


110
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享10.25
摘要:集合、泛型、上界通配符、下界通配符
是一个接口,不能实例化
Map 集合的泛型由2部分组成,K 和 V。 Map< K ,V > 。例如:MAP< int ,String >
K 是键的类型。 V 是值的类型。
Map 集合将键映射到值的对象。
不能包含重复的键
每个键可以映射最多一个值
实现类: HashMap
| 方法名 | 说明 |
|---|---|
| V put(K key, V value) | 添加元素,将指定的值与该映射中制定的键相关联。 |
| V remove(Object key) | 根据键删除对应元素 |
| void clea() | 移除所有键值对元素 |
| boolean containsKey(Object Key) | 判断集合是否包含制定的键 |
| boolean containsKey(Object Key) | 判断集合是否包含制定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 返回集合长度,即键值对的个数 |
| V get(Object key) | 根据键获取值。如果该键不存在于 Map 中,则返回 null |
| Set <K> keySet() | 获取所有键的集合 |
| Collection <V> values() | 获取所有值的集合 |
| Set<Map.Entry<K,V>>entrySet() | 获取所有键值对对象的集合 |
此类仅由静态方法组合或返回集合。包含对集合进行操作的多态算法。
//将指定的列表升序排列
public static <T extends Compareable<?super T>> void sort(List<T> list);
//反转指定列表中的元素
public static void reverse(List<?> list);
//使用默认的随机源随机排列指定列表
public static void shuffle(List<?> list)
Collector 包含5个参数,传入参数不同,其行为不同。
public interface Collector<T, A, R> {
// supplier参数用于生成结果容器,容器类型为A
Supplier<A> supplier();
// accumulator用于消费元素,也就是归纳元素,这里的T就是元素,它会将流中的元素一个一个与结果容器A发生操作
BiConsumer<A, T> accumulator();
// combiner用于两个两个合并并行执行的线程的执行结果,将其合并为一个最终结果A
BinaryOperator<A> combiner();
// finisher用于将之前整合完的结果R转换成为A
Function<A, R> finisher();
// characteristics表示当前Collector的特征值,这是个不可变Set
Set<Characteristics> characteristics();
Collectors 是一个工具类,是JDK预实现 Collector 的工具类,它内部提供了多种 Collector ,我们可以直接拿来使用,非常方便。
| 方法名 | 功能 |
|---|---|
| toCollection | 将流中的元素全部放置到一个集合中返回 |
| toList | 将流中的元素全部放置到一个 List 中返回,默认为 ArrayList |
| toSet | 将流中的元素全部放置到一个 Set 中返回。默认为 HashMap |
| joining | 将流中的元素以字符串序列的方式连接。可以指定连接符、前后缀 |
| couting | 用于计数 |
泛型是 Java 中另一个使用非常广泛的特性,泛型中的「泛」指的是参数类型不固定,也就是说什么数据类型都可以,它还有另一个名字,就是「参数化类型」——也就是说不仅数据本身是参数,数据类型也可以被指定为参数——类、接口或者方法可以被不同类型的参数所重用。
注意:
作用:在编译阶段约束了操作的数据类型,从而不会出现类型转换异常。
使用了泛型定义的类就是泛型类。
格式:
修饰符 class 类名<泛型变量>{}
定义泛型时,泛型变量一般使用 E、K、T、V、?
