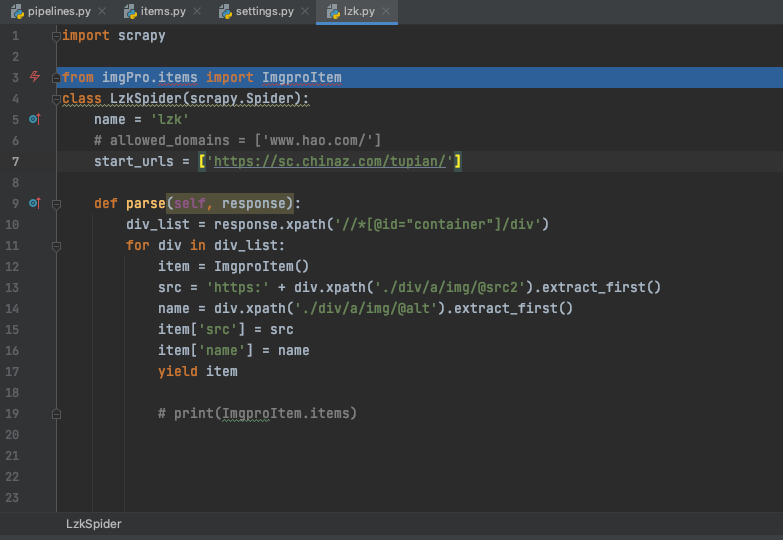
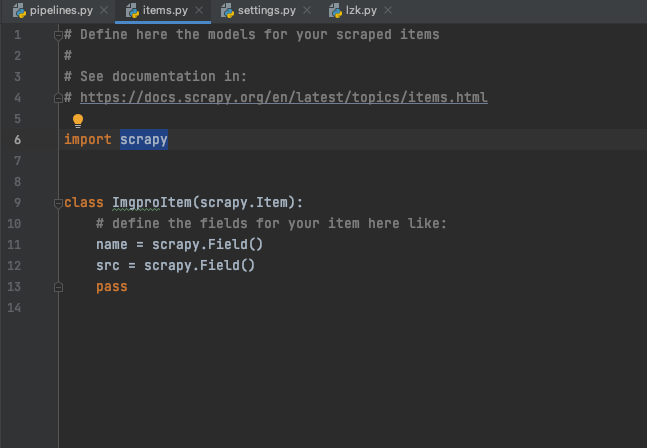
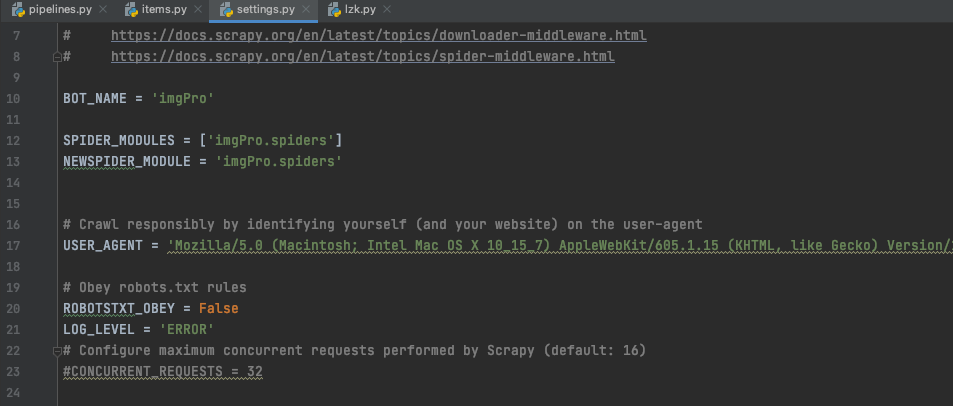
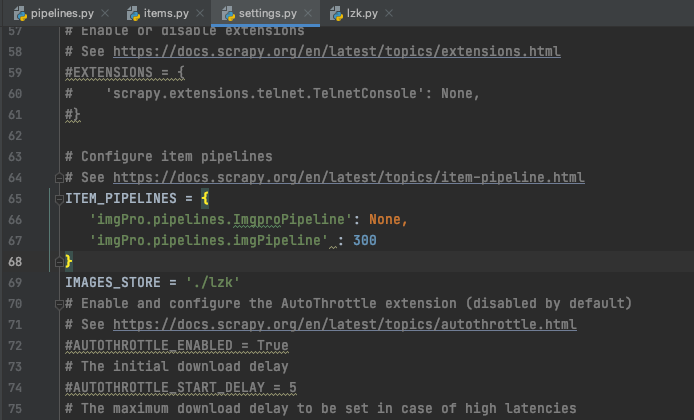
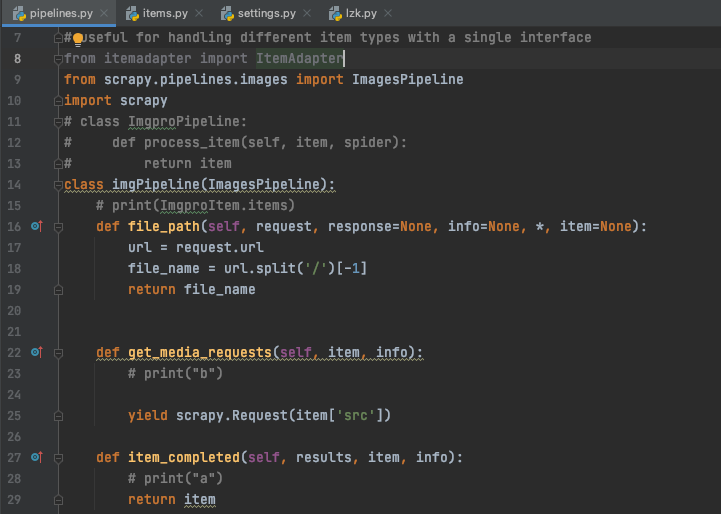
我用scrapy爬取图片 没有报错 没有输出 甚至连文件夹都没有创建,我仔细看了一下,发现管道开启了,robot也设置为假,UA写了,就是不知道是什么问题,忘大佬解答
xpath那里写错了,你提取src属性的时候写的是src2 。
另外下载图片时部分网站需要添加Referer和User-Agent。
这种情况最好是debug调试,或者通过print进行流程打印。
26,343
社区成员
421
社区内容
加载中
一个综合的爬虫逆向技术交流社区
试试用AI创作助手写篇文章吧




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享