

189
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
| 这个作业属于那个课程 | 构建之法-2021年秋-福州大学软件工程 |
| 这个作业要求在哪里 | 2021年秋软工实践第一次个人编程作业 |
| 这个作业的目标 | 设计程序对C语言文件的关键字进行统计、以及不同等级的分类提取、完善代码规范、GitHub使用 |
| 学号 | 031902130 |
1.文件的读取与分析
2.字符分割与比对
3.分析与计数
4.撰写博文
我的 个人代码规范
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 60 | 60 |
| Estimate | 估计这个任务需要多少时间 | 1200 | 1100 |
| Development | 开发 | - | - |
| Analysis | 需求分析 (包括学习新技术) | 100 | 80 |
| Design Spec | 生成设计文档 | - | - |
| Design Review | 设计复审 (审核设计文档) | - | - |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 40 | 50 |
| Design | 具体设计 | 200 | 160 |
| Coding | 具体编码 | 600 | 500 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 50 |
| Reporting | 报告 | - | - |
| Test Report | 测试报告 | - | - |
| Size Measurement | 计算工作量 | 50 | 40 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 60 |
| 合计 | 1200 | 1090 |
1. 工作迭代过程:
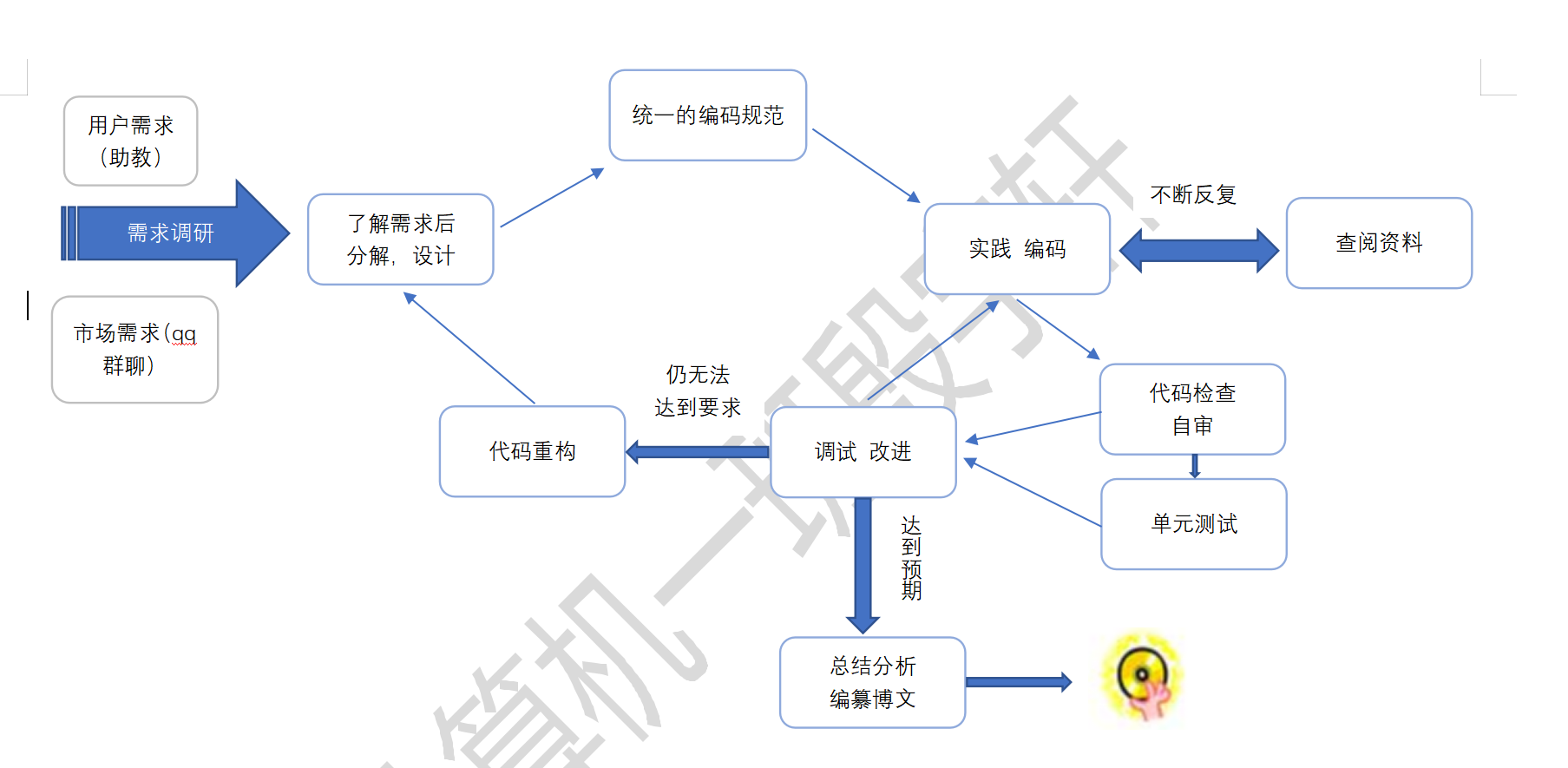
2.题目分析:
①有四个等级的要求,难度不断上升,并且都包含前置等级的所有要求。(也就是说,编码也可以逐步进行,在初等级代码上不断添加新的要求)
②根据给定的关键字,统计文本中的“真关键字”(即不能包含带有关键字的变量名,函数名,注释等,如 int int1;只有第一个int为关键字)。因此要屏蔽掉注释中的内容,可能要遇见// 或者 /* */ 就忽略其中的内容? 以及正确提取每一个字符串,先完整提取再比对计数。
③if-else结构让我联想到了当初的堆栈,检测if - else结构之间是否存在else if 便能完成第四等级的要求(理论上说)。
3.难点分析及解决(部分关键代码及函数思路)
①编码刚开始就遇到了第一个困难,那就是如何从文件的路径中读取内容。因为之前没有完成过类似的项目,于是我查找了各种网络上的资料。在参考 c++读取TXT文件内容 内容下,利用open函数实现了对包含空格在内的每个字符的读取,方便了之后的操作。
void readtxt(string file)
{
ifstream infile;
