




75
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享我们来回顾一下思科曾经的删库事件:
1.思科被删的 456 台虚拟机
一顿操作猛如虎,IT 人似乎听到 rm -rf /* 的怒吼:还有谁?!
2018 年 9 月,从思科离职 5 个月的 Sudhish Kasaba Ramesh,将魔爪伸向了他曾使用的个人Google Cloud Project 账户,并使出了一招葵花宝典式的口诀 “rm -rf /*,将 WebEx Teams 视频会议和协作应用软件的 456 个虚拟机删除了。
Ramesh 当庭承认,自己恶意删除老东家的虚机时,已经意识到可能会给思科带来严重的后果。这离他在新东家(AIgorithms Platform)任职刚好也是 4 个月,按中国大多数企业的做法,他刚过了试用期。
那么,Ramesh 是何方妖孽,非要拉上老东家上演“农夫与蛇”的故事。
从其个人账号可以知晓,Ramesh 本科毕业于印度的 VELLORE INSTITUTE OF TECHNOLOGY(韦洛尔技术大学)的电子与通信工程专业,硕士毕业于 UC Santa Barbara(加利福尼亚大学圣塔芭芭拉分校)的电子和计算机工程专业。
Ramesh是个喜欢跳槽的人,从 2009 年 5 月开始,在长达 11 年的职业生涯中,Ramesh 先后在 AT&S、ABB、MIPG Lab、NOKIA、UC Santa Barbara、Qualcomm、Oracle、CISCO、Stitch Fix 等公司和机构任职,平均下来每家雇主 Ramesh 只停留了 14 个月。
日防夜防家贼难防。对于思科来说,前雇员利用曾经的个人 Google Cloud Project 账户部署代码删除虚机,有两个可能:一是 Ramesh 是个“大内高手”,进入前东家系统如入无人之境;二是思科相关的安全权限存在漏洞,或者后门。
无论哪种可能,综合近年来诸如“荷兰云主机服务商 Verelox 被前员工删除所有客户数据”、“微盟运维研发中心核心人员删库”、“腾讯云运维人员操作失误导致硬盘故障,创业公司前沿数控技术的数据完全丢失”等严重生产安全事件,都是让人唏嘘不已。
那么,有没有可以防止此类事件再次发生的安全措施?
有,但是不够重视。因为安全事故的发生,是一个小概率的事,可是一旦发生在你头上,就是 100%。
另外,安全事故的小概率也让人产生一种侥幸心理。这有点像中国男人过七夕节,本来花 1 千块买礼物可以解决的事情,最后不得不花 1 万块来摆平女生没收到礼物所带来的损失。
回到事件本身,思科 456 个虚拟机被删,导致的严重后果就是:超过 16000 个 WebEx Teams 账户被异常关闭,持续时间达两个星期,共计损失 240 万美元,其中包括对问题进行修复所支付的约 140 万美元人力成本和超过 100 万美元的客户退款损失。
Two Weeks,Are You Kidding Me?
没错,按照中国 IT 人的“被监管”思维,特别是金融行业,哪怕 2 分钟的停机,可能就是一次重大的安全生产事故,处罚肯定逃不了。
但在美国,因为没有行业监管的硬性要求和处罚规定,所以很多用户的关键系统不一定要做高可用保护。这也就能解释,为什么思科被删的 456 个虚拟机所承载的 WebEx Teams 系统账号,需要花费两周的时间来恢复。
其实,很多人也会问,既然业务系统部署在 AWS 云上,云平台本身没有高可用保护吗?
有,但是需要花钱。我们不妨先来看看用户业务部署在本地和云平台的真实 IT 场景:
如果用户的业务系统部署在本地机房,可以通过双机双柜的双活或一主一备的方式,保障应用系统的高可用容灾,当然系统的访问权限也更加安全,但是运维成本高。
如果用户的业务系统部署在公有云,一般情况下,用户会比较信任云平台的安全性,所以往往只会购买业务所需的 CPU、存储、网络等云资源,对于针对业务系统的高可用所需的云资源,则存在侥幸心理,并且现有的云平台,高可用方案的部署,并没有得到广大云租户那么重视。
2.用户如何保护虚机系统
思科这次的惨痛教训,其实也给云租户提了个醒,如何在虚拟化环境下更好地保护自己的系统和数据?
