


183
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| The Link of Requirement of This Assignment | https://bbs.csdn.net/topics/600798588 |
| The Aim of This Assignment | Code personally & learn git and github & learn the process of writing a project & learn unit test and performance test |
| MU STU ID and FZU STU ID | 19104308 & 831901320 |
Step1:Output "keyword" statistics
Step2 And Step3:'Switch case' And 'if else'
Unit Coverage And Performance Testing
| Personal Software Process Stages | Estimated Time/hours | Completed Time/hours |
|---|---|---|
| Planning | 1.5 | 2 |
| Estimate | 0.5 | 0.5 |
| Development | 10 | 10 |
| Analysis | 15 | 10 |
| Design Spec | 1 | 1 |
| Design Review | 1 | 1 |
| Coding Standard | 1.5 | 2 |
| Design | 2 | 2 |
| Coding | 12 | 10 |
| Code Review | 5 | 3 |
| Test | 5 | 2.5 |
| Reporting | 3 | 1.5 |
| Test Report | 2 | 1 |
| Size Measurement | 0.5 | 0.5 |
| Postmortem&Process Improvement | 2 | 2 |
| total | 62 | 49 |
When I saw this question at the beginning, I felt quite approachable, at least I could understand the question completely, without some words that people need to search to understand at the beginning. The topic mainly involves the string operation of text, need to extract enough information from C/C++ files, used to judge the structure of the code, and finally achieve the purpose of keyword extraction.
After reading the problem, My first thought is to use the simplest dictionary matching method for keyword search, think of C language also use <vector> ; Java I usually use for data processing, so I chose Python, which is probably simpler.
I first learned the use of Git, learn several pieces of Git content, file upload to the cache, file comments, as well as warehouse cloning and update, the use of branches and so on. But the tutorial I watched was so old, I still used the old account password instead of personal token, and the private email issue. I was able to solve this problem by looking for other tutorials online.
About regular expressions, I've been using them for so long in my freshman year that I've almost forgotten them, although. vector> Yes, but I still wanted to use Python, so I went back to the tutorial to learn how to use regular expressions.
As for personal code standards, I went to Zhihu to learn about the specific content after writing the code, and then found the Google code specification and selected my own code specification.
I forgot all about using the Python stack again, so I went back to the tutorial.
In terms of data processing, I also referred to some CSDN materials. Although I finally found that data processing might be unnecessary, I still put it up.
I used the following regular expressions:
- All comments:(//.*)|(/\*[\s\S]*?\*/)|(/\*[\s\S]*)
- Single quoted string:(\'[\s\S]*?\')|(\'[\s\S]*)
- Double quoted string:(\”[\s\S]*?\“)|(\”[\s\S]*)
- All strings that can be keywords:[a-zA-Z]{2,}
After getting C/C++ files, the first thing I need to do is data processing. Because I read C/C++ files from Python, the first thing I think of is to change the file suffix to TXT file, and then delete all the comments in the file. At the same time, I thought of using regular expression to delete. But this raises a new question. Should I first remove the braces after the comments and keywords in the file processing section to facilitate my subsequent use of dictionary queries, or directly use the regular expressions for the keywords? I didn't want to spend too much time on data processing, so I chose to use regular expressions for the rest of the code (although it turns out that all four jobs can be done using stacks).
import os
import sys
import re
files = os.listdir('.')
for filename in files:
portion = os.path.splitext(filename)
if portion[1] == ".cpp" or portion[1] == ".c":
newname = "test" + ".txt"
os.rename(filename,newname)
PY_PATTERN = re.compile(
r"""
\s*\#(?:[^\r\n])*
| \s*__(?:[^\r\n]*)
| "{3}(?:\\.|[^\\])*"{3}
| '{3}(?:\\.|[^\\])*'{3}
""",
re.VERBOSE | re.MULTILINE | re.DOTALL
)
txt = open("test.txt").readlines()
b = re.sub(PY_PATTERN, '', ''.join(txt))
single = re.compile(r"\n\n")
b = re.sub(single, '\n', b)
print(b)
I first created a list to store keywords, and then iterated through several regular expression converted keywords to match the previous list, obtaining an array count[key] that was not printed, as well as the total number of successful matches.
def keywords_num (code):
count = {}
Key_sum = 0
key_list = ['auto','break','case','char','const','continue','default','do','if','while','static','double','else','enum','extern','float','for','goto','int','long','register','return','short','signed','sizeof','struct','switch','typedef','union','unsigned','void','volatile']
for key in key_list:
n = len(re.findall("[^0-9a-zA-Z\_]" + key + "[^0-9a-zA-Z\_]", code))
if n != 0:
count[key] = n
Key_sum += n
print('The total num is: ',Key_sum)
#return Key_sum
At the same time, the number of switches and cases can be calculated by subtracting the number of cases in each group, but I think the result is correct. Maybe the sample code this time is right, so please see the test verification later.
def switch_num(code):
case_num = []
switch_num = 0
switch_list = re.finditer(r"\sswitch\([^)]*\)\s*{",code)
for i in switch_list:
switch_num += 1
index = i.end()
case_list = re.findall(r"\scase\s",code[index:])
case_num.append(len(case_list))
for j in range(switch_num-1):
case_num[j] = case_num[j]-case_num[j+1]
print ('The swith num is: ',switch_num)
print('The case num is',case_num[0],case_num[1])
#return switch_num, case_num
Using Python's stack, check whether the queue is if or else if, and if so, push it onto the stack. I'm going to say else in the queue, and then I'm going to say is the previous one if or else if, if is going to push if-else +1 out of the stack if, and else if is going to push if-else if-else +1 out of the stack all the way to the first if out of the stack.
def count_if_else(code):
if_stack = []
# if-else num
if_else_num1 = 0
# if-elseif-else num
if_else_num2 = 0
match_else_if = False
#find all if、elseif、else
all_list = re.findall(r"else if|\s*else[{\s][^i]|if", code)
for i in range(len(all_list)):
if all_list[i] == "if":
if_stack.append(1)
elif all_list[i] == "else if":
if_stack.append(2)
else:
while True:
if if_stack.pop() == 2:
match_else_if = True
else:
break
if match_else_if:
if_else_num2 += 1
match_else_if = False
else:
if_else_num1 += 1
return if_else_num1,if_else_num2
Use Coverage statistics unit test coverage, you need to install coverage.
coverage run keyword.py arg1 arg2
coverage html