通常情况下,E、K、T、V,?是这样约定的:
E(element):代表 Element;
T(type):表示具体的类型;
K/V(key/value):分别代表键值对中的键和值;
? :表示不确定的类型。
使用了泛型定义的方法就是泛型方法。详细用法不再赘述。
使用了泛型定义的接口就是泛型。
Box<Animal> box = new Box<Cat>(new Cat());
如上所示的代码无法通过编译,原因是:Box<Animal> 只接收 Animal 类型的数据,不接收其子类 如<Cat>。 换句话说,Home 就像是一个容器。虽然 Cat 是 Animal 的子类,但这并不代表 Cat 的容器也是 Animal 容器的子类。
?:表示通配符,它无法声明变量,但在泛型中却非常重要,它表示可以持有任何类型,例如:List<?> list,表示 List 集合中可以存放任何数据类型(虽然它本来就可以这么做)。
<? extends T> 是上界通配符,表示只允许 T 及 T 的子类调用,所以如果传入的类型不是 T 或 T 的子类,编译会报错。
<? super T> 是下界通配符,表示只允许 T 及 T 的父类调用,所以如果传入的类型不是T 或 T 的父类,编译会报错。(用的不多)
上界通配符:<? extends Fruit>。
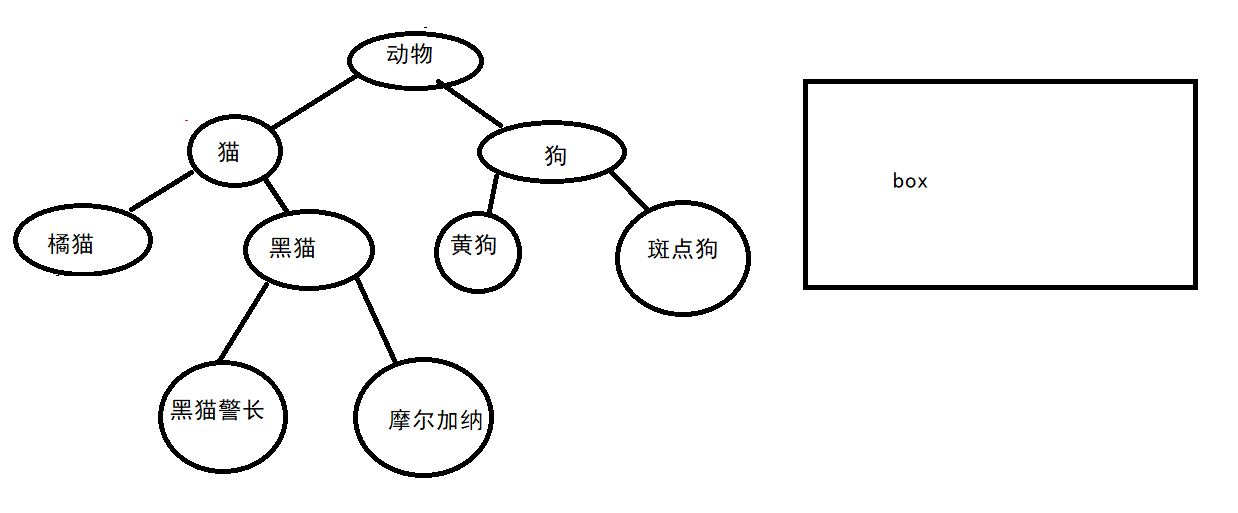
如图所示,假设在代码中有圆圈表示的几个类,其父子关系如图所示。
我们先创建一个用来装猫的盒子对象 box:
Box<? extends Cat> box
现在,这个对象 box 是用来装猫 的,但是我们并不知道这个盒子具体是用来装什么 猫 的,通配符 ? 给我们的信息是:这个盒子什么猫都可以装。
所以我们当然可以用这个盒子来装黑猫:
Box<? extends Cat> box = new Box<BlackCat>(new BlackCat());
同样的,也可以用同样的声明方式来声明两个 盒子 装 橘猫 和 摩尔加纳 。
Box<? extends Cat> box2 = new Box<OrangeCat>(new OrangeCat());
Box<? extends Cat> box3 = new Box<Mona>(new Mona());
如图,上界通配符可以覆盖红圈里的区域。
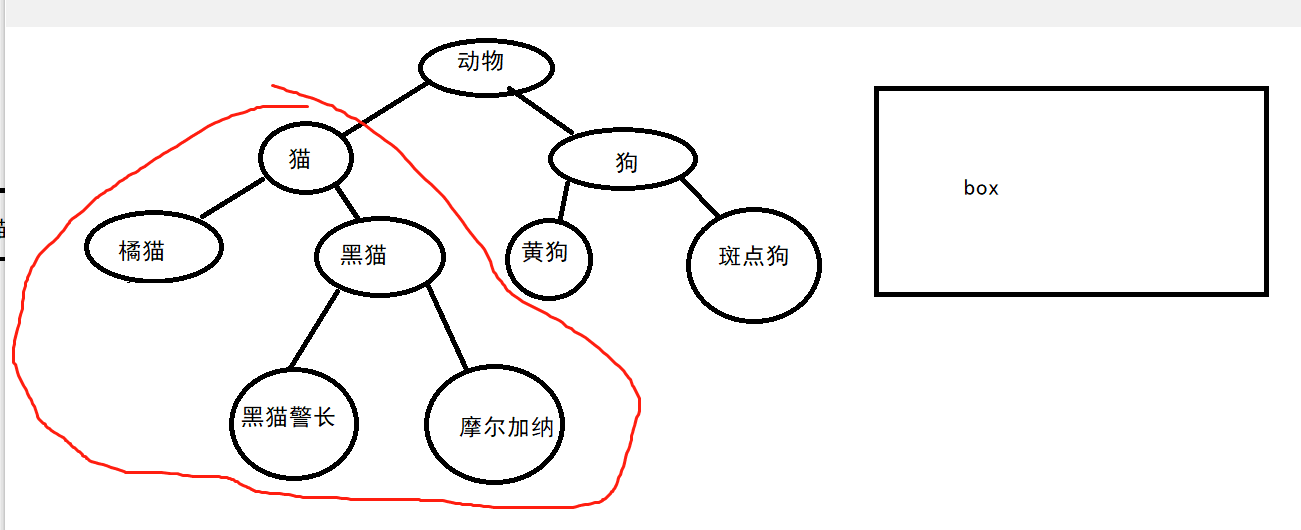
同理,如果我们使用下界通配符 <? super Cat> box 的情况,这个盒子就只能用来装猫类和动物(注意,只能是确切的 Animal 类,不能是其它子类)了。
如图,下界通配符所覆盖的范围如蓝圈所示:
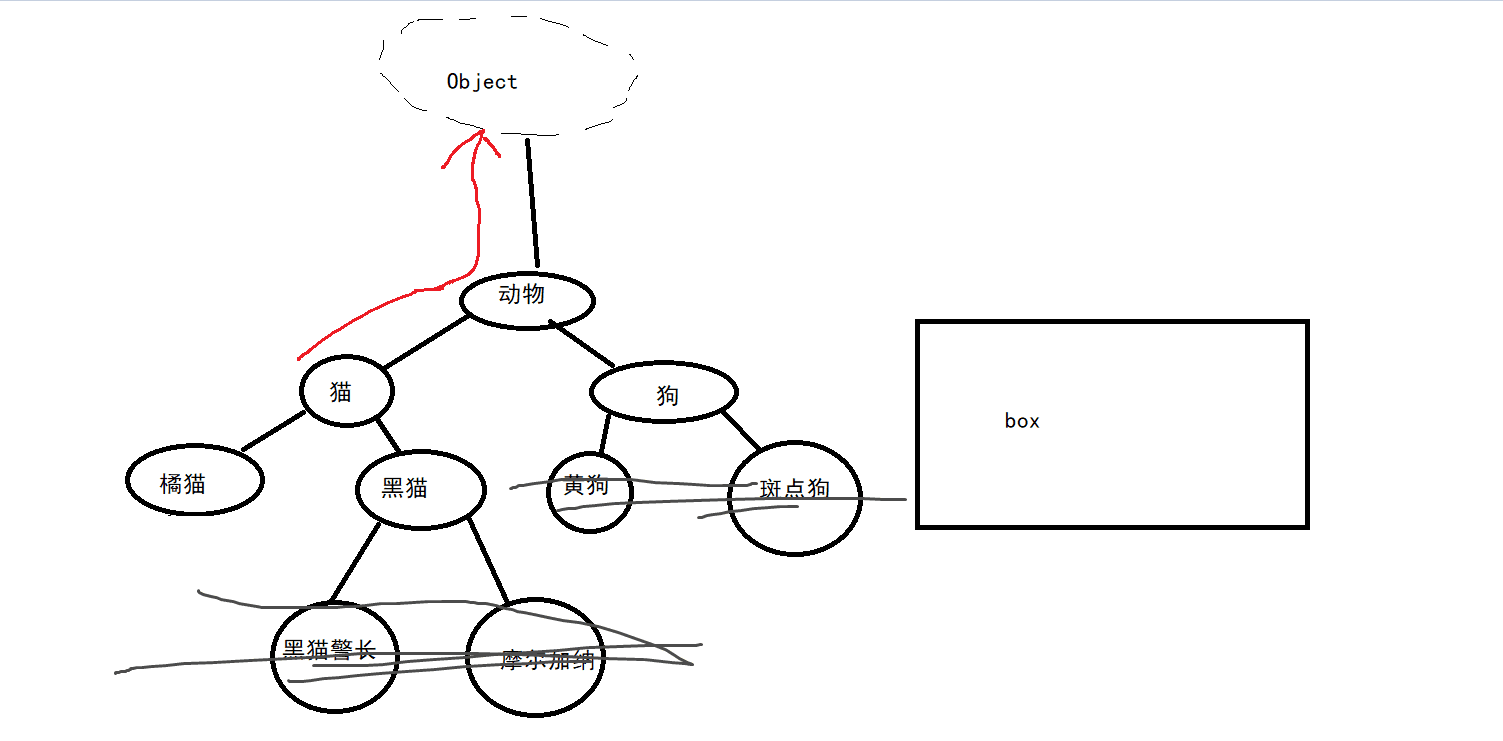
原理:对泛型的识别工作是在编译器层面进行的,而 JVM 则完全无法识别泛型。
在 JVM 中JVM 会对代码进行泛型擦除,即:把 <T> 类型视为 Object。
这个特性,决定了泛型在使用中会有局限:
int;Class,例如:Cat<String>.class;x instanceof Cat<String>;T类型,例如:new T()。ArrayList、Vector 和 LinkedList 都实现了 List 接口,对它们分别进行如下操作后比较它们的不同,然后形成初步耗时报告(三种不同 List 的耗时):
追加元素(追加十万次);
添加元素到任意位置(添加十万次);
分别使用 for 循环、forEach 循环、迭代器进行遍历;
删除任意位置的元素(删除十万次)。
结论:
额外测试:
当不遍历各列表时, List 和 Vector 增、删十万个元素的耗时差不多,为 5200 毫秒左右。
使用 LinkedList 增、删十万个元素耗时较少,为 21 毫秒左右。
附上代码:
package com.xxm.Mission6.Task1;
import java.util.Iterator;
import java.util.ArrayList;
public class Task1_ArrayList {
public static void main(String[] args) {
//开始时间
long startTime = System.currentTimeMillis();
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < 100000; i++) {
list.add(0);
}
for (int i = 0; i < 100000; i++) {
list.add(0, 1);
}
// for循环遍历
// for (int i = 0; i < list.size(); i++) {
// System.out.println(list.get(i));
// }
// //foreach循环遍历
// for (int x : list) {
// System.out.println(x);
// }
// //迭代器遍历
// Iterator it = list.iterator();
// while (it.hasNext()) {
// System.out.println(it.next());
// }
//删除100000次
for (int i = 0; i < 100000; i++) {
list.remove(0);
}
//打印计时
long endTime = System.currentTimeMillis();
System.out.println("程序执行耗时为:" + (endTime - startTime) + "毫秒。");
}
}
HashSet 和 TreeSet 都实现了 Set 接口,对它们分别进行如下操作后比较它们的不同,然后形成初步耗时报告(两种不同 Set 的耗时)。
添加元素(添加十万次);
分别使用 forEach 循环、迭代器进行遍历;
删除任意位置的元素(删除十万次)。
答:
HashSet :
forEach 遍历:688 毫秒。
迭代器遍历 :717 毫秒。
TreeSet :
forEach 遍历:1119 毫秒。
迭代器遍历 :1105 毫秒。
结论:HashSet 耗时稍短于 TreeSet。
附上代码:
package com.xxm.Mission6;
import java.util.TreeSet;
import java.util.HashSet;
import java.util.Iterator;
public class Task2_HashSetAndTreeSet {
public static void main(String[] args) {
//开始时间
long startTime = System.currentTimeMillis();
HashSet<Integer> set = new HashSet<>();
// TreeSet<Integer> set = new TreeSet<>();
//添加100000个元素
for (int i = 0; i < 100000; i++) {
set.add(i);
}
//forEach 循环遍历
for (int x : set) {
System.out.println(x);
}
//迭代器遍历
// Iterator it = set.iterator();
// while (it.hasNext()) {
// System.out.println(it.next());
// }
//删除100000个元素
for (int i = 0; i < 100000; i++) {
set.remove(i);
}
//计时
long endTime = System.currentTimeMillis();
System.out.println("程序执行耗时为:" + (endTime - startTime) + "毫秒。");
