189
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于那个课程 | 构建之法-2021年秋-福州大学软件工程 |
| 这个作业要求在哪里 | 2021年秋软工实践第一次个人编程作业 |
| 这个作业的目标 | 编码完成C/C++文件的关键字提取、性能分析与代码优化、GitHub初使用 |
| 学号 | 031904140 |
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 30 | 60 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | - | - |
| Analysis | 需求分析 (包括学习新技术) | 30 | 60 |
| Design Spec | 生成设计文档 | - | - |
| Design Review | 设计复审 (审核设计文档) | - | - |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 50 |
| Design | 具体设计 | 100 | 150 |
| Coding | 具体编码 | 500 | 600 |
| Code Review | 代码复审 | 100 | 100 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 100 |
| Reporting | 报告 | - | - |
| Test Report | 测试报告 | - | - |
| Size Measurement | 计算工作量 | 50 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 100 | 90 |
| 合计 | 1010 | 1150 |
目录
- 有四项要求,完成每项要求前要完成前置的各项要求;
- 基本要求是统计文件的关键词数目,注释和字符串中出现的“关键词”是假的关键词;
- if-else或if-else if-else 必须以else结尾才算作一组,降低了难度!
- 需统计的关键词为:
kw_list = ['auto','break','case','char','const','continue','default','do', 'double','else','enum','extern','float','for','goto','if', 'int','long','register','return','short','signed','sizeof', 'static','struct','switch','typedef','union','unsigned', 'void','volatile','while']
ls = []
if file_name.endswith('.cpp') or file_name.endswith('.c'):
fr = open(file_name, 'r', encoding='UTF-8')
for line in fr:
ls.append(line)
fr.close()
text = "".join(ls)
Count = {}
for word in kw_list:
num = text.count(word)
if num != 0:
Count[word] = num
items = list(Count.items())
count_sum = 0
for i in range(len(items)):
kw , count = items[i]
print(kw,'num : ',count)
count_sum += count
print('total num :',count_sum)
正则表达式的用法在数据采集与融合技术课程中有过初步实践,这里给出匹配注释、字符串以及英文单词的表达式
注释// /* */ :\/\*([^\*^\/]*|[\*^\/*]*|[^\**\/]*)*\*\/|\/\/.*
单引号 '':'.*'
双引号 "":\"([^\"]*)\"
英文单词:\b[a-zA-Z]+\b
另外可通过Regex在线测试正则表达式
import re
reg = r"(\/\*([^\*^\/]*|[\*^\/*]*|[^\**\/]*)*\*\/|\/\/.*|'.*'|\"([^\"]*)\")"
def replace_comment(file_name):
'''
替换注释
:param file_name: 文件路径
:return: 替换注释(字符串)后的str
'''
ls = []
if file_name.endswith('.cpp') or file_name.endswith('.c'):
fr = open(file_name, 'r', encoding='UTF-8')
