

189
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | https://bbs.csdn.net/forums/fzuSoftwareEngineering2021?category=0 |
|---|---|
| 这个作业要求在哪里 | https://bbs.csdn.net/topics/600574694 |
| 这个作业的目标 | 完成代码编写、学习使用GitHub、进行代码规范、个人总结 |
| 学号 | 031902227 |
一、PSP表格
| Personal software process stages | 预估耗时(分钟) | 预估耗时(分钟) |
|---|---|---|
| Planning 计划 | 40 | 30 |
| Estimate 估计这个任务需要多少时间 | ||
| Development开发 | ||
| Analysis 需求分析 (包括学习新技术) | 300 | 420 |
| Design Spec生成设计文档 | 40 | 90 |
| Design Review 设计复审 | 20 | 20 |
| Coding Standard 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design具体设计 | 60 | 40 |
| Coding具体编码 | 300 | 420 |
| Code Review代码复审 | 60 | 90 |
| Test测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting报告 | ||
| Test Report 测试报告 | 20 | 30 |
| Size Measurement计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan事后总结, 并提出过程改进计划 | 40 | 40 |
| Total合计 | 1060 | 1360 |
二、迭代过程
1. 基本要求输出
在进行基本要求输出的时候,我首先想到的是先将关键字列成一个关键字列表,然后进行文件导入,然后按行进行读取,之后读取完然后使用.replace() 和 .split()这两个函数将按行读入的代码,规范成字典,将规范后的字典与关键字列表进行对比,如果字典中的元素存在与关键字列表当中,则保存在字典里,并且该键的键值加一,否则删除该键,最后利用for循环统计关键字数;
def get_keyword_num ():
num = 0
key_word=['auto','break','case','char','const','continue','default','do','if','while','static','double','else','enum','extern','float','for','goto','int','long','register','return','short','signed','sizeof','struct','switch','typedef','union','unsigned','void','volatile']
store={} #创建一个字典保存文件中的关键字
file = open("code.txt","r",encoding='utf-8') #打开txt格式且编码为UTF-8d的文本
while(1):
lines = file.readlines() #按行读入文件
for line in lines: #循环遍历每行的词语并统计个数
line = line.replace(",","").replace(".","").replace("{"," ").replace("}"," ").replace(":","").replace(";","").replace("?","").replace("("," ").replace(")"," ")
#将代码中的符号替换为空格
count = line.split() #提取出line中的单词组成列表
for word in count:
if len(word) < 2: #排除单个字的干扰,使得输出结果为词语
continue
else:
store[word] = store.get(word,0)+1 #如果字典里键为word的值存在,则返回键的值并加一,否则,返回0,再加1
for key in list(store.keys()): #遍历字典的所有键,如果不是列表里的关键字则删除
if key not in key_word:
del store[key]
if not lines:
break
for key in store:
if key in key_word:
num = num + store[key] #统计关键词出现次数
print("total num: ",num)
print("switch num: ",store['switch'])
file.close()
return
2. 进阶要求
考虑到switch-case,所以我每找到一个switch或者case我就会保存在一个新创建的列表里面,遇到switch时还要继续使用num进行switch的个数统计