infile.open(file.data()); //将文件流对象与文件连接起来
assert(infile.is_open()); //若失败,则输出错误消息,并终止程序运行
char c;
infile >> noskipws;
while (!infile.eof())
{
infile>>c;
a[n++]=c; //用char型数组a存储
}
infile.close(); //关闭文件输入流
count(); //各等级计数
}
②真正意义上的第一个难点是对文本中每一个“单词”的提取,以方便查找关键词,并排除无关项。
首先首先我尝试利用空格或标点对每一个词进行分割,但实际操作中感觉对代码文件作为一个整体进行操作难以进行,而且很容易超时,于是我改变思路,对数组a(装有代码文件每个字符 包含空格,回车 的数组)进行逐个解析。忽略掉无用符号,在遇到第一个有效字母开始提取,直到遇到第一个不是字母或数字的内容停下里,记作一个单词。
每个单词与关键字组进行一一对比,再进行之后的操作。
int j=0;
int getword(char *word, int lim){
char *w = word;
for( j;j<n;j++){
if(isspace(a[j]))
continue;
else break;//忽略空白符
}
*w++ = a[j];
if (!isalpha(a[j])){ //当前不是字母的情况
*w = '\0';
return a[j++];
}
j++;
for ( ; --lim > 0; w++){
if (!isalnum(*w = a[j++])){ //当前不是字母或数字时,该单词结束
j--;
break;
}
}
*w = '\0'; //字符串结束符'\0'
}
③在此之上,对if-else if-else if-else结构的区分和统计也是一大难点,一开始我的思路是用堆栈的方法解决。但是由于我是逐个对比的方式来遍历挣个代码,因此else if的确定变得更加复杂。
我最后只能创建了一个word0数组来记录上一个单词信息,以此来区分 if、else if 和 else。并简化成特定数字入栈,遇到else出栈。但想法简单,操作起来格外复杂。由于我一开始只提取了单词,没有记录符号空格等内容,导致区分不成功,造成严重错误。在添加了wordflag标记并加入if条件里后,终于落下了帷幕。
解释1:举例来说,如果程序中出现了下方这样的代码段,我的代码会把中间的空格和大括号忽略掉,导致错误识别为else if。
else{
if(j!=0){}
}
解释2:对于if条件中的内容:第一点是当前这个单词为 “if”,第二点是(上一个单词不是else,或者和上一个单词 中间 存在括号等符号分隔开)即 if(strcmp(keytab[m].word,"if")==0&&(strcmp(word0,"else")!=0||wordflag==1))
对于switch case的统计就较为简单了,只要遇到swtich将case的计数归零并记录下来即可。swtich有几个,case就有几组。
if(strcmp(keytab[m].word,"if")==0&&(strcmp(word0,"else")!=0||wordflag==1))
