

2,759
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
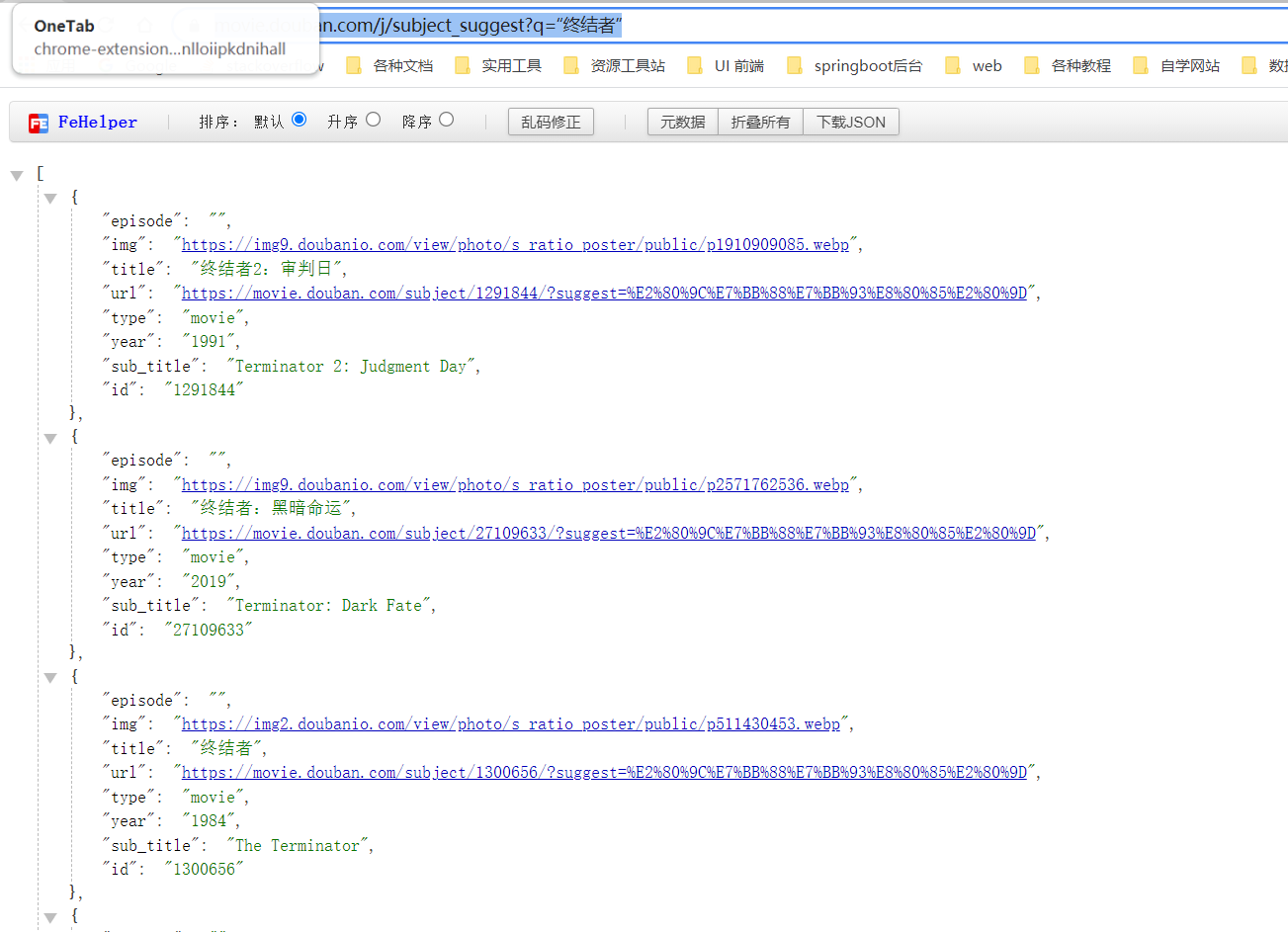
这个根据电影名得到电影数据信息的api 返回的预览页面:
