


571
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
随着视频网站的流量增多,短视频的火爆,视频的影响力在日益增大。但影响力增大的同时,视频的数量也在快速的上涨。使得观众在选择视频时较难快速的精准的找到感兴趣的内容。
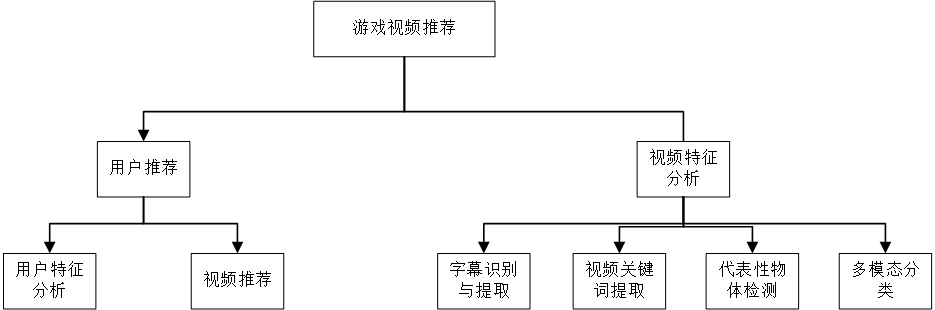
本文设计并实现了一个基于内容理解的游戏视频推荐系统。其主要功能是基于用户的喜好和视频网站上的视频内容来给用户推荐其可能感兴趣的视频。主要模块有光学字符识别模块、视频关键词提取模块、目标检测模块、多模态分类模块和推荐模块。系统的输入为游戏视频,光学字符识别模块的功能主要是识别并提取视频中的字幕。视频关键词提取模块的功能是从视频字幕,视频标签和视频简介三段文本中提取关键词。目标检测模块的功能是识别并截取视频中出现的有代表性的物体。多模态分类模块的功能是结合视频中的代表性物体、视频关键词和视频本身给出视频的所属类别。最后推荐模块根据以上信息及用户的喜好和观看记录来实现推荐。
游戏视频推荐系统从功能划分上可以分为视频特征分析和用户推荐两块,视频特征分析包括:
视频中的字幕识别与提取;
从视频字幕,视频标签和视频简介三段文本中提取视频关键词;
识别并截取视频中出现的有代表性的物体;
结合视频中的代表性物体、视频关键词和视频本身给出视频的所属类别。
用户推荐包括用户特征分析和视频推荐,视频推荐为通过用户特征分析、以及视频特征分析的结果对用户进行视频推荐。
首先OCR是模式识别的一个领域,所以整体过程也就是模式识别的过程。其过程整体来说可以分为以下几个步骤:
预处理:对包含文字的图像进行处理以便后续进行特征提取、学习。这个过程的主要目的是减少图像中的无用信息,以便方便后面的处理。在这个步骤通常有:灰度化、降噪、二值化、字符切分以及归一化这些子步骤。如果文字行有倾斜的话往往还要进行倾斜校正。
特征提取和降维:特征是用来识别文字的关键信息,每个不同的文字都能通过特征来和其他文字进行区分。对于数字和英文字母来说,这个特征提取是比较容易的,因为数字只有10个,英文字母只有52个,都是小字符集。对于汉字来说,特征提取比较困难,因为首先汉字是大字符集,国标中光是最常用的第一级汉字就有3755个;第二个汉字结构复杂,形近字多。
分类器设计、训练和实际识别:分类器是用来进行识别的,就是对于第二步,你对一个文字图像,提取出特征给,丢给分类器,分类器就对其进行分类,告诉你这个特征该识别成哪个文字。在进行实际识别前,往往还要对分类器进行训练,这是一个监督学习的案例。
后处理:后处理是用来对分类结果进行优化的,第一个,分类器的分类有时候不一定是完全正确的(实际上也做不到完全正确),比如对汉字的识别,由于汉字中形近字的存在,很容易将一个字识别成其形近字。后处理中可以去解决这个问题。第二个,OCR的识别图像往往是有大量文字的,而且这些文字存在排版、字体大小等复杂情况,后处理中可以尝试去对识别结果进行格式化。
