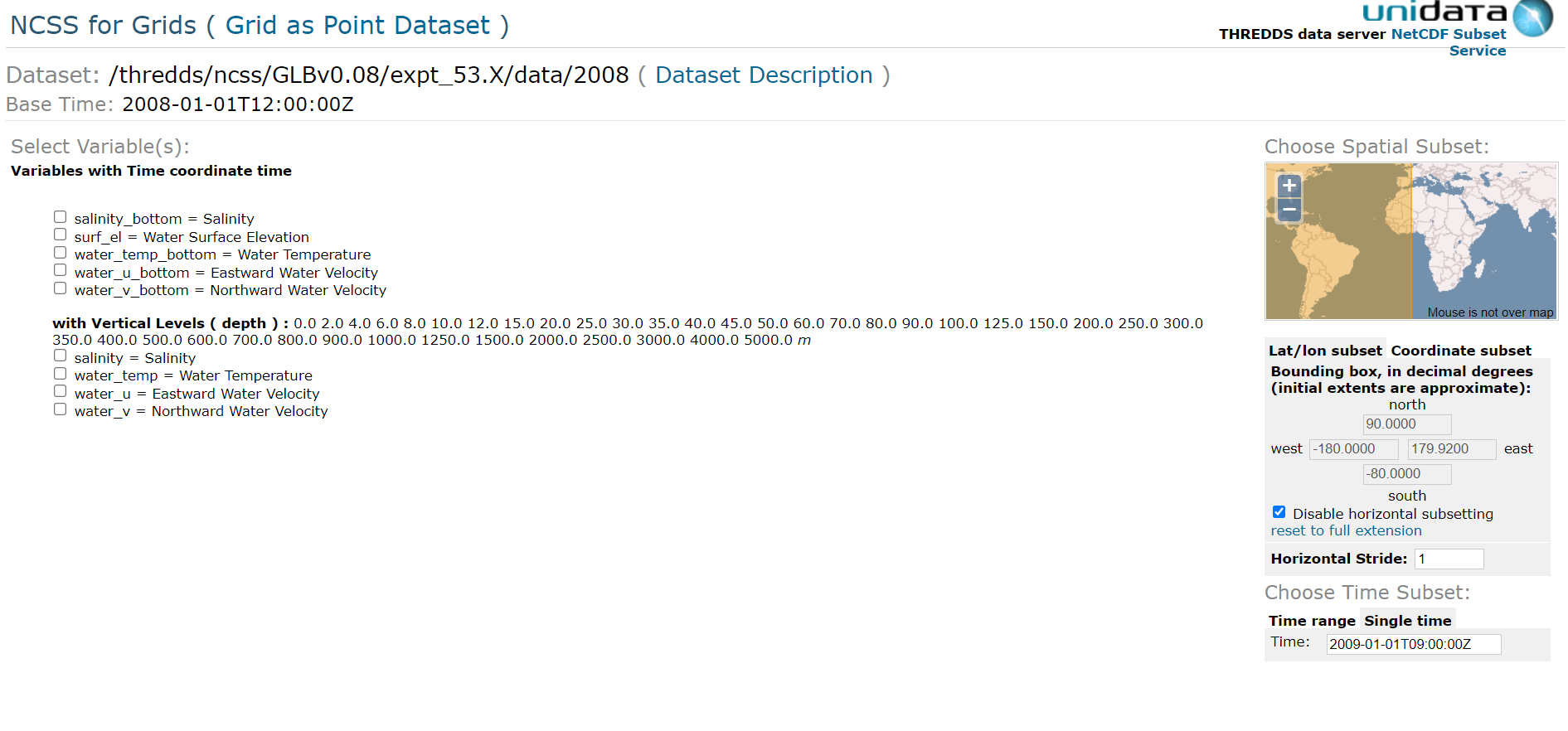

driver = webdriver.Chrome('D:\\chromedriver\\chromedriver.exe') # Optional argument, if not specified will search path.
driver.get('http://ncss.hycom.org/thredds/ncss/grid/GLBv0.08/expt_53.X/data/2008/dataset.html')
driver.implicitly_wait(20)# click ele
driver.find_element_by_xpath('//*[@id="form"]/table/tbody/tr[1]/td[1]/blockquote/input[2]').click()
# click S,T,U,V
driver.find_element_by_xpath('//*[@id="form"]/table/tbody/tr[1]/td[1]/blockquote/input[6]').click()
driver.find_element_by_xpath('//*[@id="form"]/table/tbody/tr[1]/td[1]/blockquote/input[7]').click()
driver.find_element_by_xpath('//*[@id="form"]/table/tbody/tr[1]/td[1]/blockquote/input[8]').click()
driver.find_element_by_xpath('//*[@id="form"]/table/tbody/tr[1]/td[1]/blockquote/input[9]').click()
driver.implicitly_wait(5)
# click Disable horizontal subsetting
driver.find_element_by_xpath('//*[@id="disableLLSubset"]').click()
# input lat,lon
driver.find_element_by_xpath('//*[@id="latlonSubset"]/div[1]/input[1]').clear()
driver.find_element_by_xpath('//*[@id="latlonSubset"]/div[1]/input[1]').send_keys('18')
driver.find_element_by_xpath('//*[@id="latlonSubset"]/div[2]/input[1]').clear()
driver.find_element_by_xpath('//*[@id="latlonSubset"]/div[2]/input[1]').send_keys('105')
driver.find_element_by_xpath('//*[@id="latlonSubset"]/div[2]/input[3]').clear()
driver.find_element_by_xpath('//*[@id="latlonSubset"]/div[2]/input[3]').send_keys('115')
driver.find_element_by_xpath('//*[@id="latlonSubset"]/div[3]/input[1]').clear()
driver.find_element_by_xpath('//*[@id="latlonSubset"]/div[3]/input[1]').send_keys('9')
driver.implicitly_wait(1)
# click vertical stride
driver.find_element_by_xpath('//*[@id="inputVerticalStride"]/span').click()
driver.implicitly_wait(1)
#click to add lon/lat variables
driver.find_element_by_xpath('//*[@id="form"]/table/tbody/tr[1]/td[2]/div[12]/input').click()
# choose output format
s = driver.find_element_by_name('accept')
Select(s).select_by_value('netcdf')# click single time ,and input data_time
n = 0
for i in range(1, 31):
n = n+1
N = str(i).zfill(2)
keys = '2008-01-' + N + 'T12:00:00Z'
print(keys)
driver.find_element_by_xpath('//*[@id="singleTimeSubset"]/input').clear()
driver.find_element_by_xpath('//*[@id="singleTimeSubset"]/input').send_keys(keys)
driver.implicitly_wait(10)
# click to submit
driver.find_element_by_xpath('//*[@id="form"]/table/tbody/tr[3]/td/input[1]').click()
time.sleep(120)