可以知道电影信息是:动态加载的,不是静态的,经过判断也不是ajax得到的,是经过js加载的。
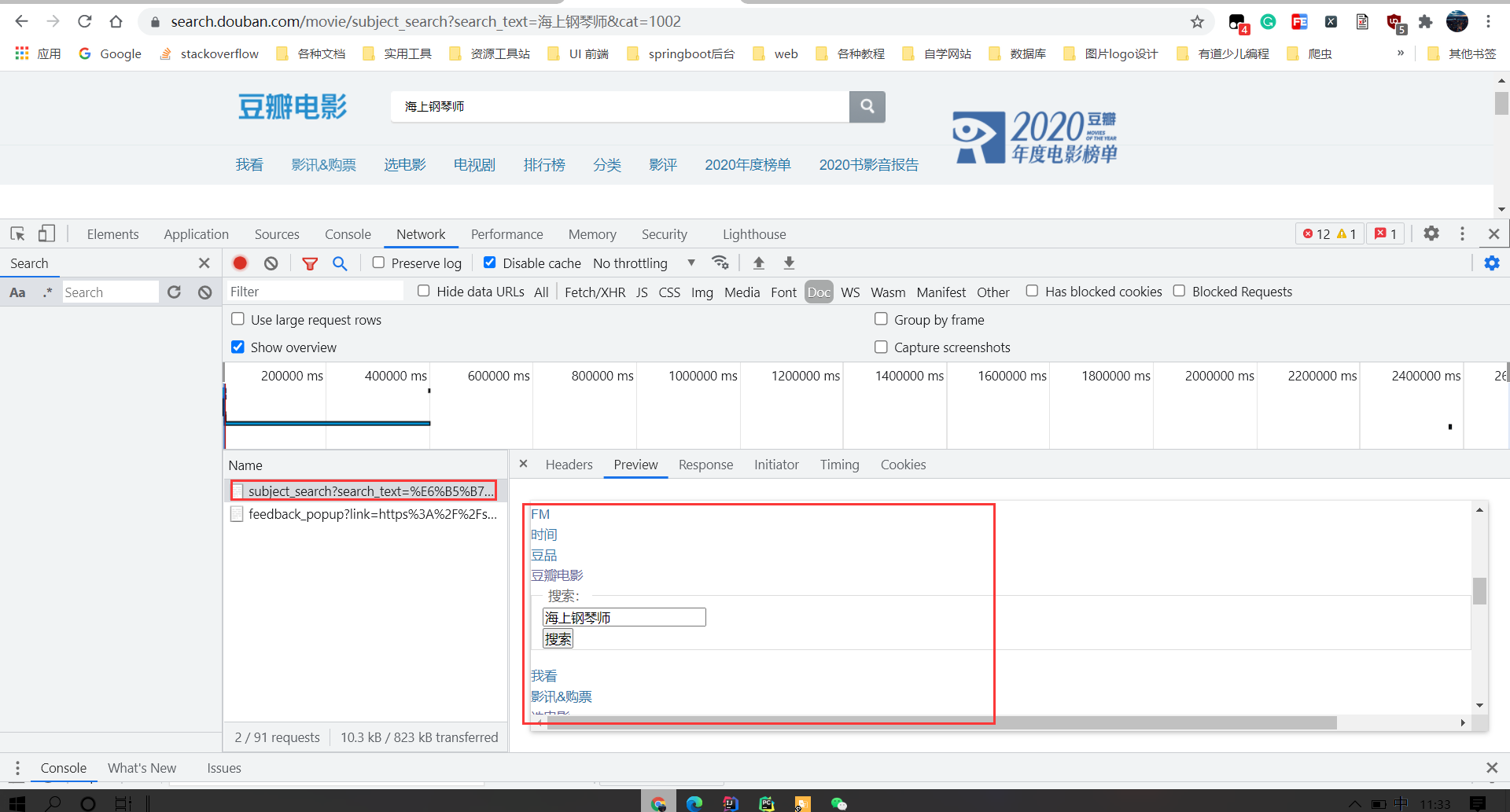
这是返回的电影信息页面,是这种js方式加载的数据。