关键词识别主要是识别文本中出现的实体,即命名实体识别,一般包括人民、地名、机构名和专有名词。在游戏视频领域内,实体可以是游戏名、游戏内英雄名、游戏内道具名或知名电竞选手和主播。可以帮助更好的确定视频类别。
命名实体识别通常使用BiLSTM和CRF来实现实体识别。对于数据较少的情况可以使用BERT等预训练语言模型来增强效果。对于中文来说,需要找到实体的开始和结束的字边界,部分较长较少见的实体边界较难分类准确。对于较长或有嵌套的实体,可以在LSTM的输入中引入词汇的信息来更准确的识别实体。对于领域内特有的实体,可以构建一个领域词典来提升准确度。
目标检测即找出图像中所有感兴趣的物体,包含物体定位和物体分类两个子任务,即同时确定物体的类别和位置。
物体定位:通过使用算法在待检测图像中产生一系列的候选区域(region proposals),之后对每个候选区域进行分类,来实现物体的定位。常使用RPN(Region Proposal Network)来实现候选区域的生成,该网络是一个全卷积网络,与分类网络共享整个图像的卷积特征,这使得其不但能非常快速地生成候选区域,且区域的质量都很高。此外,还会使用算法来对候选区域的位置进行微调,让其更接近真正的边界框,常用的方法如边界框回归(bounding-box regression)
物体分类:通常使用卷积神经网络来实现这一过程,常用的网络结构如VGG16,该网络使用多个33的卷积核代替55和7*7的卷积核,在感受野不变的情况下减少了参数的数量,进而提高训练收敛速度,且网络中使用了更多的卷积层和非线性激活函数,从而提升分类准确率。此外,通常还会在卷积层的最后,全连接层之前添加一个SPP层(Spatial Pyramid Pooling)来实现任意尺度的图像输入,例如Fast R-CNN中使用RoI层(特殊的SPP层)来实现该功能
多模态分类(Multimodal),可解释为以下两个部分:
Modality:A particular mode in which something exists or is experienced or expressed. 中文释义为模态或形态。一个事物存在(被体验/被表达)的一种特定的方式。如一只猫,能被看见,图像是模态;能被听见,声音是模态;能被触摸,它身上的皮毛纹理是一种模态;某些人可以通过气味辨别自己的猫,那么气味是模态。模态之间大都是异质性的(heterogeneity)。
Multimodal:多模态,顾名思义,包含了多种模态。如果一个研究问题或者数据集包含了多个上述的模态时,也可以被称为multimodal。
之所以要对模态进行融合,是因为不同模态的表现方式不一样,看待事物的角度也会不一样,所以存在一些交叉(所以存在信息冗余),互补(所以比单特征更优秀)的现象,甚至模态间可能还存在多种不同的信息交互,如果能合理的处理多模态信息,就能得到丰富特征信息。即概括来说多模态的显著特点是:冗余性和互补性。
但是,在计算机中,不同模态的信息的表示往往是不同的,也就是说,将不同模态的信息融合汇聚在同一个模型和任务中,其信息的共同表示也是存在难点的。不过,在深度学习中,我们可以把不同模态的信息都表示为张量,以便于计算机进行运算。
