



7,343
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本教程的目的是带领大家学会,根据译文片段预测翻译作者
本次用到的数据集是三个 txt 文本,分别是 cowper.txt、derby.txt、butler.txt ,该文本已经经过一些预处理,去除了表头,页眉等
接下来我们加载数据,这里我们使用 tf.data.TextLineDataset API,而不是之前使用的 text_dataset_from_directory,两者的区别是,前者加载 txt 文件里的每一行作为一个样本,后者是加载整个 txt 文件作为一个样本
DIRECTORY_URL = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/' FILE_NAMES = ['cowper.txt', 'derby.txt', 'butler.txt'] for name in FILE_NAMES: text_dir = utils.get_file(name, origin=DIRECTORY_URL + name) parent_dir = pathlib.Path(text_dir).parent list(parent_dir.iterdir()) def labeler(example, index): return example, tf.cast(index, tf.int64) labeled_data_sets = [] for i, file_name in enumerate(FILE_NAMES): lines_dataset = tf.data.TextLineDataset(str(parent_dir/file_name)) labeled_dataset = lines_dataset.map(lambda ex: labeler(ex, i)) labeled_data_sets.append(labeled_dataset)
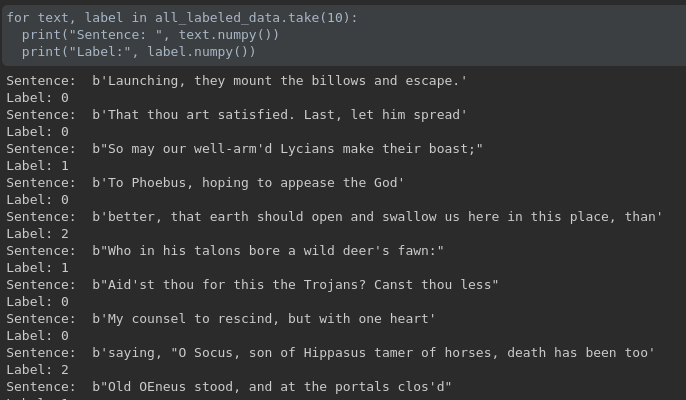
如上图所示,我们可以看到,txt 文件里的每一行确实是一个样本,其实上面的数据已经经过进一步处理了,变成 (example, label) pair 了
接下来我们需要对文本进行 standardize and tokenize,然后再使用 StaticVocabularyTable,建立 tokens 到 integers 的映射
这里我们使用 UnicodeScriptTokenizer 来 tokenize 数据集,代码如下所示
tokenizer = tf_text.UnicodeScriptTokenizer() def tokenize(text, unused_label): lower_case = tf_text.case_fold_utf8(text) return tokenizer.tokenize(lower_case) tokenized_ds = all_labeled_data.map(tokenize)
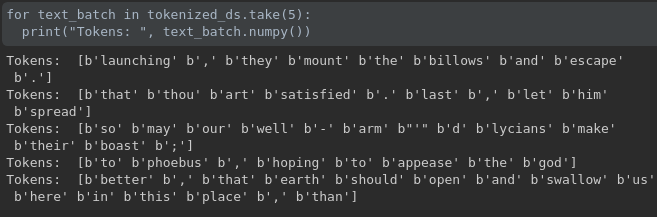
上图是 tokenize 的结果展示
下一步,我们需要建立 vocabulary,根据 tokens 的频率做一个排序,并取排名靠前的 VOCAB_SIZE 个元素
tokenized_ds = configure_dataset(tokenized_ds)
vocab_dict = collections.defaultdict(lambda: 0)
for toks in tokenized_ds.as_numpy_iterator():
for tok in toks:
vocab_dict[tok] += 1
vocab = sorted(vocab_dict.items(), key=lambda x: x[1], reverse=True)
vocab = [token for token, count in vocab]
vocab = vocab[:VOCAB_SIZE]
vocab_size = len(vocab)
print("Vocab size: ", vocab_size)
print("First five vocab entries:", vocab[:5])
