222
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
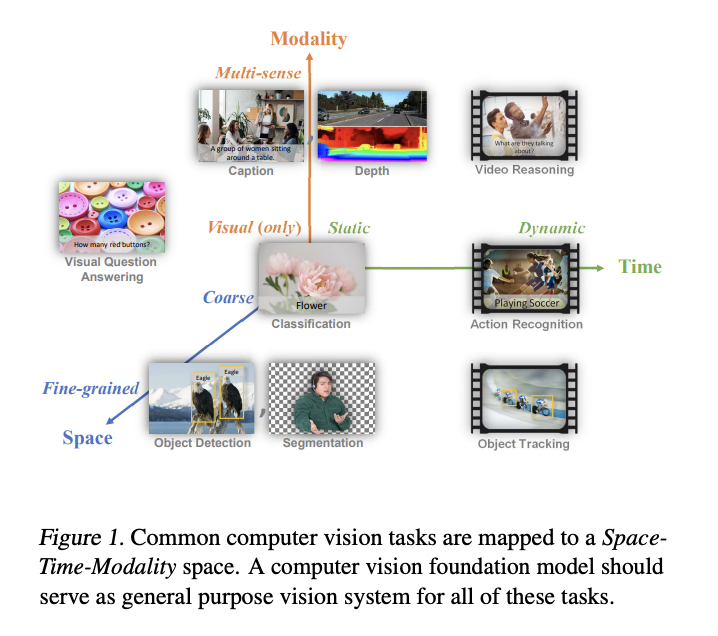
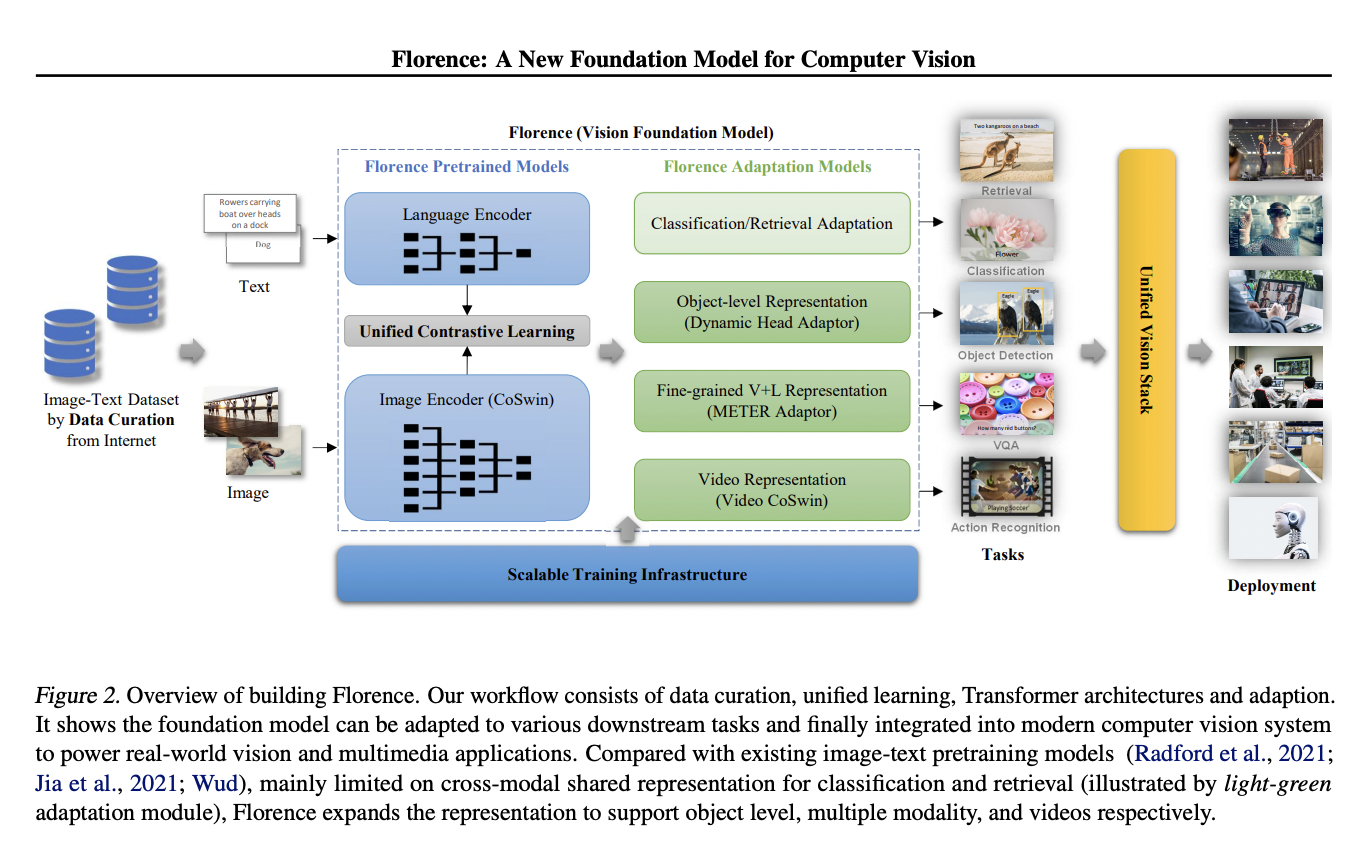
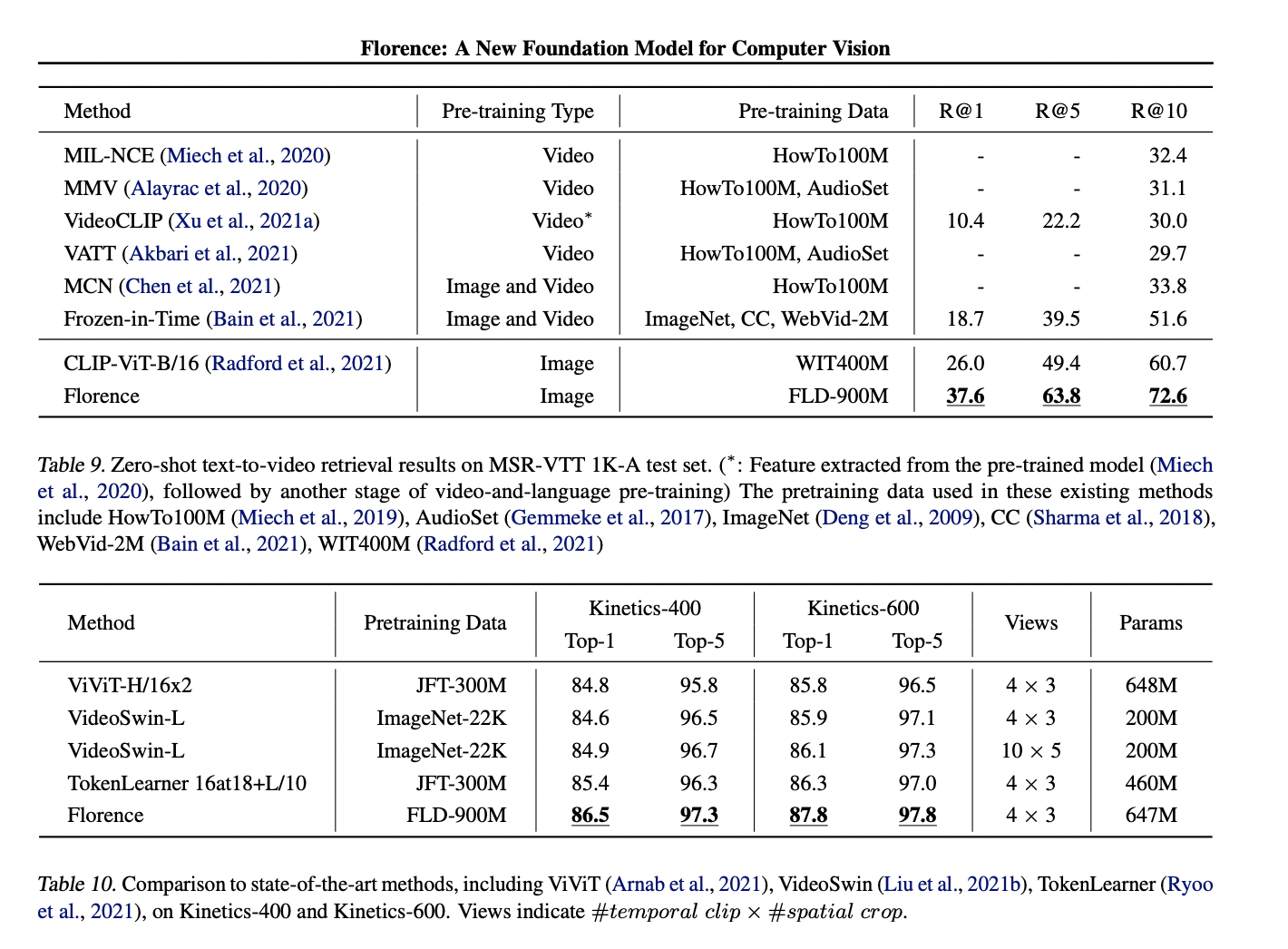
分享#一种新的计算机视觉基础模型Florence# 现有的视觉基础模型如CLIP、ALIGN和#悟道2.0# 侧重将图像和文本表示映射到跨模态共享表示,但最新一篇由23位研究人员完成的论文中提出了一个新的#计算机视觉# 基础模型Florence,将表示扩展到粗略(场景) 到精细(目标),从静态(图像)到动态(视频),从RGB到多种模式(标题、深度)。通过结合来自Web规模图像文本数据的通用视觉语言表示,#Florence# 模型可以轻松适应分类、检索等各种计算机视觉任务。Florence在许多类型的迁移学习中表现出出色的性能,目前在44个具有代表性的基准测试中达到最新SOTA。论文:https://arxiv.org/pdf/2111.11432.pdf