st.push(1); //记录if为1 else if为2 else为3
if(strcmp(keytab[m].word,"if")==0&&strcmp(word0,"else")==0&&wordflag==0)
st.push(2);
if((strcmp(keytab[m].word,"if")!=0||wordflag==1)&&strcmp(word0,"else")==0)
pop0(); //遇到else出栈
每轮循环最后刷新word0以不断保存上一个单词。
strcpy(word0,keytab[m].word);
完整的计数输出函数count()。对每一个得到的word进行一一比对查找,并完成各类计数工作。以及分等级输出。(已修改结构体为数组结构)
void count(){
int m;int wordflag=0;int sum=0;
char word[MAX],word0[MAX];//word0记录上一个单词
for(int i=0;i<n;i++)
{
getword(word, MAX);
if (isalpha(word[0])) //word的第一个为字母
{
if ((m = binsearch(word, NKEYS)) >= 0)
{sum++;//在结构体中查找成功,关键字计数加1
if(strcmp(key[m],"case")==0)
casenum[casen]++;
if(strcmp(key[m],"switch")==0)
{casen++;switchnum++;
}
if(strcmp(key[m],"if")==0&&(strcmp(word0,"else")!=0||wordflag==1))
st.push(1); //记录if为1 else if为2 else为3
if(strcmp(key[m],"if")==0&&strcmp(word0,"else")==0&&wordflag==0)
st.push(2);
if((strcmp(key[m],"if")!=0||wordflag==1)&&strcmp(word0,"else")==0)
pop0(); //遇到else出栈
strcpy(word0,key[m]);
}
wordflag=0; //还原 wordflag
}
else wordflag=1;//记录上一个word为非字母
}
//统计结束,打印结果
cout<<"total num:"<<sum<<endl;
if(level>=2){
cout<<"switch num:"<<switchnum<<endl;
cout<<"case num:";
for(int k=1;k<=switchnum;k++)
cout<<casenum[k]<<" ";
cout<<endl;
}
if(level>=3){
pop0();
cout<<"if-else num:"<<ifelsen<<endl;
}
if(level==4){
cout<<"if-elseif-else num:"<<ifelseifn<<endl;
}
}
④感觉最大的难点,其实是让我一个连qq空间都发不明白的人编纂博文吧!
