



1,265
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享今天给大家带来的是 Python 爬虫框架 Scrapy,因为之前自己爬取数据用过,感觉很不错,所以就分享给大家了。我们先来看下该工具在 Github 上的数据情况,如下图所示,可以看到有 1.8k 个关注,41.5k 个 star,9.3k 个 fork,可以说非常亮眼了。

爬完数据,当然还要想着把数据存储在某个地方了,这个地方通常都是指数据库,耳熟能想的有 MySQL、Oracle 等等,不过我采用的是字典型数据库 MongoDB,至于为什么用它?一方面是因为爬取下来的数据,就是字典格式,所以顺手而为,另一方面,这个数据库还是蛮新奇的,对于新兴的事物,我想大家都会有好奇心吧?
同样的,这个数据库的数据也很不错,有 1.2k 个关注,20.4k 个 star,4.9k 个 fork。顺带再教大家一个技巧吧,判断一个项目,第一眼看 star 数,如果这个不是很高,那也不代表这个项目不好,第二眼看项目的 README 写的是否完善,你可以想像,如果一个项目连文档都不全,你还指望有多少人用。。。。。我估计项目作者就是为了自己能看懂而已。

下面我把爬取保存好的数据给大家看一眼,想要数据的来这里下载: https://codechina.csdn.net/csdn_codechina/software/uploads/f2a52c09086ab725ac7fa3f5470acf2b/dataframe.csv。
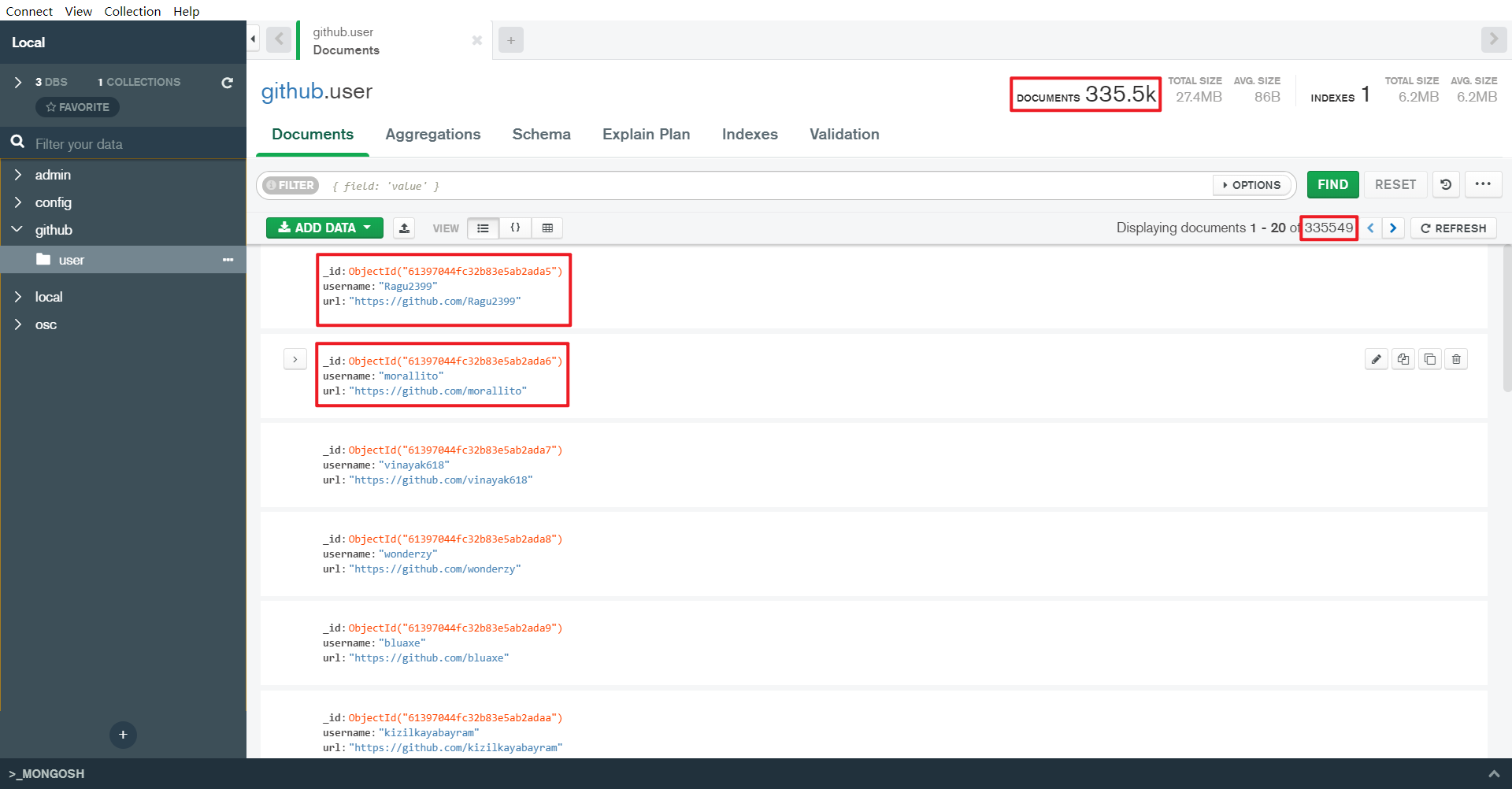
我通过使用 Scrapy 爬取了 Github 的 33w 条用户数据,不过此处还未进行重复数据去重。
下面我们进行去重操作,首先把 MongoDB 里存储的 Collection 导出成 csv 文件,然后用 Pandas 读取成 Dataframe,再调用去重 API,下面是去重后的结果,可以看到原始数据的 33w,变成了 19w,这里啰嗦一句,用的 IDE 是昨天介绍的 DataSpell,值得说的是,在数据交互上,它做的真的很不错。
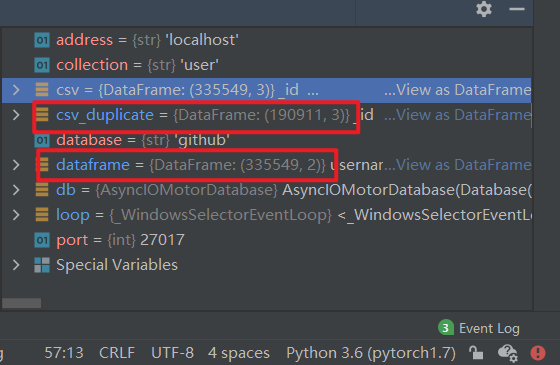
这里我觉得有必要放一下用户去重代码:
import asyncio
from motor.motor_asyncio import AsyncIOMotorClient
import pandas as pd
import nest_asyncio
nest_asyncio.apply()
def client_database(address, port, database):
client = AsyncIOMotorClient(address, port)
db = client[database]