def get_switchcase_num(count):
put = []
for word in count:
if word == "switch":
put.append(word)
if word == "case":
put.append(word)
return put
cun =0
sum = 0 #统计siwitch和case关键词出现次数
put_1.reverse()
for word in put_1:
if word == "switch":
if cun != "0":
put_2.append(cun)
cun = 0
sum = sum + 1
if word == "case":
cun = cun+1
put_2.reverse()
统计case个数时同样也是用另一个新的列表,保存每个switch-case结构里面的case个数,这里我考虑到计数方标先将保存switch-case的列表反转了,在最后输出的的时候再把保存case个数的列表反转即可
3. 拔高要求&终极要求
在开始的时候我同样考虑到使用查找switch-case的方法,结果发现行不通,继而想到了就是在每行读入的时候先判断是否存在if、else if、else,这三个关键词,使用的是.find()函数,创建一个新的列表存放找到的if、else if、else,关键字,如果找到if 则标记0存入列表,找到else if标记1存入列表,找到else标记2存入列表。但是这里值得注意的是使用if - elif - else语句判断的时候先判断else if。
line_1 = " ".join(count)
if line_1.find("else if") != -1:
lay_1.append('1')
elif line_1.find("if") != -1:
lay_1.append('0')
elif line_1.find("else") != -1:
lay_1.append('2')
else:
continue
然后判断列表中是否存在if-else、if-elseif-else。我这里投机取巧了,默认了文件中的所有 if 和 else 都是有唯一匹配的。寻找完if-else语句后直接寻找 else 的个数,然后减去之前if - else 的个数得到 if - elseif- else 的个数。
cun_1 = 0
cun_2 = 0
for x in range(len(lay_1)):
if lay_1[x] == '0' and lay_1[x+1] == '2':
cun_1 = cun_1 +1
if lay_1[x] == '2':
cun_2 = cun_2 + 1
- GitHub仓库代码
https://github.com/yogajia/yogajia
三、正确性与性能评测
运行程序的结果
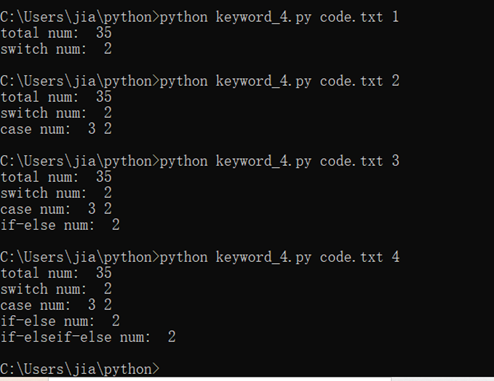
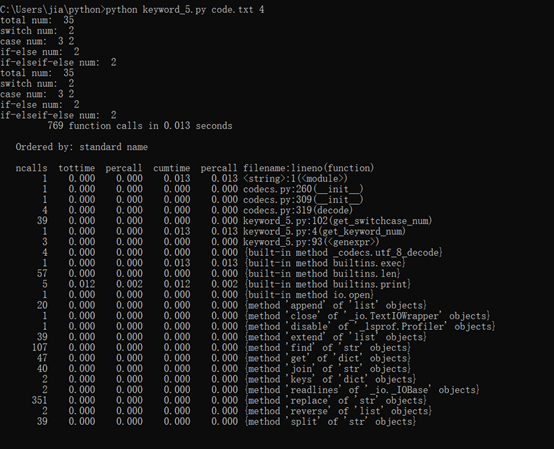
使用了 import cProfile,进行了性能评测
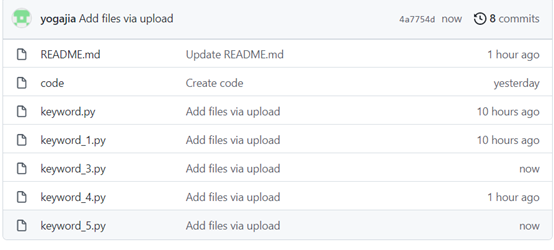
GitHub提交代码,这里我是手动添加的,并没有使用git工具(狗头保命)。也是因为没有使用git工具,导致我每次修改后保存的代码文件被更新(直接在之前的代码里面修改,然后上传到GitHub,并没有该文件名)
四、问题与解决办法
最开始的时候在构思部分不知道怎么做,以及程序开始的时候是不知道如何导入文件,之后在网上查找相关信息,参考了如下博文
https://blog.csdn.net/weixin_43886356/article/details/86711012
解决了文件传入,按行读入,代码规范等问题;在检测程序的正确性时,突然无法运行,在vscode里面和终端都无法运行,然后就是检查环境配置问题,都没找到原因,无果,果断休息,第二天再打开时又好了(欣喜若狂);在写代码过程中最开始我是打算使用c++写的,但是写了一会发些python更好用,转为使用python,在网上查找资料,找到许多函数,极大提高了我的协作效率;在文件输出的时候,打算使用switch-case语句,后来发现python根本就没有这种语句,继而使用了if - elif - else 的语句。使用git工具生疏,开始不知道如何保存到GitHub的文件库中,最后尝试使用gittool 未果,直接手动上传文件。
五、个人总结
本次作业个人认为是比较难的。在实验过程中也曾多次因为不会写代码,而直接放弃到第二天再来写。本次的作业中的代码,比较杂,并没有很好的按照python的代码规范去写,但是我又不想改动,怕到时候手贱改不回来了,导致辛辛苦苦写的代码无法运行。我自己在这次作业中是有些畏难的,在作业刚发布没多久个人就感觉这个很难,我应该不会做,然后拖沓了两天在开始做的,做的时候参考过其他的一些代码,发现也并不是想象中的那么困难,即使在写代码的时候遇到问题,也会比较快的的找的新的解决办法,所以等下次作业发布的时候第一时间,就开始做,不在拖沓,即使你拖沓但是作业也是要完成的。

1.总体逻辑清晰但是性能分析的内容欠佳
2.解决问题与总结的思路明确
中高分

在作业刚发布没多久个人就感觉这个很难,我应该不会做
通过学习,就会了, 这就是上大学的部分意义吧。




