


183
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享|
The Link Your Class | https://bbs.csdn.net/forums/MUEE308FZ?category=0 |
| The Link of Requirement of This Assignment | https://bbs.csdn.net/topics/600798588 |
| The Aim of This Assignment | extract keywords from C++ code files |
| MU STU ID and FZU STU ID |
19105738-831901221 |
Here is the GitHub repository link for this experiment:
contents
1.Give the PSP form for this work
(3).Design and implementation process
(2)Check the full text for keywords
(3)detect number of "switch" and "case"
(4)detect number of "if- else" and" if-else if -else "
Write in front:
Seriously, this problem is not the least bit different from my initial expectation of difficulty, I always the first programming will be a simple level of the problem. In fact, I thought so when I looked at the problem the night before submitting it, but just like the previous programming problem, it was a design to calculate the number of characters in a TXT file. However, after really thinking about it, I found it was not the same at all, so I did poorly in this assignment.

| Personal Software Process Stage | Estimated Time (minutes) | Actual Time (minutes) |
|---|---|---|
| Planning |
0 |
0 |
| Estimate |
30 |
20 |
|
Development |
0 |
0 |
| Analysis |
30 |
30 |
| Design Spec |
60 |
50 |
| Design Review |
30 |
20 |
| Coding Standard |
30 |
20 |
|
Design |
30 |
30 |
|
Coding |
120 |
180 |
|
Code Review Planning |
30 |
50 |
|
Test |
60 |
120 |
|
Reporting |
30 |
30 |
|
Test Report |
20 |
20 |
|
Size Measurement |
0 |
0 |
|
Postmortem&Process Improvement |
60 |
30 |
|
Total |
500 |
570 |
I'm using Python as the programming language for this one.
Since I hadn't used Python for two semesters, I spent a lot of time reviewing Python functions. Python files handle lines, strings handle lines, and so on.
The first and second requirements are also clear. First of all, we preprocess the imported file, that is, delete the comments of the file. Because keywords will be counted if they are in the file comment. We then use getLines to traverse the entire text, and find to traverse the keywords contained in the file, count+1 if detected.
For the third and fourth requirements, I referred to many students' blogs and got inspiration from them. What I do is I create a list and store the if, else, else if keywords that I detect in that list in that order. Then they play a match-and-match counting game. Specific ideas will be shown later in the code section.
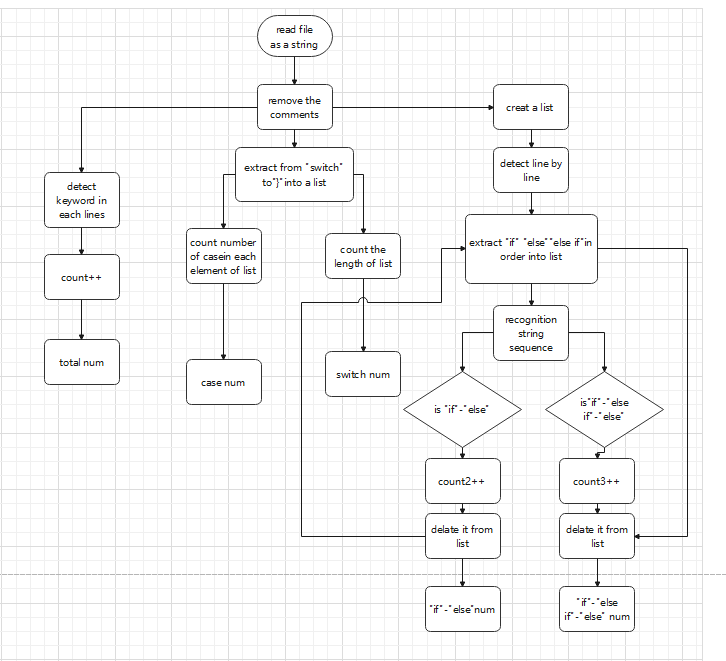
because of '(', ')', '{', '}', ':', ',', '<', '>', '=', '+', '-', '#', ';',Programs can't split code very well.The presence of comments also hinders keyword detection. Therefore, this paper first deleted it
for line in lines:
chars = ['(', ')', '{', '}', ':', ',', '<', '>', '=', '+', '-', '#', ';']
for line in lines:
line = re.sub(r'#.*$', "", line)
line = re.sub(r'//.*', "", line)
line = re.sub(r'".*"', "", line)
line = re.sub(r"'.*'", "", line)
If the text is iterated over each line, the keyword count++ is retrieved, and else if is a separate two-character string that can mislead subsequent operations. So merge them into elIF.