接下来面临的最大的困难就是不同模态信息的交互。好在近年来,随着attention机制的发展,我们可以在一个张量中同时关注多种上下文信息,我们可以利用attention机制的这一点,将不同模态的信息汇聚在attention机制中进行交互,这样可能就得到了该问题的答案。
推荐系统是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。
随着电子商务规模的不断扩大,商品个数和种类快速增长,顾客需要花费大量的时间才能找到自己想买的商品。这种浏览大量无关的信息和产品过程无疑会使淹没在信息过载问题中的消费者不断流失。为了解决这些问题,个性化推荐系统应运而生。个性化推荐系统是建立在海量数据挖掘基础上的一种高级商务智能平台,以帮助电子商务网站为其顾客购物提供完全个性化的决策支持和信息服务。
推荐系统是一种自动联系用户和物品的工具,它能够帮助用户在信息过载的环境中发现令他们感兴趣的信息。它通常由前台的展示页面、后台的日志系统、推荐算法系统三个部分组成。其大致流程如下图所示:
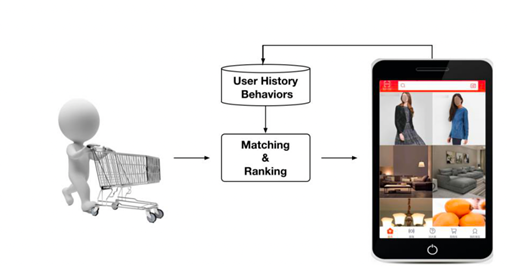
首先记录用户的各种浏览、评价记录,然后进行匹配。在匹配阶段,通过协同过滤等方法生成与访问用户相关的候选对象列表。之后在排序阶段预测每个候选对象的点击率,选择排名靠前的对象进行推荐。而主要的推荐算法有基于流行度的推荐、基于内容的推荐、协同过滤算法、基于关联规则的推荐、基于模型的推荐、混合推荐等等。一般在工业界实现的时候,会融合多种推荐算法进行混合推荐。
| 字段名 | 类型 | 描述 |
|---|---|---|
| u_id | int | 用户唯一id,主键 |
| type | boolean | 用户权限,用于区分普通用户和管理员 |
| name | varchar | 用户名 |
| password | varchar | 用户密码 |
| 字段名 | 类型 | 描述 |
|---|---|---|
| u_id | int | 用户唯一id,主键 |
| search_v | text | 用户搜索记录 |
| seen_v | text | 用户看过的视频 |
| 字段名 | 类型 | 描述 |
|---|---|---|
| u_id | int | 用户唯一id,主键 |
| vec_user | text | 用户的特征向量 |
| 字段名 | 类型 | 描述 |
|---|---|---|
| v_id | int | 视频唯一id,主键 |
| title | varchar | 视频标题 |
| introduction | text | 视频简介 |
| label | varchar | 视频标签 |
| url_v | varchar | 视频文件的存放地址 |
| url_s | varchar | 视频字幕的存放地址 |
| 字段名 | 类型 | 描述 |