4.剩余关键代码及思路解释
①折半查找函数
我的代码中因为对每一个单词与关键词组进行了一一对比,所以为了减少以一对比的时间,我尝试运用了折半查找函数binsearch的方法缩短运行时间(二分法)。(已修改为数组结构)
int binsearch(char *word, int n)
{
int cond;
int low, high, mid;
low = 0;
high = n - 1;
while (low <= high)
{
mid = (low+high) / 2;
if ((cond = strcmp(word, key[mid])) < 0)
high = mid - 1;
else if (cond > 0)
low = mid + 1;
else
return mid;
}
return -1;
}
②出栈函数
遇到else出栈时,对两种可能结构的计数。(函数外定义flag,ifelsen记录if-else数目,ifelseifn记录if-else-if数目)
出栈过程中,遇到else if 标记flag改为1(即if 与else中间夹杂有else if了),再遇到if是,就可以确定为if-elseif-else结构了
反之,若flag为0,即中间没有else if 那么就可以确定为if else 结构。
找到 if 完成操作之后 退出此函数,等待下一个else的到来。
int flag=0;
int ifelsen=0,ifelseifn=0;
void pop0(){
while(st.empty()<=0){
int p=st.top();
st.pop();
if(p==2){
flag=1;
}
if(p==1){
if(flag==1){
ifelseifn++;
flag=0;break;
}
if(flag==0){
ifelsen++;break;
}
}
}
}
③关键词组结构体(一开始为了统计方便,后来发现count用处不大,现已经修改为数组结构)
struct key //结构体数组,关键字按顺序排列
{
const char *word;
int count;
} keytab[] = {
"auto",0,"break",0,"case",0,"char",0,"const",0,
"continue",0,"default",0,"do",0,"double",0,
"else",0,"enum",0,"extern",0,"float",0,"for",0,
"goto",0,"if",0,"int",0,"long",0,"register",0,
"return",0,"short",0,"signed",0,"sizeof",0,
"static",0,"struct",0,"switch",0,"typedef",0,
"union",0,"unsigned",0,"void",0,"volatile",0,"while",0,