if 'else' in key_line and 'if' in key_line:
lists.append('elif')
count += 2
else:
for word in key_line:
if word in key_word:
count += 1
lists.append(word)
def second(lists):
case_num = []
switch_num = 0
while True:
num = 0
if 'default' in lists:
place = lists.index('default')
switch_num += 1
# the number of switch is equal to the number of deflault
for word in lists[:place]:
if word == 'case':
num += 1
case_num.append(num)
# compute the number of cases in each group
del lists[:place + 1]
else:
break
return case_num, switch_num
def third(lists):
if_else_num = 0
list = []
if_elif_num = 0
for word in lists:
count = 0
if word == 'if':
if_else_num += 1
if word == 'if' or word == 'elif':
list.append(word)
elif word == 'else':
while True:
temp = list.pop()
if temp == 'elif':
count = 1
elif temp == 'if':
break
if count == 1:
if_elif_num += 1
for word in list:
# there still have a situation is that if else if have no else behind
if word == 'if':
if_else_num -= 1
return if_else_num, if_elif_num
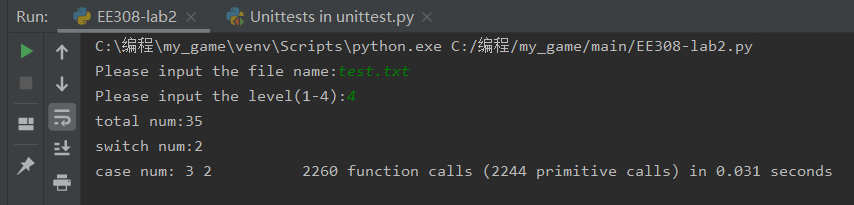
Unit test code as follows:
import unittest
from EE308-lab2 import *
class MyTestCase(unittest.TestCase):
def test_first(self):
with open('test.txt') as C_file:
lines = C_file.readlines()
lists, total_num = first(lines)
self.assertEqual(total_num, 35)
def test_second(self):
with open('test.txt') as C_file:
lines = C_file.readlines()
lists, total_num = first(lines)
case_nums, switch_nums = second(lists[:])
self.assertEqual(case_nums, [3, 2])
def test_third(self):
with open('test.txt') as C_file:
lines = C_file.readlines()
lists, total_num = first(lines)
if_else_nums, if_elif_nums = third(lists[:])
self.assertEqual(if_else_nums, 2)
if __name__ == '__main__':
unittest.main()
2260 function calls (2244 primitive calls) in 0.031 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 :0(__new__)
1 0.000 0.000 0.000 0.000 :0(_getdefaultlocale)
134 0.000 0.000 0.000 0.000 :0(append)
4 0.000 0.000 0.000 0.000 :0(compile)
1 0.000 0.000 0.016 0.016 :0(exec)
8 0.000 0.000 0.000 0.000 :0(extend)
2 0.000 0.000 0.000 0.000 :0(get)
2 0.000 0.000 0.000 0.000 :0(index)
2 0.000 0.000 0.000 0.000 :0(input)
222 0.000 0.000 0.000 0.000 :0(isinstance)
5 0.000 0.000 0.000 0.000 :0(items)
81/73 0.000 0.000 0.000 0.000 :0(len)
20 0.000 0.000 0.000 0.000 :0(min)
1 0.000 0.000 0.000 0.000 :0(open)
7 0.000 0.000 0.000 0.000 :0(ord)
7 0.000 0.000 0.000 0.000 :0(pop)
5 0.000 0.000 0.000 0.000 :0(print)
1 0.000 0.000 0.000 0.000 :0(readlines)
507 0.000 0.000 0.000 0.000 :0(replace)
1 0.000 0.000 0.000 0.000 :0(setdefault)
1 0.016 0.016 0.016 0.016 :0(setprofile)
1 0.000 0.000 0.000 0.000 :0(sort)
507 0.000 0.000 0.000 0.000 :0(split)
156 0.000 0.000 0.000 0.000 :0(sub)
2 0.000 0.000 0.000 0.000 :0(utf_8_decode)
1 0.000 0.000 0.016 0.016 <string>:1(<module>)
1 0.000 0.000 0.016 0.016 EE308-lab2.py:21(first)