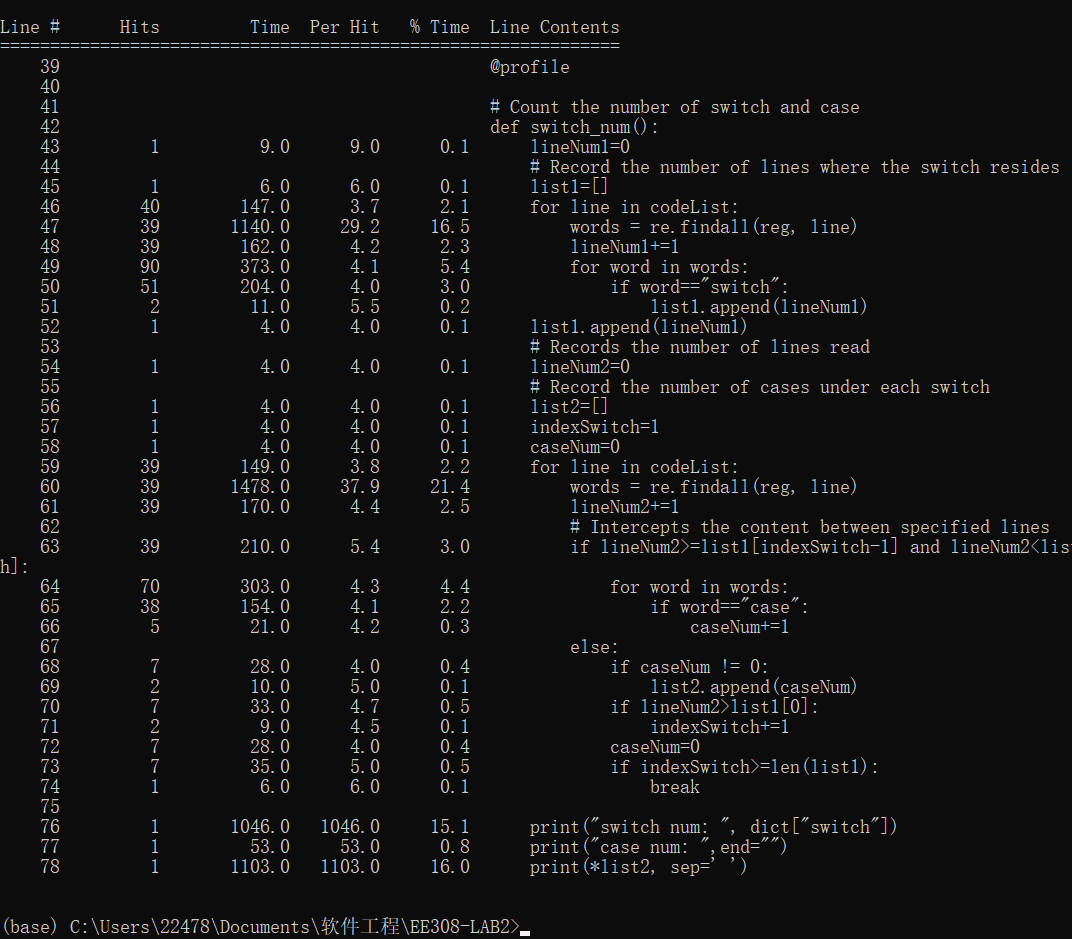
Line_profiler is used for line-by-line analysis (which can be installed using PIP /conda), and the selected function is marked with a decorator (@profile).

The code was a bit harder this time, because I almost forgot all the Python code, and that was a problem, so I went through it as I went along. I still encountered a lot of problems in coding, but thanks to Baidu and Google, I made it through. In this code project, I also realized the gap between myself and my classmates, and I need to catch up with them in the following projects!

