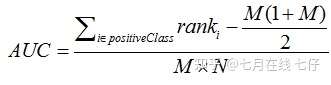70
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享L1/L2的区别
L2是模型各个参数的平方和的开方值。
因为最优的参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0 ,产生稀疏权重矩阵
L2会选择更多的特征,这些特征都会接近于0。
最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每一项趋近于0。
L1的作用是为了矩阵稀疏化。假设的是模型的参数取值满足拉普拉斯分布。
L2的作用是为了使模型更平滑,得到更好的泛化能力。假设的是参数是满足高斯分布。
leetcode704,搜索区间两端闭,while条件带等号,mid要加减1。
代码:
Pythonclass Solution:
def search(self, nums: List[int], target: int) -> int:
left = 0
right = len(nums) - 1
while left <= right:
mid = left + (right - left)//2
if nums[mid] == target:
return mid
elif nums[mid] < target:
left = mid + 1
elif nums[mid] > target:
right = mid - 1
return -1
时间复杂度:O(logN)。
空间复杂度:O(1)。
该题为leetcode153题:数组不包含重复元素,并且只要当前的区间长度不为 1,pivot 就不会与 high 重合;而如果当前的区间长度为 1,这说明我们已经可以结束二分查找了。因此不会存在nums [ pivot ] = nums [ high ] 的情况。
当二分查找结束时,我们就得到了最小值所在的位置。
代码:
Pythonclass Solution:
def findMin(self, nums: List[int]) -> int:
low, high = 0, len(nums) - 1
while low < high:
pivot = low + (high - low) // 2
if nums[pivot] < nums[high]:
high = pivot
else:
low = pivot + 1
return nums[low]
信息增益,信息增益率,基尼指数
信息增益是以某特征划分数据集前后的熵的差值,熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。
AUC是ROC曲线下面的面积,AUC可以解读为从所有正例中随机选取一个样本A,再从所有负例中随机选取一个样本B,分类器将A判为正例的概率比将B判为正例的概率大的可能性。AUC反映的是分类器对样本的排序能力。AUC越大,自然排序能力越好,即分类器将越多的正例排在负例之前。
公式如下: