

571
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享知识图谱技术是人工智能技术的重要组成部分,其建立的具有语义处理能力与开放互联能力的知识库,可在智能搜索、智能问答、个性化推荐等智能信息服务中产生应用价值。针对政策文件的知识图谱构建和知识提取应用于智慧城市或智慧政策领域,有效抓取文件中的关键信息,提高政策文件分析的效率。
政策:政策是国家政权机关、政党组织和其他社会政治集团为了实现自己所代表的阶级、阶层的利益与意志,以权威形式标准化地规定在一定的历史时期内,应该达到的奋斗目标、遵循的行动原则、完成的明确任务、实行的工作方式、采取的一般步骤和具体措施。 政务文件:指政府的事务性工作中的文件,除了政策文件外还包含职务任免、工作报告、奖励表彰等多种文件。
1)关于战略规划方面的意见、纲要、通知: 以《国务院办公厅关于印发“十四五”全民医疗保障规划的通知》这条政策为例,全民医保是国务院提出的战略规划,这条战略规划又对医保体系制度提出要求,依次类推,总体可以划分为层级结构。
2)批复、通报、函:在这类政策公文中,文件篇幅较短,实体与实体关系明确。
3)成立部门通知:该类文件极少,实体与实体关系明确。
4)条例、法规:不适合构建知识图谱
5)政策解读文件:不适合构建知识图谱,建议通过解读文件对知识图谱进行人工调整;或者结合对应的政策文件知识图谱编写问答对,构建政策解读专家系统。
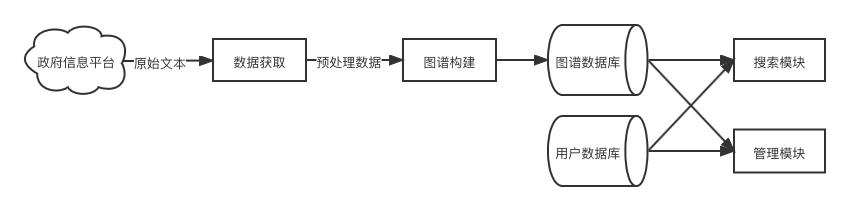
系统共由四大模块组成,分别是数据采集模块、图谱构建模块、搜索模块、管理模块。
由于该项目的主要研究目标在于图谱构建模块中政策领域的实体识别和关系抽取算法的研究,并不是以开发一个系统的落地项目为出发点,所以在需求分析中并不刻意强调作为一个系统的完备性和可靠性,而是从用户搜索、管理员管理两个方面的基本功能出发,分析政策图谱需完成的工作。