for line in fr:
ls.append(line)
fr.close()
text = "".join(ls)
comment = re.finditer(reg,text)
for match in comment:
text = text.replace(match.group(),' ')
return text
reg = r'\b[a-zA-Z]+\b'
text = replace_comment(path)
line = re.findall(reg, text)
def kw_num():
Count = {}
for word in kw_list:
num = line.count(word)
if num != 0:
Count[word] = num
items = list(Count.items())
count_sum = 0
for i in range(len(items)):
kw, count = items[i]
print(kw, 'num : ', count)
count_sum += count
print('total num :', count_sum)
reg = r'\b[a-zA-Z]+\b'
text = replace_comment(path)
line = re.findall(reg, text)
def switch_num():
switch_num = 0
switch_flag = 0
case_num = []
if line.count('switch') == 0:
print('No switch')
return 0
for kw in line:
if kw == 'switch':
switch_num += 1
switch_flag = 1
case_num.append(0)
if switch_flag == 1 and kw == 'case':
case_num[switch_num-1] += 1
for i in range(len(case_num)):
print('Case num for No.{} switch: {}'.format(i+1, case_num[i]))
class Stack(object):
def __init__(self):
self.items = []
def isEmpty(self):
return self.items == []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def peek(self):
return self.items[len(self.items)-1]
def size(self):
return len(self.items)
def value(self,num):
return self.items[num]
正则表达式匹配else if :\be.*?f\b
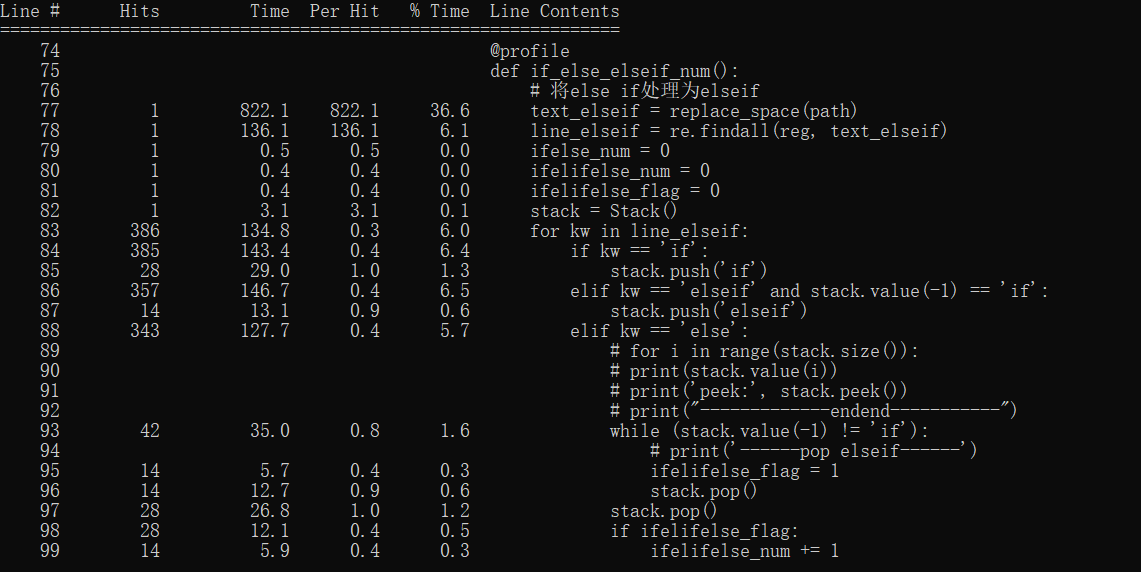
def if_else_elseif_num():
text_elseif = replace_space(text)
line_elseif = re.findall(reg, text_elseif)
ifelse_num = 0
ifelifelse_num = 0
ifelifelse_flag = 0
stack = Stack()
for kw in line_elseif:
if kw == 'if':
stack.push('if')
elif kw == 'elseif' and stack.value(-1) == 'if':
stack.push('elseif')
elif kw == 'else':
while (stack.value(-1) != 'if'):
ifelifelse_flag = 1
stack.pop()
stack.pop()
if ifelifelse_flag:
ifelifelse_num += 1
ifelifelse_flag = 0
else:
ifelse_num += 1
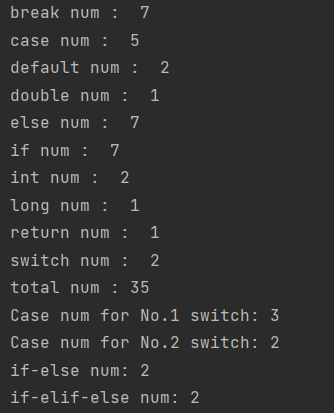
print('if-else num: {}'.format(ifelse_num))
print('if-elif-else num: {}'.format(ifelifelse_num))
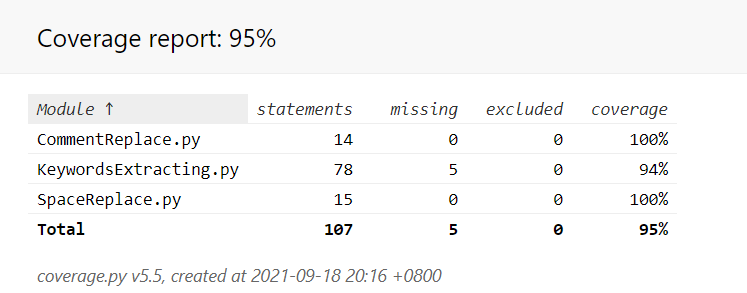
pip install coverage
coverage run <待测代码路径>
coverage html
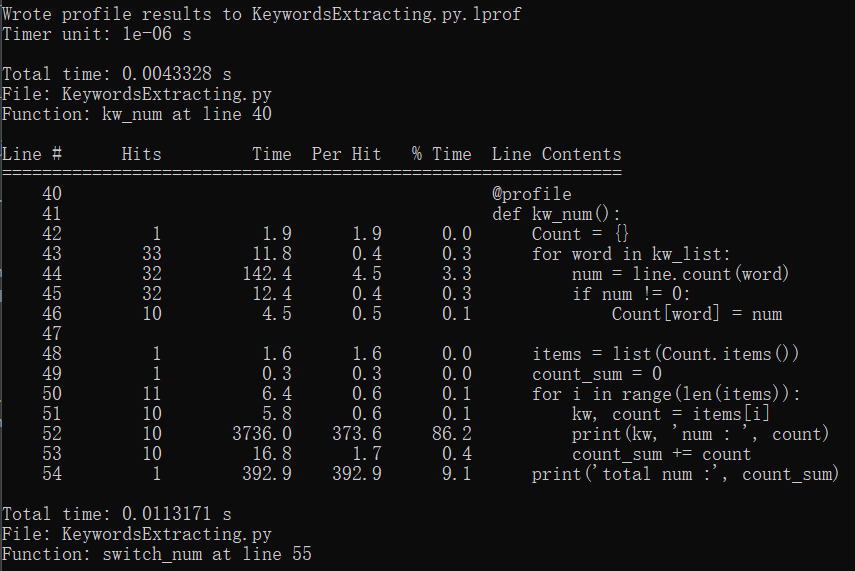
kernprof -l -v

仓库截图