}
}
HashMap、TreeMap、LinkedHashMap 和 Hashtable 都实现了 Map 接口,对它们分别进行如下操作后比较它们的不同,然后形成初步耗时报告(两种不同 Map 的耗时):
追加键值对(追加十万次);
替换键值对(替换十万次);
分别使用 entrySet、keySet/values、迭代器进行遍历;
删除键值对(删除十万次)。
答:
结论:HashMap 速度略快于其它三种。其它三种 Map 的速度差不多。
entrySet 遍历和 keySet/values 遍历速度差不多,迭代器遍历速度远低于前两种。
因为迭代器是一种比较普适的方法,所有场合都能使用,而 entrySet 这种就只能在 Map 类中用。就好比问题解决中的算法策略,一定能保证问题解决,但是效率低下。
附上代码:
package com.xxm.Mission6;
import java.util.*;
public class Task3_HashMapTreeMapLinkedHashMapHashtable {
public static void main(String[] args) {
//开始时间
long startTime = System.currentTimeMillis();
//HashMap
// HashMap<Integer, Integer> map = new HashMap<>();
//TreeMap
// TreeMap<Integer, Integer> map = new TreeMap<>();
//LinkedMap
// LinkedHashMap<Integer, Integer> map = new LinkedHashMap<>();
//Hashtable
Hashtable<Integer, Integer> map = new Hashtable<>();
//添加十万对键值对
for (int i = 0; i < 100000; i++) {
map.put(i, i * 2);
}
//替换十万对键值对
for (int i = 0; i < 100000; i++) {
map.put(i, -i);
}
//entrySet 遍历
// System.out.println(map.entrySet());
// //keySet/values 遍历
// System.out.println(map.keySet());
// System.out.println(map.values());
//迭代器遍历
Iterator it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
Object key = entry.getKey();
Object value = entry.getValue();
System.out.println(key + ":" + value);
}
//删除十万对键值对
for (int i = 0; i < 100000; i++) {
map.remove(i);
}
long endTime = System.currentTimeMillis();
System.out.println("程序执行耗时为:" + (endTime - startTime) + "毫秒。");
}
}
上界通配符有一个特性:只能获取,不能添加,请通过搜索引擎了解这句话的含义并用代码实现它。
下界下界通配符有一个特性:只能添加,不能获取,请通过搜索引擎了解这句话的含义并用代码实现它。
答:以这段代码为例:
public class Animal {
}
public class Cat extends Animal {
}
public class BlackCat extends Cat {
}
public class Dog extends Animal {