不要将所有鸡蛋放在一个篮子,这是老生常谈的话题。以虚拟机保护为例,在云端部署一套应用系统,则需要在其他品牌的云平台或本地的生产中心也部署一套备用系统。这样当云平台的虚拟机被删后,可以快速在其他平台拉起备用虚拟机继续向外提供服务。
这个过程是怎样的呢?首先,我们还是先了解虚拟机的致命弱点。
众所周知,虚拟机是从物理机虚拟出来的。根据物理机性能配置的不同,每台物理机能虚拟的虚拟机数量是不同的,假设我们认为一台物理机平均虚拟出 3 台虚拟机,那么 10 台物理机就可以虚拟出 30 台虚拟机,然后通过池化技术,将这 30 台虚拟机构建成一个私有云平台。
那么,跑在私有云平台的 30 台虚拟机,存在 2 个致命弱点:
一是平台型故障的发生,比如说 10 台物理机有部分宕机了,或机房断电了,那这个虚拟化平台就可能无法正常运转了;
二是虚拟机本身出现大面积故障,比如按比例有 20% 的虚拟机出现宕机,但是没有备用主机提供高可用切换,那么这个私有云平台也同样会掉链子。
其实,现有的技术可以解决虚拟机容灾备份的难题,只是不同的方案,在故障转移的过程中,运维工作量、风险系数和业务恢复的 RTO 不尽相同而已。
比如,同样是对虚拟机的备份,有些是需要在每台虚拟机上安装代理 Agent 程序,有些则只需要在虚拟化平台上安装控制平台即可。假如用户有上千台虚拟机,前者就是一个浩大的人力工程。再比如,同样是虚拟机容灾接管的,有些是接到告警信息后,人工进行手动操作,将备用机拉起的,有些是自动根据应用进程、CPU、存储、网络等设置的阈值情况进行自动化切换的。
一个真实的例子是:同样是虚拟机切换,有些备份策略是虚拟机完全宕机无法提供服务后,才会进行高可用切换;但有些备份策略就可以判断虚拟机在进程缓慢时,或处于快要宕机的时候,就进行了自动切换。
对于前者,可能会带来一个严重的后果:如果虚拟机一直半死不活,那就永远切换不过去,但是系统对外服务的性能会受到影响,并最终可能导致终端用户无法使用某些功能。
3.虚机恢复和可用性验证的方案
相比国外,因为有行业监管的要求,所以中国虚拟机灾备场景更加丰富。例如,以下面的应用场景来说,如果要实现灾备中心虚拟机的恢复,有两种方案:
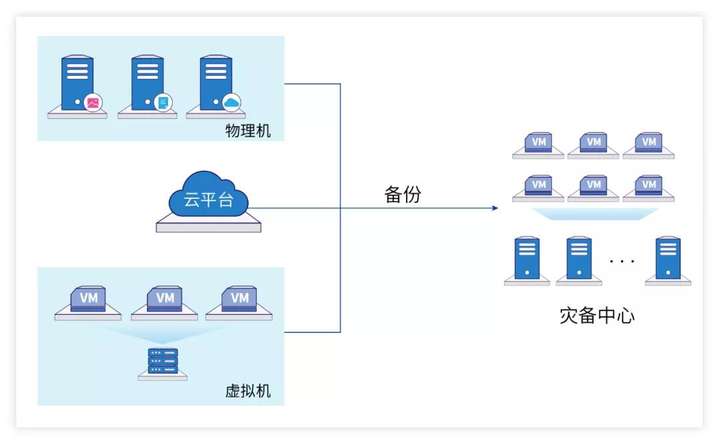
△异构平台系统备份
一种是虚拟机备份文件,通过网络将虚拟机文件恢复到存储平台,这时恢复的时间取决于虚拟机文件的大小和网络带宽,一般情况下,文件越大,时间越长,耗时不可控制。
另外一种是虚拟机备份文件,通过存储挂载(NFS)的形式,直接将备份文件挂载在虚拟化平台上进行瞬时恢复,挂载过程可秒级完成。
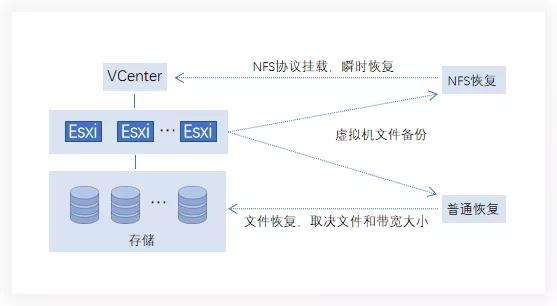
△虚拟机两种恢复方法
此外,为了验证备份系统的可用性,根据行业监管的要求,用户需要针对虚拟化平台上的所有备份系统进行验证,为了照顾用户运维人员的工作量,对于虚拟机数量较多的机构,一般采用抽检的方式进行可用性验证。这时也存在两种方案:
一种是通过抽检方式,人工一台一台去验证其可用性,这种方案存在两大问题:一是没有被抽检到的备份系统,其可用性无法保障;二是虽然是抽检,但如果备份系统足够多,按比例抽检也是一个浩大的人力工程。
另外一种是所有备份系统的自动化验证,即通过在灾备中心的虚拟化平台设置独立的网络环境,然后通过网络验证或自定义脚本验证,自动生成输出可用性验证报告,减轻运维人员的工作量。
4.结束语
AWS 的贝佐斯说过,亚马逊的经营理念就是把战略建立在不变的事物上。在虚拟机安全管理这件事上,不变的事情就是先进的方案终将取代落后的方案。
随着 Ramesh 的认罪,思科虚拟机被删风波暂告一个段落。但是 Ramesh 的现任雇主 Stitch Fix 竟然一副无所谓的态度,甚至希望他能继续正常上班。
所以信息系统和数据安全这件事,主动权还是要掌握在自己手里,毕竟数据真丢了,看笑话的是别人,损失的自己。
此文章转载自网络,如有侵权,请联系删除。