通过管理员或用户所输入的网页网址,自动爬取相应的网站数据,并通过预处理程序根据不同文本间的层次差异进行预处理,得到半结构化的数据作为图谱构建模块的输入。
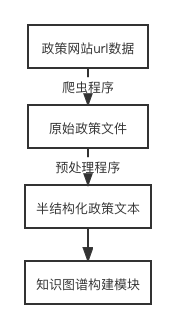
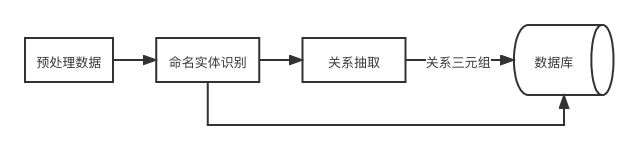
命名实体识别检测语句中具有特定含义的实体,借助适当的方法判定实体的边界和类别,关系抽取在实体识别的基础上,从数据中抽取出关系三元组,存入数据库。
该模块主要根据用户的需求展示数据。
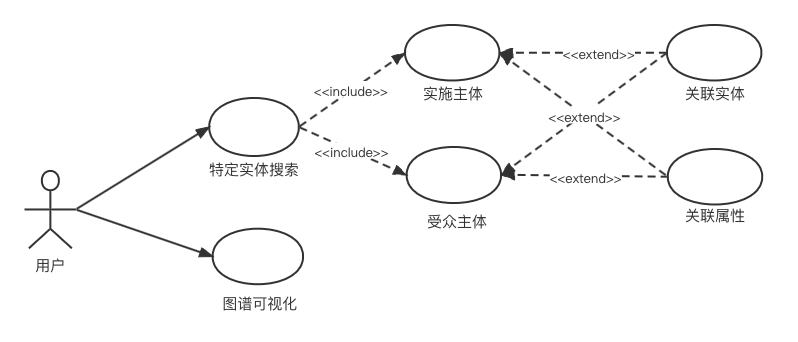
用户在平台上进行搜索时,分为通过图谱可视化在宏观上对政策重心进行分析、通过特定实体搜索关注某一具体实体的关联政策措施属性。根据用户身份的不同也要区分实施主体(如医疗部门等政策实施单位)、受众实体(如医疗企业等受措施影响的行业群体),搜索功能用例图如图所示。
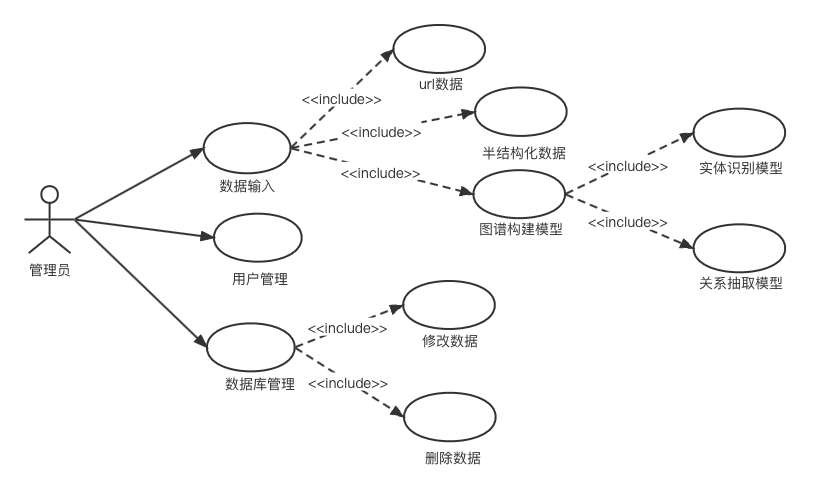
该模块主要对系统数据进行管理。
管理员在系统中是作为管理者,主要可以对系统中的数据进行管理,如增加原始数据、更换图谱构建模块中使用的模型、对输入到数据库中关系三元组进行筛查、修改错误数据。同时管理员应当可以在系统中对系统用户进行管理,对出现违规的用户进行封禁等。管理功能用例图如图所示。
总体可以划分为层级结构,顶层设计如图所示
| 政策文件层次体系解析 |
|---|
| 政策发布主体 |
| 总体规划 |
| 各管理体系 |
| 各项应对机制、制度 |
| 各项具体措施 |
| 涉及的行业群体实体 |
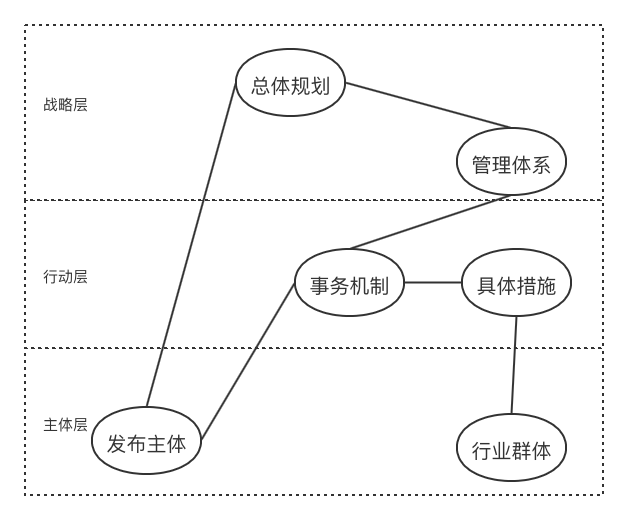
战略层:该层主要包括总体规划、管理体系两类实体,特点是基于宏观战略部署,在不同的政策文件中可能相互关联,作为政策知识图谱中的主要连接点
行动层:该层主要包括应对机制、具体措施等实体,涉及具体事务问题,将战略与群体层相互连接,并将详细的做法作为行动层实体的属性。
