


5,631
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
1. DB:数据库,存储数据的“仓库”。保存了一系列有组织的数据
DBMS:数据库管理系统,数据库通过DBMS创建和操作的容器
SQL:结构化查询语言:专门用来与数据库通信的语言
2. DBMS分为两类:(1)基于共享文件系统的DBMS
(2)基于客户机——服务器的DBMS
3. 卸载mysql时,如果是软件出问题则需要尝试删除注册表【cmd→regist】
4. cmd开启/关闭mysql
net start mysql (启动)
net stop mysql(关闭)
5. cmd链接
mysql -h localhost(连接主机)-P 3306 -u root -p111(密码和-p不能有空格,其他的可以)
6. 常见命令
(1)查看当前所有的数据库
show database;
(2)打开指定的库
use 库名
(3)查看当前库的所有表
show tables;
(4)查看其他库的所有表
show tables from 库名;
(5)创建表
create table 表名(
列名 列表类型,
列名 列表类型
)
(6)查看服务器的版本
方式一:登录到mysql服务端
select version();
方式二:没有登录到mysql服务端
mysql --version 或 mysql --V
7. (1)不区分大小写,但是建议关键字大写,表名、列名小写
(2)每条命令用分号结尾
(3)每条命令根据需要,可以进行缩进或换行
(4)注释 --注释文字 或 #注释文字
8. @[TOC](基础查询)
基础查询:select查询列表 from 表名;
特点:(1)查询列表可以是:表中的字段、常量值、表达式、函数
(2)查询的结果是一个虚拟的表格
```sql
#1.查询表中单个字段
SELECT last_name FROM employees;
#2.查询表中多个字段
SELECT last_name,email FROM employees;
#3.查询表中的所有字段
#方式一:
SELECT
`first_name``last_name``email``phone_number``job_id``salary`
FROM
employees ;
#方式二:
SELECT
*
FROM
employees ;
#4.查询常量值
SELECT 100;
#5.查询表达式
SELECT 100%98;
#6.查询函数
SELECT VERSION();
#7.起别名
/*
(1)便于理解
(2)如果要查询的字段有重名的情况,使用别名可以区分开来
*/
#方式一:使用as
SELECT 100%98 AS 结果;
SELECT last_name AS 姓,first_name AS 名 FROM employees;
#方式二:使用空格
SELECT last_name 姓,first_name名 FROM employees;
#案例:查询salary,显示结果为out put
SELECT salary AS "out put" FROM employees;
#8.去重
#案例:查询员工表中涉及到的所有的部门编号
SELECT DISTINCT department_id FROM employees;
#9.+号的作用
/*
java中的+号:
(1)运算符,两个操作数都为数值型
(2)连接符,只要有一个操作数为字符串
mysql中的+号:
仅仅只有一个功能:运算符
(1)select 100+90;两个操作数都为数值型,则做加法运算
(2)select '123'+90 ;若其中一方为字符型,试图将字符数值型转换为数值型
如果转换成功,则继续做加法运算
select 'john'+90 如果转换失败,则将字符数值转换成0
select null+0; 只要其中一方为null,则结果肯定为null
*/
#案例:查询员工名和姓连接成一个字段,并显示为 姓名
SELECT CONCAT(last_name,first_name) AS 姓名 FROM employees;
#10.显示表departments的结构,并查询其中的全部数据
DESC departments;
SELECT * FROM `department_id`;
```
9. F10 格式化语句
10. 条件查询
语法:select
11. @[TOC](条件查询)
```sql
/*条件查询
语法:select 查询列表 from 表名 where 筛选条件;
分类:
(1)按条件表达式筛选
简单条件运算符:> < = != <> >= <+
(2)按逻辑表达式筛选
逻辑运算符:用于连接条件表达式
&& || ! and or not
&&和and:两个条件都为true,结果都为true,反之都为false
||或or:只要有一个条件为true,结果为true,反之为false
|或not:如果连接的条件本身为false,结果为true,反之为flase
(3)模糊查询
(1)like:
特点:一般和通配符搭配使用
通配符:%任意多个字符,包含0个字符
_ 任意单个字符
(2)between and
特点:包含临界值;使用between and可以提高语句的简洁度;两个临界值不要调换顺序
(3)in
含义:判断某字段的值是否属于in列表中的某一项
特点:使用in提高语句简洁度;in列表的值类型必须一致或兼容
(4)is null
is null:仅仅可以判断null值,可读性较高,建议使用
<=> :既可以判断null值,又可以判断普通的数值,可读性较低
*/
#1.案例1:条件表达式筛选
#案例1:查询工资>12000的员工信息
SELECT
*
FROM
employees
WHERE salary > 12000 ;
#案例2:查询部门编号不对等于90的员工名和部门名
SELECT
last_name,
department_id
FROM
employees #2.逻辑表达式筛选
#案例1:查询工资在10000到20000之间的员工名、工资以及奖金
SELECT
last_name,
salary,
commission_pct
FROM
employees
WHERE salary >= 10000
AND salary <= 20000 ;
#案例2:查询部门编号不在90-10=20之间,或者工资高于15000的员工信息
SELECT
*
FROM
employees
WHERE NOT (
department_id >= 90
AND department_id <= 110
)
OR salary > 15000 ;
#3.模糊查询
#案例1:查询员工名中包含字符a的员工信息
SELECT
*
FROM
employees
WHERE last_name LIKE '%a%' ;
#案例2:查询员工名中第三个字符为e,第五个字符为a的员工名和工资
SELECT
last_name,
salary
FROM
employees
WHERE last_name LIKE '__n_l%' ;
#案例3:查询员工名中第二个字符为_的员工名
SELECT
last_name
FROM
employees
WHERE last_name LIKE '_\_%' ;
# \是转义字符
SELECT
last_name
FROM
employees
WHERE last_name LIKE '_a_%' ESCAPE 'a' ;
#escape指定任意字符为转义字符
#2.between and
#案例1:查询员工编号在100到120之间的员工信息
SELECT
*
FROM
employees
WHERE employee_id >= 100
AND employee_id <= 120 ;
#----------------------------------
SELECT
*
FROM
employees
WHERE employee_id BETWEEN 100
AND 120 ;
#3.in
#案例:查询员工的公众编号是 IT_PROG、AD_PRES中的一个员工名和工种编号
SELECT
last_name,
job_id
FROM
employees
WHERE job_id = 'IT_PROT'
OR job_id = 'AD_VP'
OR JOB_id = 'AD_PRES' ;
#--------------------------------
SELECT
last_name,
job_id
FROM
employees
WHERE job_id IN ('IT_PROT', 'AD_VP', 'AD_PRES') ;
#4.is null
#案例1:查询没有奖金的员工名和奖金率
SELECT
last_name,
commission_pct
FROM
employees
WHERE commission_pct IS NOT NULL
#----------------以下为错
SELECT
last_name,
commission_pct
FROM
employees
WHERE salary IS 12000 ;
#安全等于<=>
#案例1:查询没有奖金的员工名和奖金率
SELECT
last_name,
commission_pct
FROM
employees
WHERE commission_pct <=> NULL ;
#案例2:查询工资为12000的员工信息
SELECT
last_name,
commission_pct
FROM
employees
WHERE salary <=> 12000 ;
```
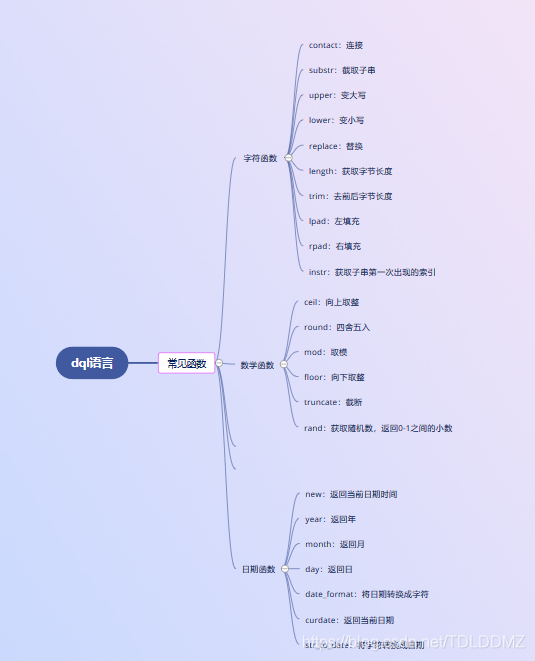
12. @[TOC](常见函数)
```sql
#常见函数
/*
概念:类似于Java的方法,将一组逻辑语句封装在方法体中,对外暴露方法名
好处:1.隐藏了实体细节 2.提高代码的重用性
调用:select函数名(实参列表)【from表】
特点:函数名、函数功能
分类:单行函数:如concat、length、ifnull
分组函数:功能:做单独统计又称为统计函数、聚合函数、组函数
常见函数:
字符函数
length
contact
substr
trim
upper
lower
lpad
rpad
replace
数学函数
round
ceil
floor
truncate
mod
日期函数
now
curdate
curtime
year
month
monthname
day
hour
minute
second
str_to_date
date_format
其他函数
version
datebase
user
控制函数
if else
*/
#一、字符函数
#1.length获取参数值的字节个数
SELECT
LENGTH('jogn') ;
#2.concat拼接字符串
SELECT
CONCAT(last_name, '_', first_name) 姓名
FROM
employees ;
#3.upper、lower统一大小写
SELECT
UPPER( 'john') ;
SELECT
LOWER( 'joHn') ;
#示例:将姓变大写,名为小写,然后拼接
SELECT
CONCAT(UPPER(last_name), LOWER(first_name)) 姓名
FROM
employees ; #4.substr、substring PS:索引从1开始
#截取从指定索引处后面所有字符
SELECT
SUBSTR(
'李莫愁爱上了啦啦啦',
6
) out_put ;
#截取从指定索引处指定字符长度的字节
SELECT
SUBSTR(
'李莫愁爱上了啦啦啦',
1,
3
) out_put ;
#案例:姓名中首字符大写,其他字符小写然后用_拼接,显示出来
SELECT
CONCAT(
UPPER(SUBSTR(last_name, 1, 1)),
'_',
LOWER(SUBSTR(last_name, 2))
) out_put
FROM
employees ;
#5.instr 返回子串第一次出现的索引,如果找不到返回0
SELECT
INSTR('杨不悔爱上了啦啦啦',
'啦啦啦' ) AS out_put FROM employees ;
#6.trim 去掉前后空格或指定内容
SELECT
TRIM(' jjjjjj ') AS out_put ;
SELECT
TRIM(
'a' FROM 'aaaaaaaaaappppaaaappppaaaaaa'
) ;
#7.lpad 用指定的字符实现左填充指定长度
SELECT
LPAD('啦啦啦', 10, '+') AS out_put ;
#8.rpad 用指定的字符实现右填充指定长度
SELECT
RPAD('啦啦啦', 10, '+') AS out_put ;
#9.replace 替换
SELECT
REPLACE('++++ppppppp', '++++', 'aaaa') ;
#二、数学函数
#round 四舍五入
SELECT
ROUND(1.65) ;
#ceil 向上取整,返回>=该参数的最小整数
SELECT
CEIL(- 1.02) ;
#floor 向下取整,返回<=该参数的最大整数
SELECT
FLOOR( - 9.99 ) ;
#truncate 截断
SELECT
TRUNCATE(1.6999, 1) ;
#mod取余
SELECT
MOD(10, 3) ;
#三、日期函数
#now 返回当前系统日期+时间
SELECT
NOW() ;
#curdate 返回当前系统日期不包含时间
SELECT
CURDATE() ;
#curtime 返回当前时间,不包含日期
SELECT
CURTIME() ;
#可以获取hiding的部分,年、月、日、小时、分钟、秒
SELECT
YEAR(NOW()) 年 ;
SELECT
YEAR('1998-1-1') 年 ;
SELECT
YEAR(hiredate) 年
FROM
employees ;
SELECT
MONTH(NOW()) 月 ;
SELECT
MONTHNAME(NOW()) 月 ;
#英文显示月
#str_to_date 将字符通过指定的格式转换成日期
SELECT
STR_TO_DATE('1998-3-2', '%Y-%c-%d') AS out_put ;
#查询入职日期为1992-4-3的员工信息
SELECT
*
FROM
employees
WHERE hiredate = STR_TO_DATE('4-3 1992', '%c-%d %Y') ;
#date_formate 将日期转换成字符
SELECT
DATE_FORMAT(NOW(), '%y年%m月%d日') AS out_put ;
#查询有奖金的员工名和入职日期(xx月/xx日 xx年)
SELECT
last_name,
DATE_FORMAT(hiredate, '%m月/%d日 %y年') 入职日期
FROM
employees
WHERE commission_pct IS NOT NULL ;
#四、其他函数
SELECT
VERSION() ;
#查看版本号
SELECT
DATABASE() ;
#查询数据库
SELECT
USER() ;
#查询当前用户
#五、流程控制函数
#1.if函数:if else 的效果
SELECT
IF(10 > 5, '大', '小') ;
SELECT
last_name,
commission_pct,
IF(
commission_pct IS NULL,
'无',
'有'
)
FROM
employees ;
#2.case函数的使用一:switch case 的效果
/*
Java中
switch(变量或表达式){
case变量1:语句1:break;
.....