1 0.000 0.000 0.016 0.016 EE308-lab2.py:4(fun)
1 0.000 0.000 0.000 0.000 EE308-lab2.py:48(second)
1 0.000 0.000 0.000 0.000 EE308-lab2.py:66(third)
1 0.000 0.000 0.000 0.000 _bootlocale.py:11(getpreferredencoding)
2 0.000 0.000 0.000 0.000 codecs.py:319(decode)
2 0.000 0.000 0.000 0.000 codecs.py:331(getstate)
8 0.000 0.000 0.000 0.000 enum.py:284(__call__)
8 0.000 0.000 0.000 0.000 enum.py:526(__new__)
9 0.000 0.000 0.000 0.000 enum.py:623(name)
1 0.000 0.000 0.000 0.000 enum.py:793(_missing_)
1 0.000 0.000 0.000 0.000 enum.py:800(_create_pseudo_member_)
4 0.000 0.000 0.000 0.000 enum.py:836(__and__)
1 0.000 0.000 0.000 0.000 enum.py:872(_decompose)
1 0.000 0.000 0.000 0.000 enum.py:890(<listcomp>)
1 0.000 0.000 0.031 0.031 profile:0(fun())
0 0.000 0.000 profile:0(profiler)
156 0.000 0.000 0.016 0.000 re.py:185(sub)
156 0.016 0.000 0.016 0.000 re.py:271(_compile)
4 0.000 0.000 0.000 0.000 sre_compile.py:423(_simple)
4 0.000 0.000 0.000 0.000 sre_compile.py:432(_generate_overlap_table)
4 0.000 0.000 0.000 0.000 sre_compile.py:453(_get_iscased)
4 0.000 0.000 0.000 0.000 sre_compile.py:461(_get_literal_prefix)
4 0.000 0.000 0.000 0.000 sre_compile.py:536(_compile_info)
8 0.000 0.000 0.000 0.000 sre_compile.py:595(isstring)
4 0.000 0.000 0.000 0.000 sre_compile.py:598(_code)
8/4 0.000 0.000 0.000 0.000 sre_compile.py:71(_compile)
4 0.000 0.000 0.000 0.000 sre_compile.py:759(compile)
8 0.000 0.000 0.000 0.000 sre_parse.py:111(__init__)
16 0.000 0.000 0.000 0.000 sre_parse.py:160(__len__)
40 0.000 0.000 0.000 0.000 sre_parse.py:164(__getitem__)
4 0.000 0.000 0.000 0.000 sre_parse.py:168(__setitem__)
12 0.000 0.000 0.000 0.000 sre_parse.py:172(append)
8/4 0.000 0.000 0.000 0.000 sre_parse.py:174(getwidth)
4 0.000 0.000 0.000 0.000 sre_parse.py:224(__init__)
20 0.000 0.000 0.000 0.000 sre_parse.py:233(__next)
8 0.000 0.000 0.000 0.000 sre_parse.py:249(match)
16 0.000 0.000 0.000 0.000 sre_parse.py:254(get)
8 0.000 0.000 0.000 0.000 sre_parse.py:286(tell)
4 0.000 0.000 0.000 0.000 sre_parse.py:417(_parse_sub)
4 0.000 0.000 0.000 0.000 sre_parse.py:475(_parse)
4 0.000 0.000 0.000 0.000 sre_parse.py:76(__init__)
8 0.000 0.000 0.000 0.000 sre_parse.py:81(groups)
4 0.000 0.000 0.000 0.000 sre_parse.py:903(fix_flags)
4 0.000 0.000 0.000 0.000 sre_parse.py:919(parse)
9 0.000 0.000 0.000 0.000 types.py:164(__get__)
I benefited a lot from this experiment. First, I reviewed the use of many python functions and the use of Unittest. Then, I also made good use of Github to search for some materials. More importantly, I have a further understanding of software programming, when writing software can not be too hasty, should first analyze the requirements of the topic, judge the possible situation. Then the use of stack also have a further understanding !!!!
All in all, it's done. It was a good experience. I don't want to do it again:( :( :(