};
补:修改后的数组结构
const char * key[] ={
"auto","break","case","char","const",
"continue","default","do","double",
"else","enum","extern","float","for",
"goto","if","int","long","register",
"return","short","signed","sizeof",
"static","struct","switch","typedef",
"union","unsigned","void","volatile","while"} ;
//const char*型数组,关键字按顺序排列
④各种定义以及主函数
#define MAX 100000
#define NKEYS 32
//共32个关键字需要统计
int n=0,level;
char a[MAX];//存储一个单词,大小在100000字符以内
int switchnum; //记录swtich个数的变量
int casenum[100],casen=0;//记录case个数的变量
int ifelsen=0,ifelseifn=0;//记录if-else个数以及if-elseif-else个数的变量
stack<int> st;//堆栈实现if else elseif的匹配问题
int main(){
string s;
cin>> s;
cin>>level;
readtxt(s);
return 0;
}
在网上查阅了相关教程1,用VS完成了本次单元测试
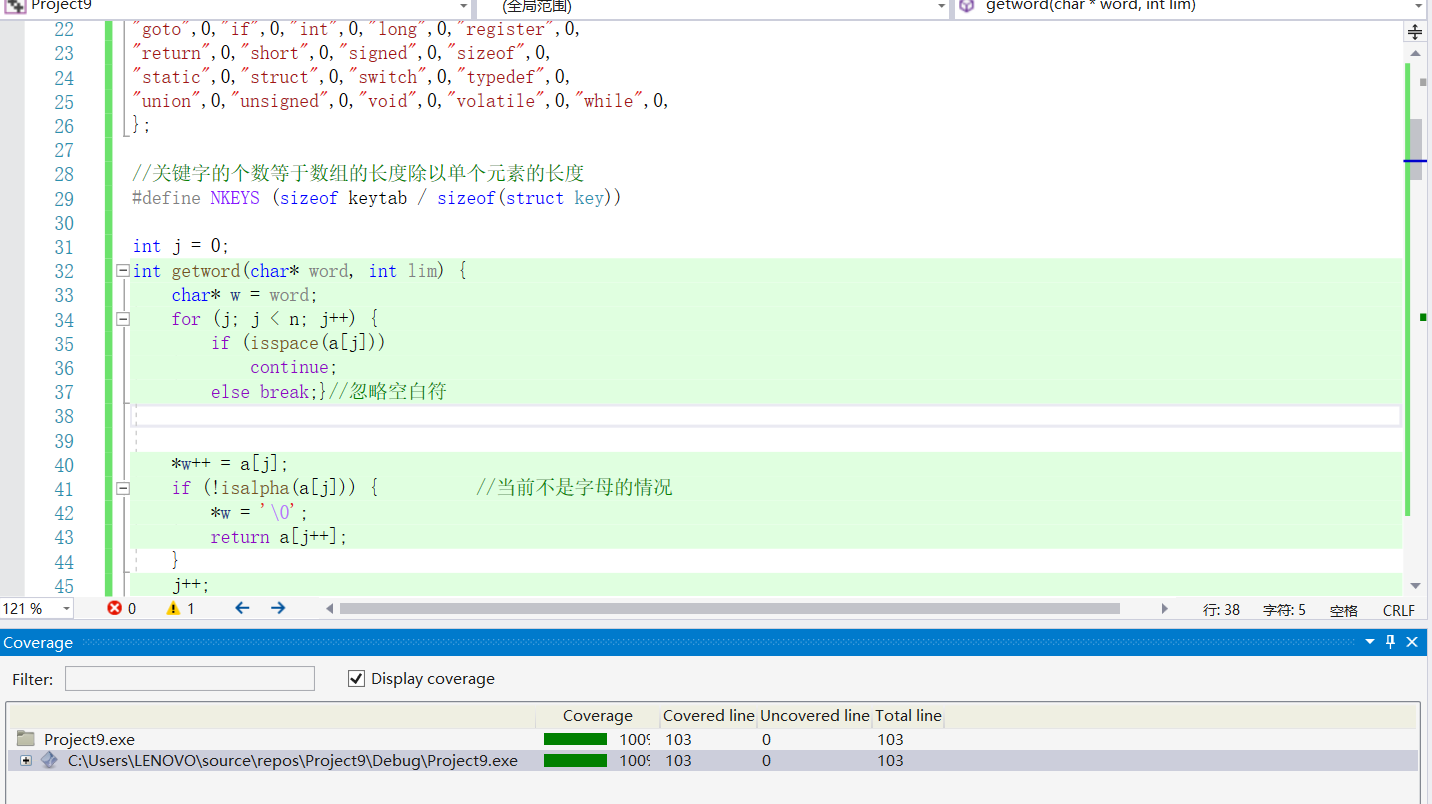
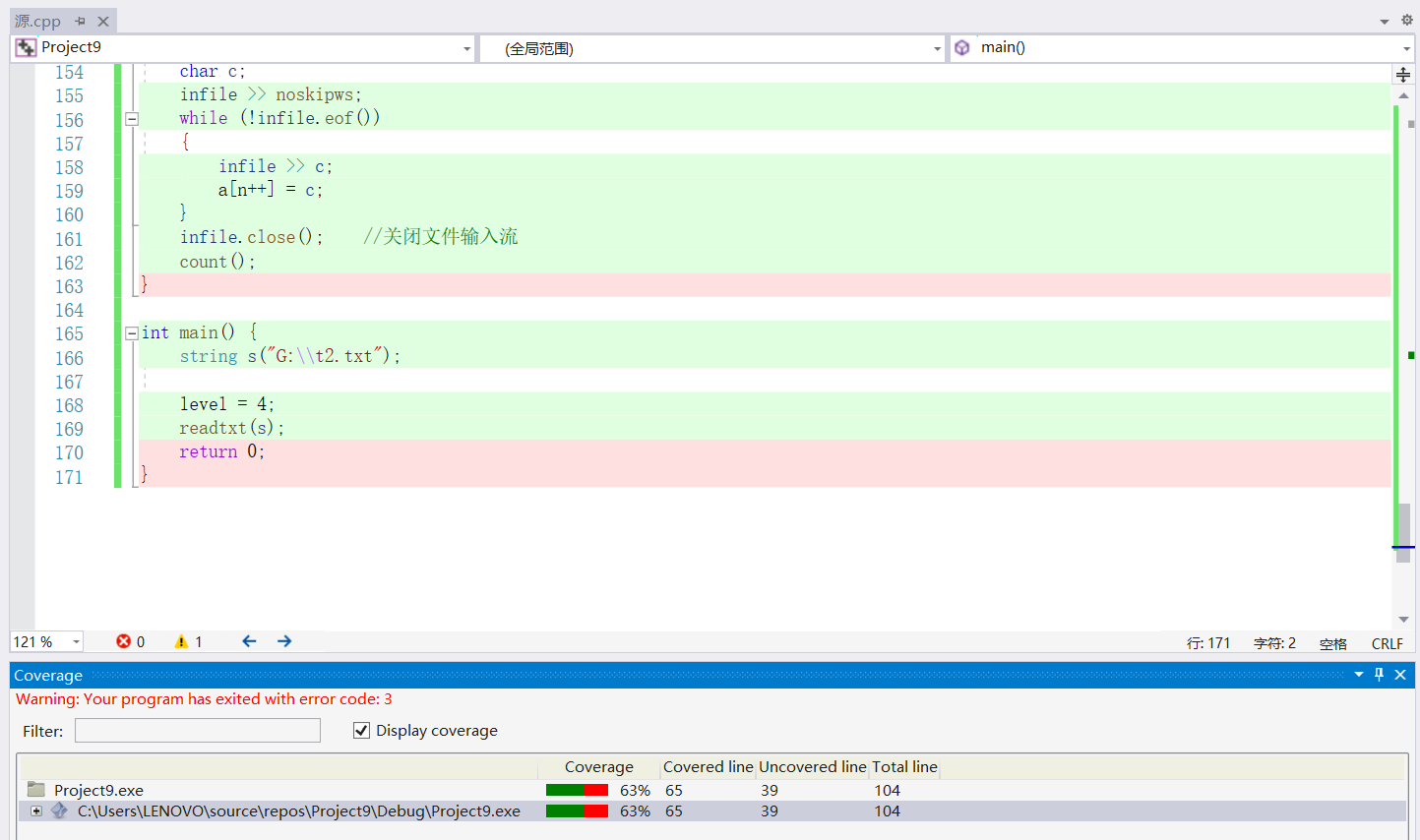
可见在测试等级为4,并且样本文件足够复杂(包含所有情况时),代码覆盖率可以达到100%。
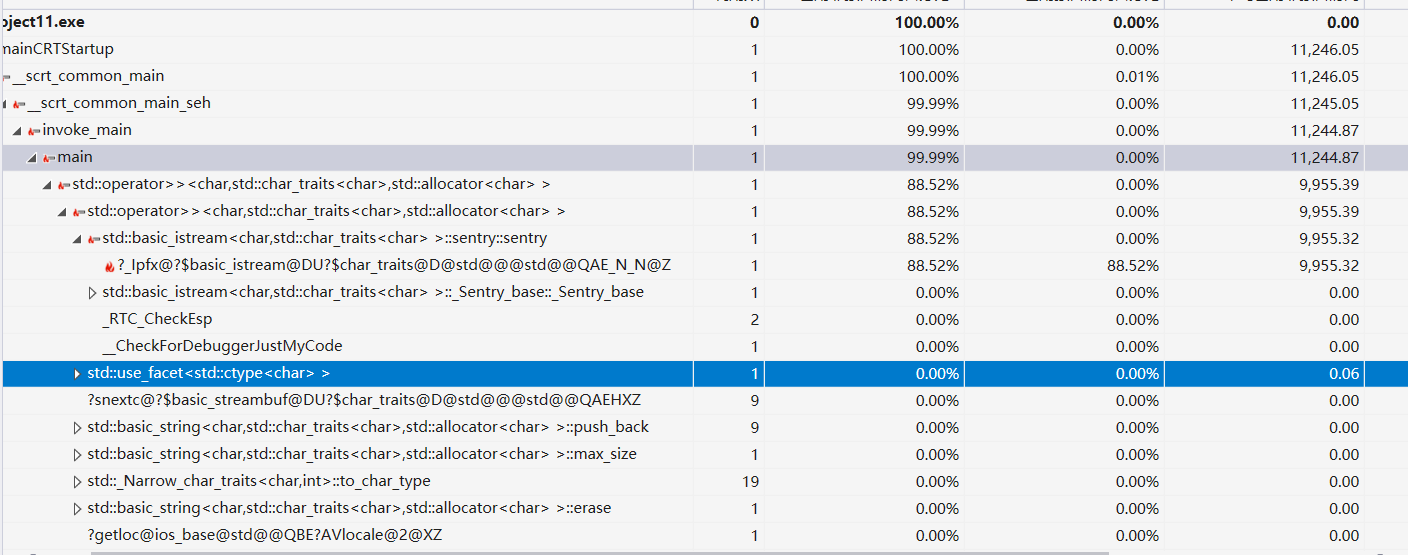
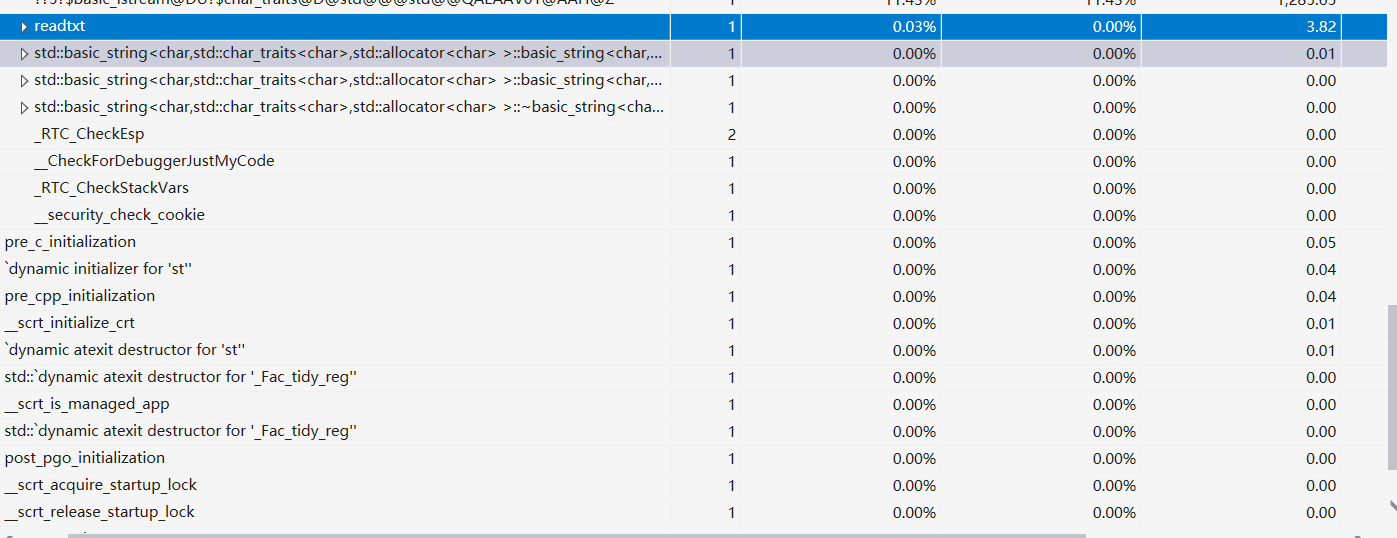
小结: 由图可知 , 占用性能最多的输入输出,其次是 readtext 函数 和 <stack> 头文件的堆栈占用了较多的性能。
这次作业任务完成花费了很多时间。撰写完成博文的这一刻距离写完代码已经很久很久了。主要是对各方面操作不太熟悉,以及长时间没写代码的生疏。git建立,博文编纂,各种专有名词学习,不知不觉的学习成长了许多。在完成整个作业的过程中,感觉到自己对程序开发有了初步了解,对问题的解决也更有信心了。但这次学习中,很多看似很简单的问题我却用了很久很久的时间,希望可以给下次的作业完成打下基础!

1.总体逻辑清晰
2.分析、性能评估等内容丰富
高分

你没有选择用 Python 来做题,为什么呢?