return db
async def do_find(db, collection):
cursor = db[collection].find()
count = []
async for document in cursor:
print(list(document.keys()))
count.append(document)
dataframe = pd.DataFrame(count)
dataframe.set_index('_id', inplace=True)
dataframe.to_csv('dataframe.csv') # 保存CSV
return dataframe
if __name__ == '__main__':
address = 'localhost' # 地址
port = 27017 # 端口
database = 'github' # 数据库名字
collection = 'user' # 集合名字
db = client_database(address, port, database)
loop = asyncio.get_event_loop()
dataframe = loop.run_until_complete(do_find(db, collection))
最后我把爬虫代码放上来:
import scrapy
import sys
import time
import hashlib
import re
import urllib3
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client['github']
collection = db['user']
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
_version = sys.version_info
is_python3 = (_version[0] == 3)
orderno = "ZF202198xxxxxxx"
secret = "4a1536a5560b44xxxxxxxxxe9928b47"
ip = "forward.xdaili.cn"
port = "80"
ip_port = ip + ":" + port
timestamp = str(int(time.time()))
string = ""
string = "orderno=" + orderno + "," + "secret=" + secret + "," + "timestamp=" + timestamp
if is_python3:
string = string.encode()
md5_string = hashlib.md5(string).hexdigest()
sign = md5_string.upper()