群体层:该层主要包括政策发布主体和涉及的行业群体实体,发布主体体现出政策的效力范围,行业群体实体则是政策的最终受众。
总体要求与基本原则等实体、属性直接与战略层实体相关联,无需单独建层。
具体的实施步骤并不建立新实体,而是作为措施实体的属性。
本项目系统框架如图所示,数据获取采用python的scrapy框架,图谱构建使用Bert等深度学习模型,数据库方面基于知识图谱的特性,使用Neo4j图数据库存储关系三元组,使用传统的关系型数据库Mysql存储用户信息,并通过搜索模块进行前端展示。
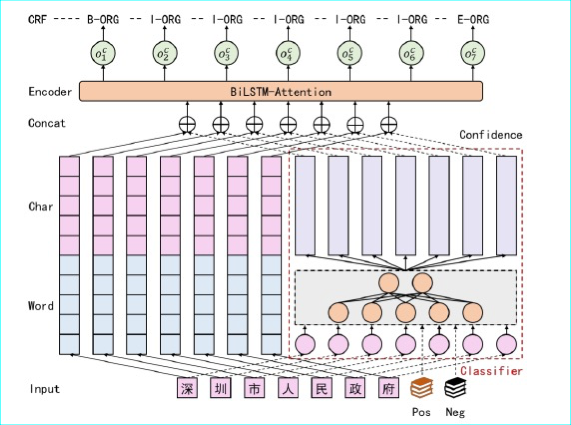
由于政策文本中构成实体的词汇具有明显的公文特色,且其数量有限,因此本项目计划采用基于正负类词典的预训练分类机制,为语句中的所有字符生成置信度参数。然后借助 BiLSTM 提取上下文特征,与 Attention 机制相结合,从而为不同特征分配适宜的权重参数,完成向量编码过程。最终通过 CRF 模型对标签序列之间的依赖关系建模,从而识别政务文本中的实体边界和类别。
该模型整体结构可划分为3 层:输入层、编码层和解码层。
输入层:由字符嵌入、词嵌入和置信度参数三部分构成。字符嵌入向量和词嵌入向量通过 SoftLexicon 编码机制获得,置信度参数通过预训练分类模块得到,将其与字符嵌入、词嵌入向量串联,作为下游模型的输入。
编码层:由BiLSTM 模块和 Attention 机制两部分构成。使用 BiLSTM 提取语句中的上下文特征,实现双向信息融合。借助 Attention 机制对各个向量进行加权求和,学习全局信息对各个字符的影响。
解码层:使用 CRF 模块,通过维特比算法输出转移概率最大的预测序列,即可求解实体的边界和类别。
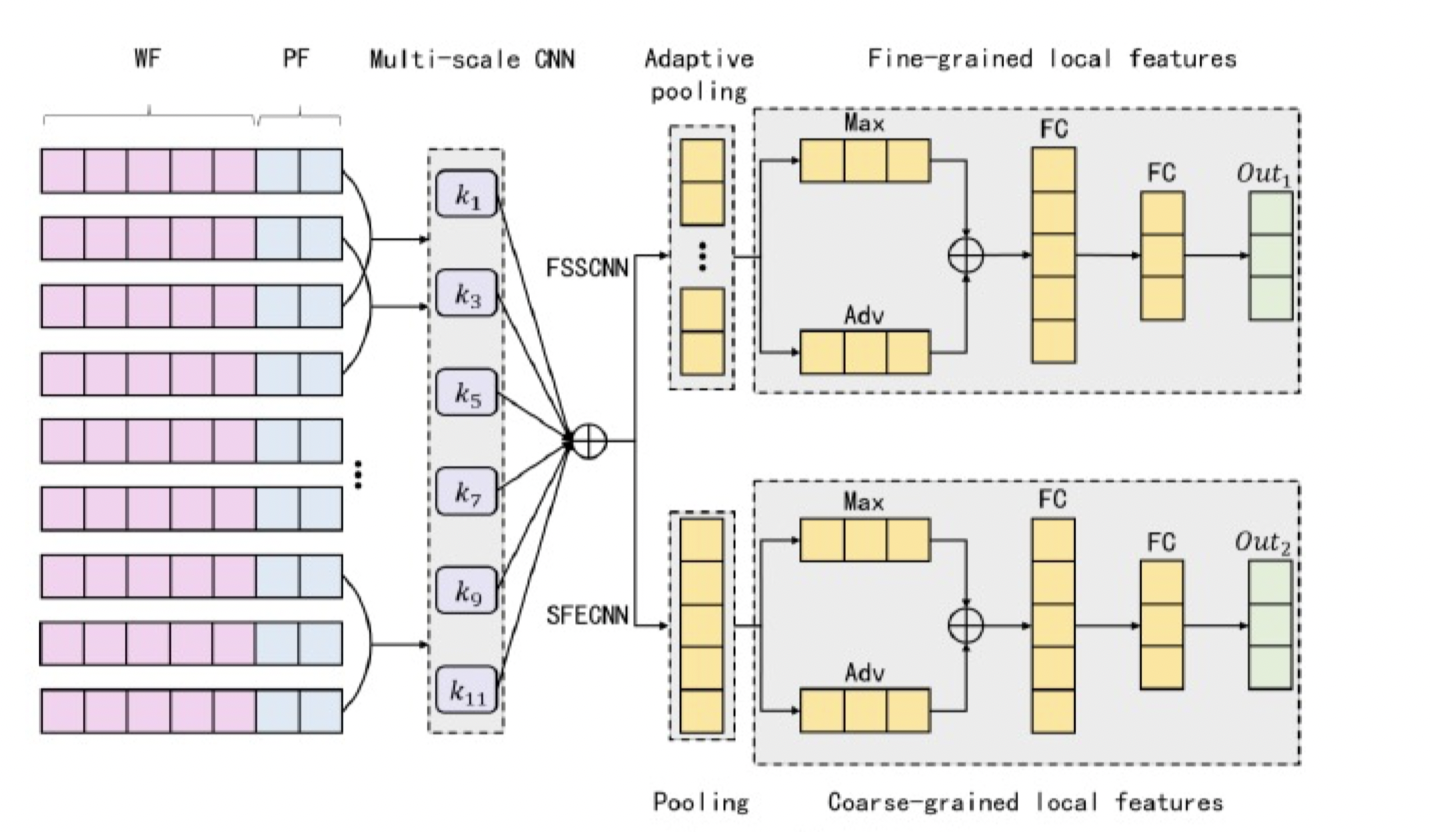