接下来,我们需要用 vocab 创建 StaticVocabularyTable,因为 0 被保留用于表明 padding,1 被保留用于表明 OOV token,所以我们的实际 map tokens 的integer 是 [2, vocab_size+2],代码如下所示
keys = vocab values = range(2, len(vocab) + 2) # reserve 0 for padding, 1 for OOV init = tf.lookup.KeyValueTensorInitializer( keys, values, key_dtype=tf.string, value_dtype=tf.int64) num_oov_buckets = 1 vocab_table = tf.lookup.StaticVocabularyTable(init, num_oov_buckets)
最后我们要封装一个函数用于 standardize, tokenize and vectorize 数据集,通过 tokenizer and lookup table
def preprocess_text(text, label): standardized = tf_text.case_fold_utf8(text) tokenized = tokenizer.tokenize(standardized) vectorized = vocab_table.lookup(tokenized) return vectorized, label
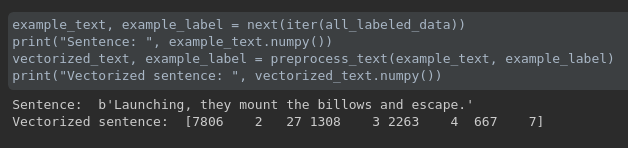
上图是关于把 raw text 转化成 tokens 的展示结果
接下来,我们需要对数据集进行划分,然后再创建模型,最后就可以开始训练了,代码如下所示
all_encoded_data = all_labeled_data.map(preprocess_text) train_data = all_encoded_data.skip(VALIDATION_SIZE).shuffle(BUFFER_SIZE) validation_data = all_encoded_data.take(VALIDATION_SIZE) train_data = train_data.padded_batch(BATCH_SIZE) validation_data = validation_data.padded_batch(BATCH_SIZE) vocab_size += 2 train_data = configure_dataset(train_data) validation_data = configure_dataset(validation_data) model = create_model(vocab_size=vocab_size, num_labels=3) model.compile( optimizer='adam', loss=losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) history = model.fit(train_data, validation_data=validation_data, epochs=3)
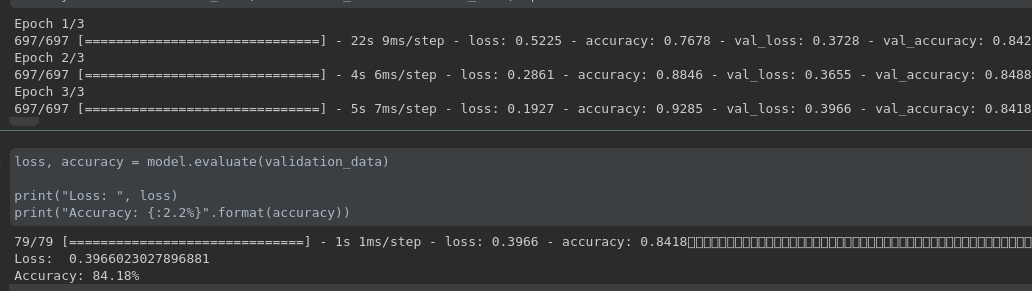
上图是训练的结果展示,在验证集上的准确率达到了 84.18%
inputs = [
"Join'd to th' Ionians with their flowing robes,", # Label: 1
"the allies, and his armour flashed about him so that he seemed to all", # Label: 2
"And with loud clangor of his arms he fell.", # Label: 0
]
predicted_scores = export_model.predict(inputs)
predicted_labels = tf.argmax(predicted_scores, axis=1)
for input, label in zip(inputs, predicted_labels):
print("Question: ", input)
print("Predicted label: ", label.numpy())
最后我们用训练后的模型进行预测,结果如下图所示

预测结果和实际标签都对应上了