default:语句n;break;
}
MySQL中
case 要判断的字段或表达式
when 常量1 than 要显示的值1或语句1;
when 常量2 than 要显示的值1或语句2;
......
else 要显示的值
end
*/
/*案例:查询员工的工资,要求
部门号=30,显示为原工资的1.1倍
部门号=40,显示为原工资的1.2倍
部门号=50,显示为原工资的1.3倍
其他部门,显示的工资为原工资
*/
SELECT
salary 原始工资,
department_id,
CASE
department_id
WHEN 30
THEN salary * 1.1
WHEN 30
THEN salary * 1.2
WHEN 30
THEN salary * 1.3
ELSE salary
END AS 新工资
FROM
employees #3.case 函数的使用二:类似于 多重if
/*
Java中
if(条件1){
语句1;
}else if(条件2){
语句2;
}
.....
else{
语句n;
}
mysql中
case
when 条件1 then 要显示的值1或语句1;
when 条件2 then 要显示的值1或语句2;
.....
else 要显示的值n或语句n;
end
*/
SELECT
salary,
CASE
WHEN salary > 20000
THEN 'A'
WHEN salary > 15000
THEN 'B'
WHEN salary > 10000
THEN 'C'
ELSE 'D'
END AS 工资级别
FROM
employees
#二、分组函数
/*
功能:用作统计使用,又称为聚合函数或统计函数或组函数
分类:
sum求和、avg平均数、max最大值、min最小值、count计算个数
特点:
1.sum、avg一般用于处理数值型
max、min、count可以处理任何类型
2.是否忽略null值 (max、min、sum、avg忽略null值)
3.可以和distinct搭配实现去重的运算
4.count函数的单独介绍
一般使用count(*)用做统计行数
5.和分组函数一同查询的字段要求是group by后的字段
*/
#1.简单使用
SELECT SUM(salary) FROM employees;
SELECT AVG(salary) FROM employees;
SELECT MIN(salary) FROM employees;
SELECT MAX(salary) FROM employees;
SELECT COUNT(salary) FROM employees;
SELECT SUM(salary)和,AVG(salary) 平均,MIN(salary) 最小,MAX(salary) 最大,COUNT(salary) 个数
FROM employees;
#2.参数支持哪些类型
#3.是否忽略null值
#4.和distinct搭配
SELECT SUM(DISTINCT salary),SUM(salary) FROM employees;
SELECT COUNT(DISTINCT salary) ,COUNT(salary) FROM employees;
#5.count函数的详细介绍(计数)
SELECT COUNT(salary)FROM employees;
SELECT COUNT(*) FROM employees;
/*
效率
MYISAM存储引擎下,count(*)的效率高
INNODB存储引擎下,count(*)和count(1)的效率差不多,比count(字段)要高一些
*/
#6.和分组函数一同查询的字段有限制
SELECT AVG(salary),employee_id FROM employees;
#分组查询
/*
语法:
select 分组函数,列(要求出现在group by的后面)
from 表
【where 筛选条件】
【group by 分组的列表】
【order by 子句】
注意:
查询列表必须特殊,要求是分组函数和group by后出现的字段
特点:1.分组查询中的筛选条件分为两类
数据源 位置 关键字
分组前筛选 原始表 group by 子句的前面 where
分组后筛选 分组后的结果集 group by 子句的后面 having
(1)分组函数做条件肯定放在having子句中
(2)能用分组前筛选的,就优先使用分组前筛选
2.group by子句支持单个单个字段分组、多个字段分组(多个字段之间用逗号隔开没有顺序要求),表达式或函数(用的较少)
3.也可以添加排序
*/
#引入:查询每个部门的平均工资
SELECT AVG(salary) FROM employees;
#案例1:查询每个工种的最高工资
SELECT MAX(salary),job_id
FROM employees
GROUP BY job_id;
#添加分组前筛选条件
#案例1:查询邮箱中包含a字符的每个部门的平均工资
SELECT department_id,AVG(salary)
FROM employees
WHERE email LIKE '%a%'
GROUP BY department_id;
#案例2:查询有奖金的每个领导手下员工的最高工资
SELECT MAX(salary),manager_id
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY manger_id;
#添加分组后复杂的筛选条件
#案例1:查询哪个部门的员工个数>2
#(1)查询每个部门的员工个数
SELECT COUNT(*),department_id
FROM employees
GROUP BY department_id;
#(2)根据1的结果进行筛选,查询哪个部门的员工个数>2
SELECT COUNT(*),department_id
FROM employees
GROUP BY department_id
HAVING COUNT(*)>2;
#HAVING 子句可以筛选分组后的各组数据。
#案例2:查询每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
SELECT job_id,MAX(salary)
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary)>12000;
#案例3:查询领导编号>102的每个领导手下的最低工资>5000的领导编号是哪个,以及其最低工资
SELECT manager_id,MIN(salary)
FROM employees
WHERE manager_id>102
GROUP BY manager_id
HAVING MIN(salary)>5000;
#按表达式或函数分组
#案例:按员工姓名的长度分组,查询每一组的员工个数,筛选员工个数>5的有哪些
SELECT COUNT(*) c,LENGTH(last_name) len_name
FROM employees
GROUP BY len_name
HAVING c>5;
#按多个字段分组
#案例:查询每个部门每个工种的员工的平均工资
SELECT AVG(salary),department_id,job_id
FROM employees
GROUP BY department_id,job_id;
#添加排序
SELECT AVG(salary),department_id,job_id
FROM employees
GROUP BY job_id,department_id
ORDER BY AVG(salary) DESC;
```
13. @[TOC](连接查询)
```sql
#连接查询
/*
含义:又称多表查询,当查询的字段来自于多个表时,就会用到连接查询
笛卡尔乘积现象:表1 有m行 表2有n行,结果=n*m行
发生原因:没有有效的连接条件
如何避免:添加有效的连接条件
分类:
按年代分类
sq192标准
sq199标准【推荐】:支持内连接+外连接(左外和右外)+交叉连接
按功能分类
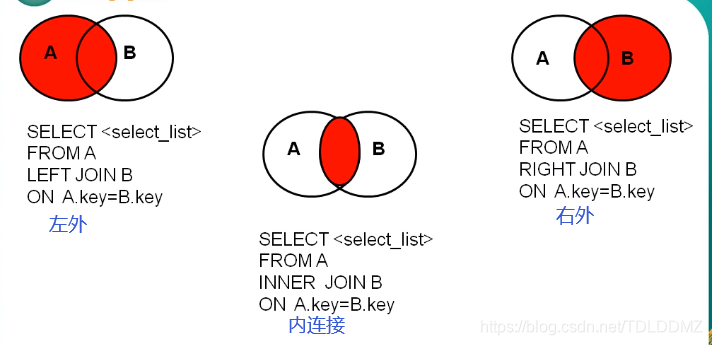
内连接:
等值连接
非等值连接
自连接
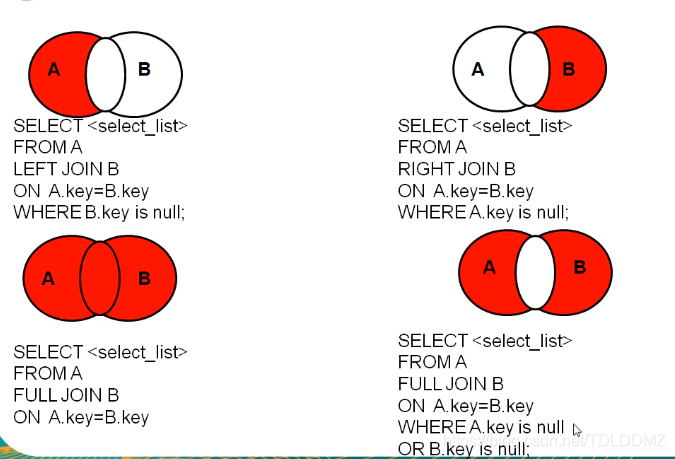
外连接:
左外连接
右外连接
全外连接
交叉连接
*/
#一、sql192标准
#1.等值连接
/*
(1)多表等值连接的结果为多表的交集部分
(2)n表连接,至少需要n-1个连接条件
(3)多表的顺序没有要求
(4)一般需要为表起别名
(5)可以搭配前面介绍的所有子句使用
*/
#案例1:查询女神名和对应的男神名
SELECT
NAME,
boyName
FROM
boys,
beauty
WHERE `beauty`.`boyfriend_id` = boys.id ;
#2.为表起别名
/*
提高语句的简介度
区分多个重名的字段
*/
#查询员工名、工种号、工种名
SELECT
last_name,
e.`job_id`,
`job_title`
FROM
`employees` e,
`jobs` j
WHERE `e`.`job_id` = j.`job_id` ;
#3.两个表的顺序可以互换
SELECT
last_name,
e.`job_id`,
`job_title`
FROM
`jobs` j , `employees` e
WHERE `e`.`job_id` = j.`job_id` ;
#4.可以加筛选
#查询有奖金的员工名、部门名
SELECT last_name,department_name
FROM departments d,employees e
WHERE e.`department_id`=d.`department_id`
AND e.`commission_pct` IS NOT NULL
#5.可以加分组
#查询每个城市的部门个数
SELECT COUNT(*) 个数 ,city
FROM departments d,`locations` l