由于政策文本中存在大量并列、包含结构的实体对,且实体对之间分布集中、关系相同、跨度不同,为了更好地提取文本局部特征,保留局部特征的次序信息,本项目计划实现局部特征增强,改善关系抽取任务中的特征提取效果。
常用的关系抽取方法在提取局部特征时,常将卷积操作所得向量输入到最大池化层中,提取文本中最显著的特征。然而该种特征提取方式无法保留特征与输入序列之间的相对位置关系,造成了不必要的信息损失。
为了弥补现有方案的不足,保留特征组合的次序信息,通过FSSCNN结构,对多尺度卷积的计算结果执行自适应池化操作,即在输入序列的多个维度上进行切分,然后对各个子向量分别执行最大池化和平均池化操作,即可保留各个子向量中所含特征的次序信息。
为了在丰富的文本特征中筛选出主要信息,借助SFECNN网络计算局部特征,用于捕获整个序列维度上的文本特征,不再切分子向量,而是对整个维度度的数据执行最大池化和平均池化操作。
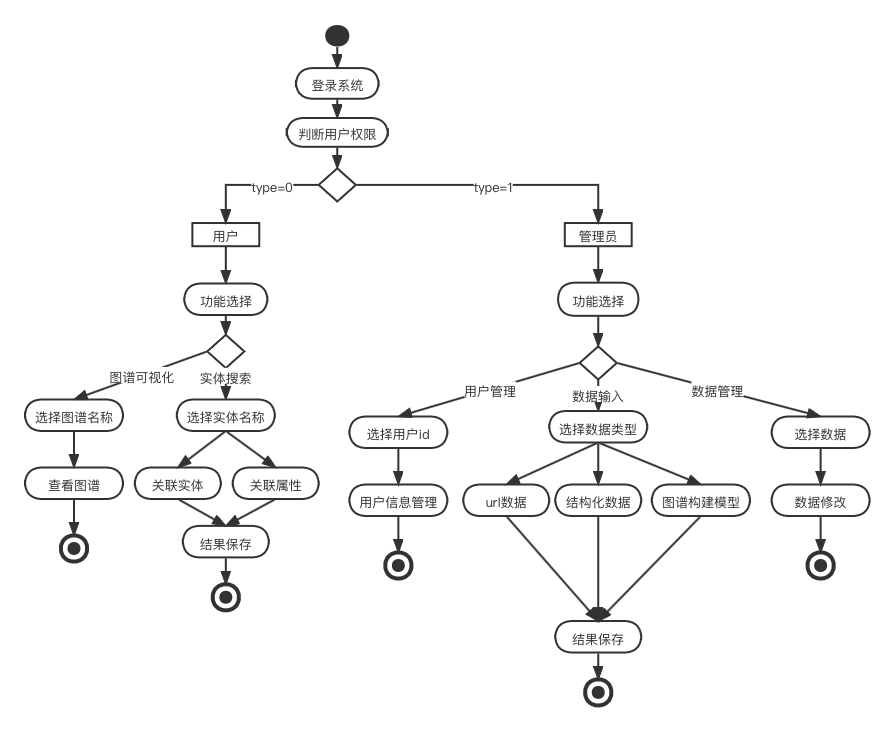
该系统的可视化平台活动图如图所示。
用户表
| 字段名 | 类型 | 描述 |
|---|---|---|
| id | int | 用户唯一id,主键 |
| type | int | 用户权限,区分普通用户和管理员 |
| name | varchar | 用户名 |
| pwd | varchar | 用户密码 |
政策知识图谱关系类型示例
| 类型名称 | 两端实体类型 | 三元组样例 |
|---|---|---|
| 发布 | (发布主体,总体规划)(发布主体,事务机制) | (国务院,健全,医疗保障体系) |
| 包含 | (总体规划,管理体系)(管理体系,事务机制)(事务机制,具体措施) | (科技创新体系,包括,关键核心技术攻关机制) |
| 涉及 | (具体措施,行业群体) | (关键核心技术突破,涉及,新材料产业) |
| 合作 | (行业群体,行业群体) | (银行,协助,医疗部门) |
作者:410

求源代码,有源代码吗?邮箱:1461886857@qq.com