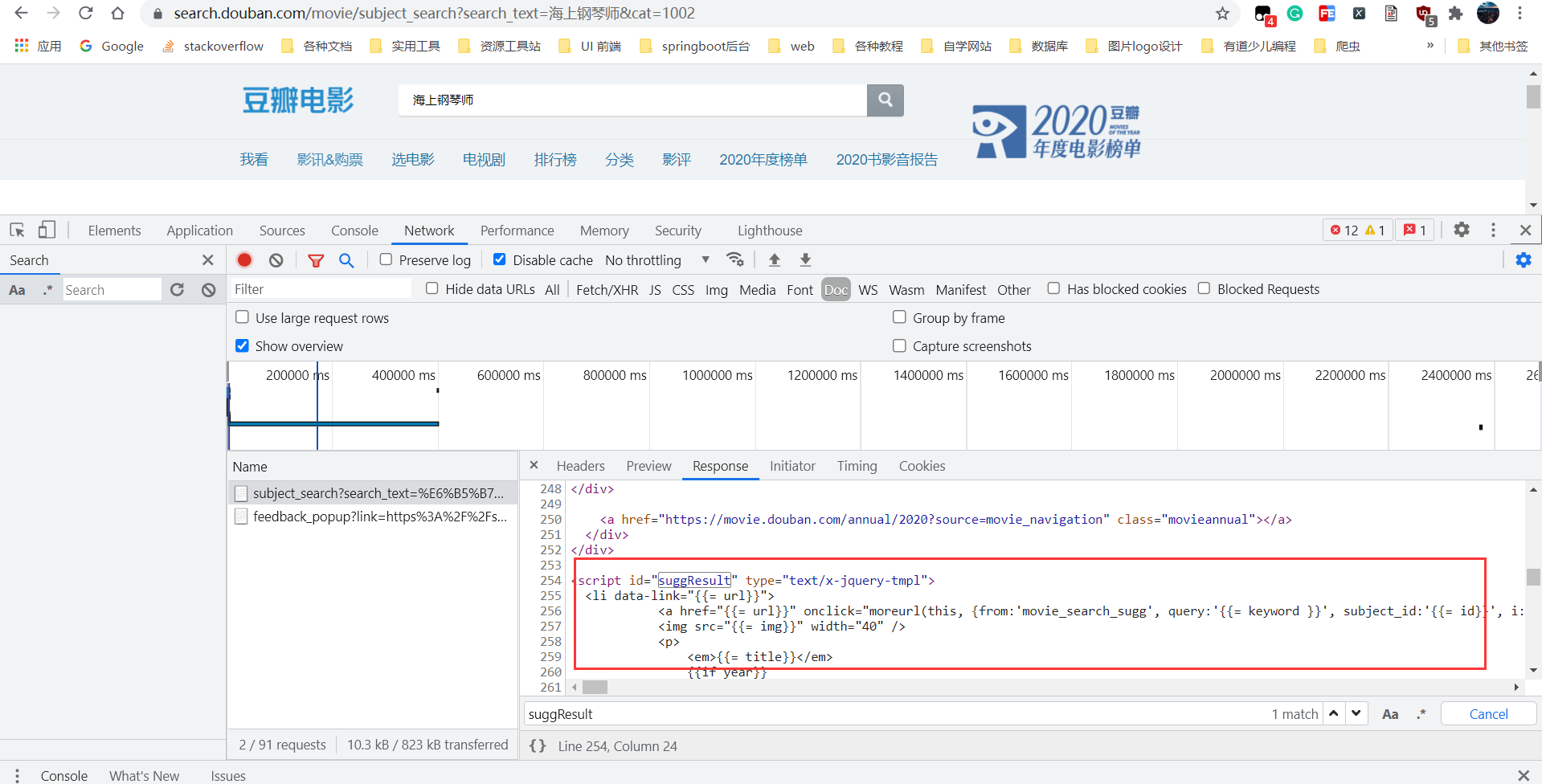
suggResult执行的js是: https://img3.doubanio.com/dae/accounts/resources/d3e2921/movie/bundle.js
这是js的内容:
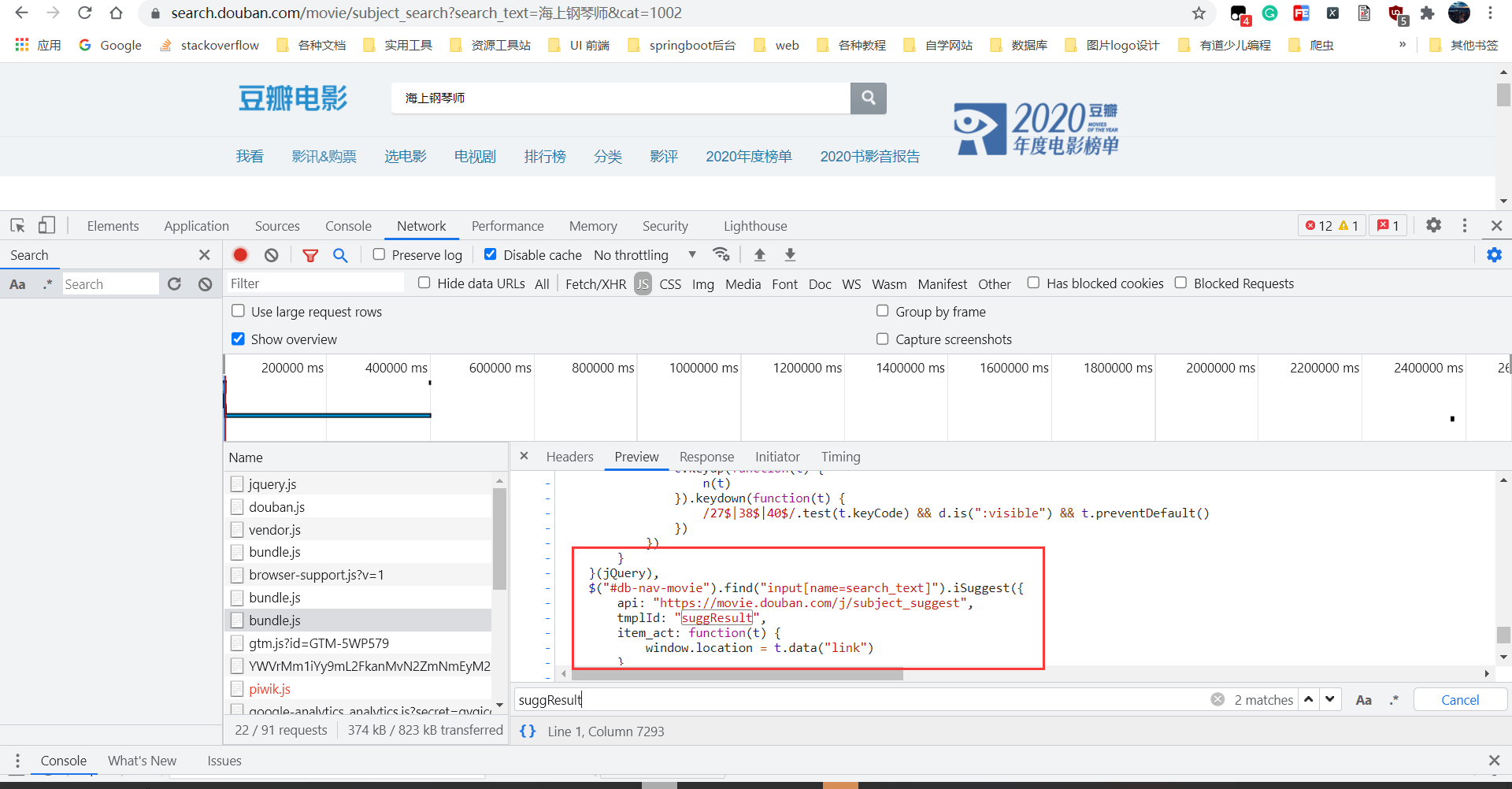
请问后面怎么分析这个js,看不太懂!
或者说有没有现成的接口,可以根据电影名字,获得豆瓣电影的信息的。