|---|---|---|
| v_id | int | 视频唯一id,主键 |
| key_word | varchar | 提取的视频关键词 |
| repre_object | varchar | 视频中的代表性物体 |
| types_video | varchar | 多模态分类得到的视频类别 |
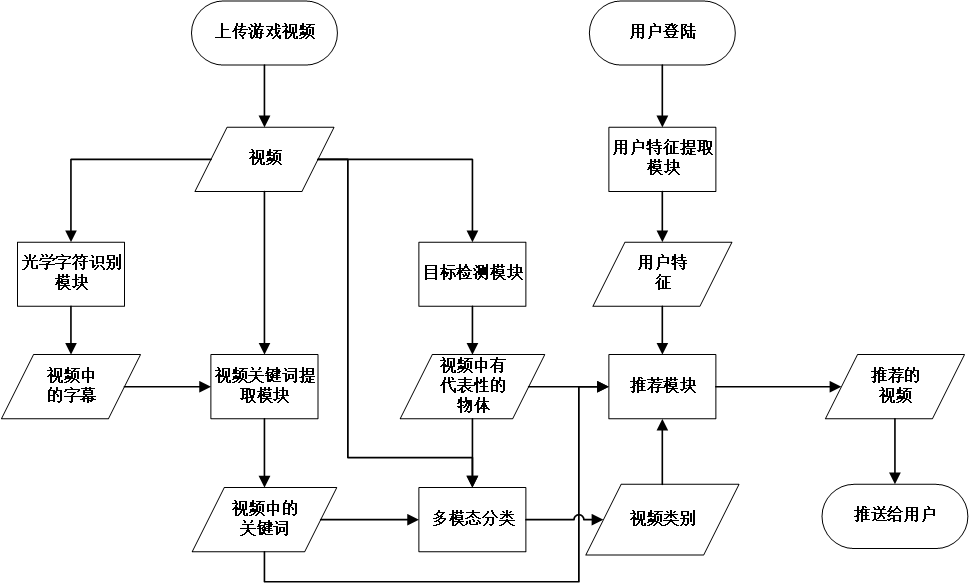
从上述的用例建模、数据建模可知,该系统的概念原型是:
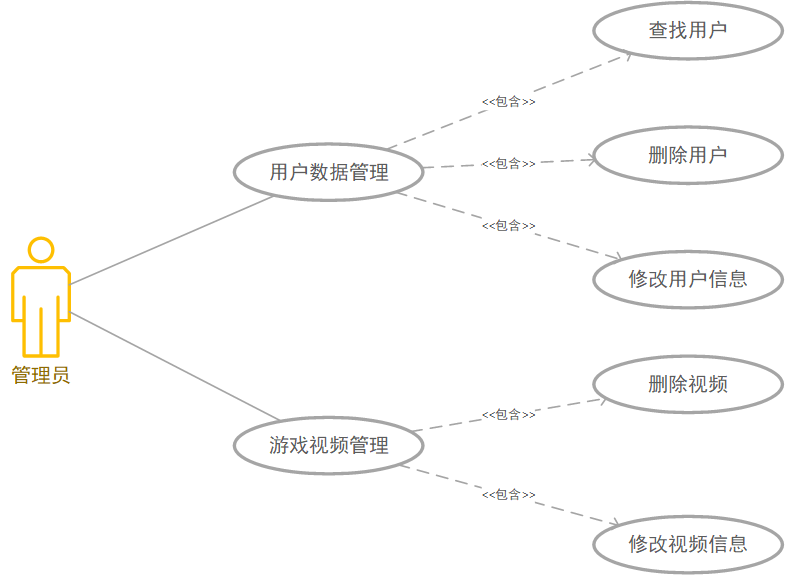
首先对上传到系统中的每一个视频进行视频特征的分析与提取,并将提取到的视频特征存储到数据库中,其次对每个注册用户,都会根据其看过的视频,和对视频的搜索记录生成一个用户特征,并存储到数据库中。每次用户登陆时,可以进行上传游戏视频、搜索视频、查看推荐视频三个操作,若选择查看推荐视频,则系统会根据数据库中用户的特征,以及视频的特征,生成推荐视频并推送给用户。此外,系统管理员可以对系统中的用户数据以及游戏视频进行管理。
在查看推荐视频时使用职责链模式,这样使系统在对查看这一请求进行处理时,能够让请求沿着 “用户发出请求->取得用户特征->取得视频特征->视频推荐” 这一链条传递,从而降低请求发送者与请求处理者之间的耦合
系统在与数据库进行交互时使用单例模式,将数据库连接池对象设计成单例类,并生成唯一的数据库实例,这样可用大大节省打开或者关闭数据库连接所引起的效率损耗
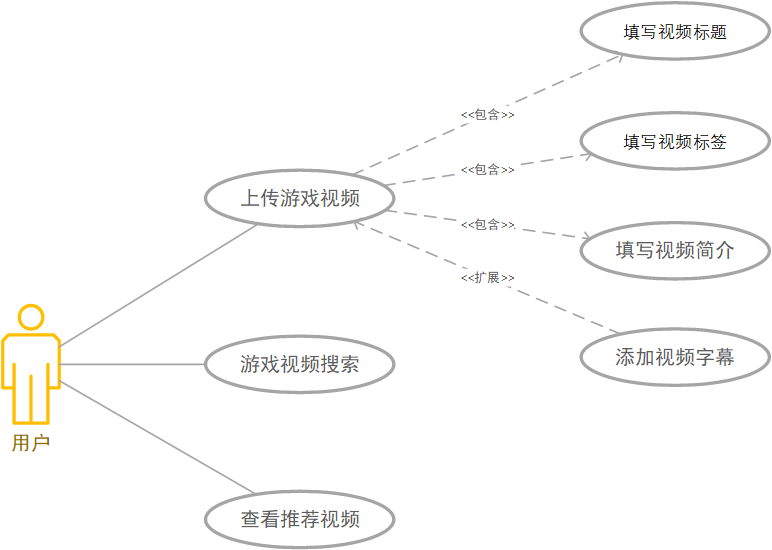
在上传游戏视频中用到组合模式,因为使用组合模式能把多个对象当作一个单一对象,让组合对象的使用与单个对象的使用具有一致性,而上传过程分为多步,需分别填写视频标题、视频标签、视频简介、视频字幕,每步即为一个对象
该模块中使用中介人模式和命令模式。
把结果显示视图与用于查找数据的模型分开,使用控制器将搜索的请求传递给查找模型,并用模型得到的数据对视图进行更新
将搜索请求封装为一个对象,使发出请求的责任和执行请求的责任分隔开,并方便了对搜索请求的储存和传递
每个特征提取模块均使用外观模式,使每个模块均有一个一致的接口,方面对其进行访问
根据项目需求分析,采用MVC软件架构,将系统中向用户提供信息的视图对象,与封装数据和基本行为的模型对象进行解耦合,提高软件的扩展性,进而使软件变得更加容易适应需求的改变。
具体来说,就是把视图与模型分离开,之后两者通过控制器进行关联。控制器捕捉鼠标移动、鼠标点击和键盘输入等事件,将其转化成服务请求,之后传给模型或者视图。用户实际上是通过控制器来与系统交互的,即通过控制器来向模型传递数据,改变模型的状态,并最后导致视图的更新,从而得到反馈。
MVC架构,即 Model-View-Controller(模型-视图-控制器)。
控制器:负责转发请求,对请求进行处理。
视图:图形界面设计。
模型:程序应有的功能(实现算法等)、数据管理和数据库设计。
作者:218
作者:218