# print(sign)
auth = "sign=" + sign + "&" + "orderno=" + orderno + "&" + "timestamp=" + timestamp
# print(auth)
proxy = {"http": "http://" + ip_port, "https": "http://" + ip_port}
headers = {"Proxy-Authorization": auth,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"}
class QuotesSpider(scrapy.Spider):
name = "github"
start_urls = [
'https://github.com/rajeevsrao?tab=followers',
]
def parse(self, response):
if float(re.findall(r"\d+\.?\d*", response.css('span.text-bold.color-text-primary')[0].get())[0]) > 0:
for follower in response.css('a.d-inline-block.no-underline.mb-1::attr(href)'):
d = {
'username': follower.get()[1:],
'url': response.urljoin(follower.get()),
}
collection.insert(d)
next_link = "https://github.com/" + follower.get()[1:] + "?tab=followers"
yield scrapy.Request(next_link, callback=self.parse, meta=proxy, headers=headers)
这里的话,我还是稍微解说下吧,首先我们以 Github 上的 rajeevsrao 为起点,也就是下图显示的这个用户。
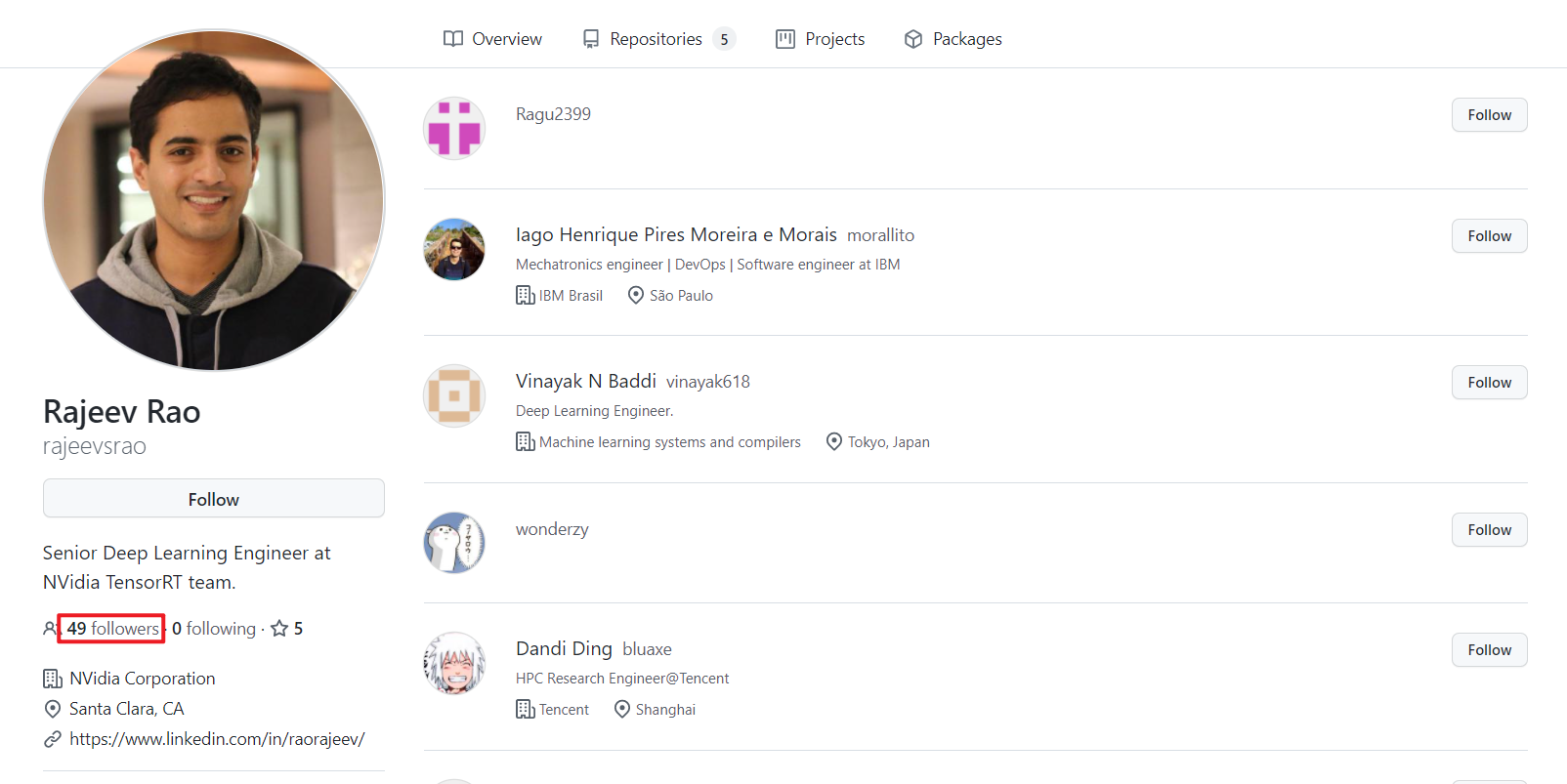
可以看到他有 49 个跟随者,那么我们接下来要遍历的是他的 49 个跟随者,以此类推,我们一共爬取到 19 w 个用户的 url。我们可以用这个 url 做什么事情呢?可以爬取这 19 w 个用户下的仓库 url,至于有多少个,我这边还没进行处理,后面可以分享。
这个中间还有个问题需要说明,就是 IP 代理,这个地方我用的是动态 IP 代理,有能力的话,也可以自己搭建 IP 代理池。最后说一句,其实以前我搭建过分布式的爬虫,当时采用的是 Scrapy + Redis + MongoDB,然后也搭建了一个 IP 代理池,代码就不放了,都是 18 年的事情了。