}
public class Box<T> {
T owner;
public Box(T t) {
owner = t;
}
public void setOwner(T owner) {
this.owner = owner;
}
public T getOwner() {
return owner;
}
}
代码中,声明了5个类:
Animal 类,和它的两个子类 Cat 和 Dog 。
Cat 类的子类:BlackCat 。
Box 类,用来“装”动物。
Box 类中声明了一个泛型的字段:owner 。及其构造、set 和 get 方法。
加入上界通配符,声明一个用来装猫的盒子:
Box<? extends Animal> catBox = new Box<Cat>(new Cat());
试用一下 Box 中的方法:
catBox.getOwner(); //成功编译
catBox.setOwner(new Animal()); //编译错误
catBox.setOwner(new Cat()); //编译错误
报错提示需要传入的类型是 capture of ? extends Animal。
编译器只知道容器内是Fruit或者它的派生类,但具体是什么类型不知道,因此取出来的时候要向上造型为基类。
编译器在看到 Box 后面的上界通配符 <? extends Animal> 后,就给盒子的"标签"上贴了一个占位符,用来表示捕获一个 Animal 的子类,而具体是哪个子类,还不确定。
在这种情况下,要往 Box 里写入数据,必须得写入 capture of ? extends Animal 类型,也就是即将捕获的 Animal 子类的类型,然而在调用写入的方法时是不会把这个占位符具体到某个类型的,因此所有的写入方法都无法使用。
用下界通配符 <? super Cat> 声明一个盒子 catBox2。
Box<? super Cat> catBox2 = new Box<Cat>(new Cat());
试用一下 Box 中的方法:
catBox2.setOwner(new BlackCat());
catBox2.setOwner(new Cat());
OrangeCat cat1 = catBox2.getOwner(); //编译错误
Cat cat2 = catBox2.getOwner(); //编译错误
Animal animal1 = catBox2.getOwner(); //编译错误
Object animal2 = catBox2.getOwner();
编译器只知道容器内是 Cat 类或其父类,但不知道具体是哪个父类,于是就一直往上追溯。我们知道,java 中所有的类都是 Object 类的子类,因此 get 方法得到的数据只能是 Object 类。
请写出通配符 ? 和类型参数 T 的区别,越多越好。
| 区别项 | 通配符 ? | 类型参数 T |
|---|---|---|
| 1 | 表示不确定的某个类型,就好像有一个盒子,你完全不知道里面装了什么东西。即使这一次你从一个 <?> 盒子里拿出了一支笔,下一次从 <?> 盒子里可能会拿出一本书。 | 表示一个特定的类型,但是这个类型还未确定。就好比一个盒子里装了一只笔,但是你不知道它是什么颜色的笔。而且这种指向是一一对应的的,例如,参数 T 对应的笔是黑色,参数 R 对应的笔是红色。这种对应关系确定了就不会更改。 |
| 2 | class<?> 不用具体化,可以直接声明 | class<T> 在实例化时,需要将 T 替换成具体的类 |
| 3 | <?> 单纯的表示这个类型不确定,可能有5个 <?> ,而每个 <?> 的类型不一样。 | 对于编译器来说,所有的 <T> 都是一个类型。例如都是 String |
| 4 | 不能用来声明右边所示的泛型方法,会报错。 | 可以用来定义通用的泛型方法。如 List<T> get(){} |

不错,完成得很认真仔细