WHERE d.`location_id`=l.`location_id`
GROUP BY city;
#6.可以加排序
#2.非等值连接
#3.自连接
#查询员工名和上级的名称
SELECT e.`employee_id`,e.`last_name`,m.`employee_id`,m.`last_name`
FROM employees e,employees m
WHERE e.`manager_id`=m.`employee_id`;
#4.全连接:查主表和附表不相同的部分
#全连接=内连接的结果+表1中有单表2中没有的+表2中有但表1中没有的
USE girls;
SELECT b.*,bo.*
FROM `beauty` b
FULL OUTER JOIN `boys` bo
ON b.`boyfriend_id`= bo.id
#5.交叉连接:结果行数等于两表进行笛卡尔乘积
SELECT b.*,bo.*
FROM beauty b
CROSS JOIN boys bo
/*sql92和sql99
功能:sql99支持的较多
可读性:sql99实现连接条件和筛选条件的分离,可读性较高*/
```
14. @[TOC](子查询)
```sql
/*
1.含义:出现在其他语句中的select语句,称为子查询或内查询
外部的查询语句,成为主查询或外查询
2.分类
案子查询出现的位置:
select后面:仅仅支持标量子查询
from后面:支持表子查询(要求将子查询结果充当一张表,要求必须起别名)
☆where或having后面:
标量子查询(单行子查询)
行子查询(用的少) (多列多行)
列子查询(多行子查询)
操作符 含义
IN/NOT IN 等于列表中的任意一个
ANY/SOME 和子查询返回的某一个值比较
ALL 和子查询返回的所有值比较
exists后面(相关子查询):表子查询
语法:exists(完整的查询语句)
结果:1或0
案结果集的行列数不同:
标量子查询(结果集只有一行一列)
列子查询(结果集只有一行多列)
行子查询(结果集有一行多列)
表子查询(结果集一般为多行多列)
3.特点:
(1)子查询放在小括号内
(2)子查询一般放在条件的右侧
(3)标量子查询,一般搭配着单行操作符使用
单行操作符:>,<,>=,<=,<>
列子查询,一般搭配着多行操作符使用
(4)子查询的执行优先于主查询执行,主查询的条件用到了查询的结果
*/
#一、where和having后面
#1.标量子查询
#(1)标量子查询
#案例:
SELECT last_name,job_id,salary
FROM employees
WHERE job_id=(
SELECT job_id
FROM employees
WHERE employee_id=141
)AND salary>(
SELECT salary
FROM employees
WHERE employee_id=143
)
#(2)非法使用标量子查询
#2.多行子查询
#案例:返回其他部门中比job_id为‘IT_PROG’部门任意工资低的员工的员工号、姓名、job_id以及salary
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE salary <ANY(
SELECT MIN(salary)
FROM employees
WHERE job_id='IT_PROG'
)AND job_id<>'IT_PROG';
#3.行子查询
SELECT *
FROM employees
WHERE (employee_id,salary)=(
SELECT MIN(employee_id),MAX(salary)
FROM employees
);
#二、放在select后面
#案例:查询每个部门的员工个数
SELECT d.*,(
SELECT COUNT(*)
FROM `employees` e
WHERE e.department_id =d.employee_id
)个数
FROM employees d;
#三、from后面
#案例:查询每个部门的平均工资的工资等级
SELECT ag_dep.*,g.grade_level
FROM (
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
)ag_dep
INNER JOIN job_grades g
ON ag_dep.ag BETWEEN lowest_sal AND highest_sal;
#四、exists后面(相关子查询)
#案例:查询没有女朋友的男神信息
SELECT bo.*
FROM boys bo
WHERE NOT EXISTS(
SELECT *
FROM `beauty` b
WHERE b.`boyfriend_id`=bo.`id`
);
SELECT bo.*
FROM boys bo
WHERE bo.`id` NOT IN(
SELECT boyfriend_id
FROM beauty
)
```



