


571
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本系统的开发目的是对短时交通流量预测算法进行数据支持和落地实现,首先根据算法流程,需要对算法使用的数据进行预处理操作,减少噪声数据对于预测模型的影响,提高模型的准确率;其次神经网络模型相较于其他方法,参数量大,需要高吞吐量的模型进行参数传输;然后预测结果需要通过前端可视化的方式,直观地展现给用户;最后系统需要对历史流量、预测流量等相关参数进行存储和管理。最终对系统的需求分析,得到以下四个方面:
(1)交通流数据收集与预处理功能:交通流量数据是整个系统的数据基础与依托。首先,路侧传感器实时收集交通流量,并在系统后台将连续的交通流量离散化为每5分钟道路上的交通流流量,并且按路段进行聚合,以天为单位提供*.txt文件。其次,实时收集的交通流量存在噪声点、缺失数据等问题,且传感器数据存在一些与系统无关字段,因此需要对原始交通流量数据进行预处理,并将处理后的数据存入持久化数据库MySQL中,作为城市短时交通流量预测和可视化的数据基础。最后,城市短时交通流量预测和可视化需要不同结构的数据,需要对流量数据进行处理,作为预测算法和可视化的数据输入。
(2)城市短时交通流量预测功能:城市短时交通流量预测是本系统最重要的功能,也是课题研宄的核心算法,本系统通过历史交通流量预测城市背景下城市路网未来5-60分钟的交通流量。针对传统方法缺乏时空关联性和无法精准处理路网结构的问题,将历史数据在临近时间、日时间、周时间三个时间上进行特征提取,并且将城市路网抽象为一个图结构,动态提取交通流量的时间特征和空间特征。最后对于得到的预测结果进行了准确性评估,并将预测结果动态的展示到地理路网结构上。
(3)数据可视化功能:抽象的交通流数据难以直接为普通出行者所使用,数据可视化功能需要为城市短时交通流量预测与可视化分析系统的用户提供一个友好的可视化界面和直观的使用感受。首先,通过热力图、实况图等形式,可以直观得到每条道路的路况。其次,通过折线图、饼图等数据分析图,可以对历史交通流量进行流量分析,帮助城市道路规划者与管理者进行交通流量的特征分析,以便日后更好地进行决策。
(4)数据管理功能:系统的管理员需要在系统的运行过程中,对于系统各方面的数据进行管理。首先,历史交通流量数据存储在持久化数据库中,并且预留了增加新数据、数据删除、数据修改和数据查询接口,支持对流量数据的各项管理操作。其次,系统部署和运行过程中会产生日志文件,对于日志文件的管理在系统维护、升级以及修复时起到重要作用。最后,是系统各用户相关信息的管理,不同的用户具有不同权限,且用户数据涉及用户隐私,需要安全性管理。
系统不仅需要满足功能性需求,同时为了系统能够稳定运行、并且提供高效的服务,还需要满足一些非功能性需求,在本系统中需要满足的非功能性需求如下:
(1)性能需求:在性能需求方面主要考虑响应时间、吞吐量以及资源利用率。在可视化界面,由于GeoJSON文件数据量较大导致页面渲染时间长,需要保证页面响应时间,在无法提高响应时间时,也需要增加加载条等页面部件,降低用户等待焦虑感。同时,根据业务需求,需要设计系统吞吐量,在城市短时交通流量预测部分,需要短时间内传输模型的参数及预测结果对系统吞吐量要求较高。最后,系统部署在服务器上,服务器资源珍贵,系统需要对算法的开销需求进行评估,充分发挥资源利用百分比。
(2)安全性需求:在本系统中,存在大量的用户数据与交通流量数据,涉及到隐私数据,需要保证安全性。首先,数据在存储时进行需要进行加密,防止对用户输入内容进行攻击。其次系统需要根据不同用户的权限控制访问数据,进行系统日志记录。
(3)可维护性和可拓展性:系统需要能够应对业务变化需求以及技术更新,当出现新的需求时,需要能以较小的代价尽快适应变化。首先需要考虑将系统功能模块化,有利于减少重复的开发性工作,同时需要进行可复用性,如相似组件复用,最后需要考虑易分析性,如通过保存和统一管理系统日志,记录系统的历史使用情况,在系统出现问题时快速追踪并解决。
(4)易用性:在设计城市短时交通流量预测与可视化分析系统时,系统的受众是交通管理部门的管理者与普通的出行用户,用户可能缺少相关的专业知识,因此系统需要有易上手,具有可操作性和逻辑性,还需要保证用户界面美观。
基于上述系统需求分析,本论文将整个系统分为五个功能模块,如图所示:包括系统管理模块、数据预处理模块、城市短时交通流量预测模块、数据可视化模块和数据管理模块。
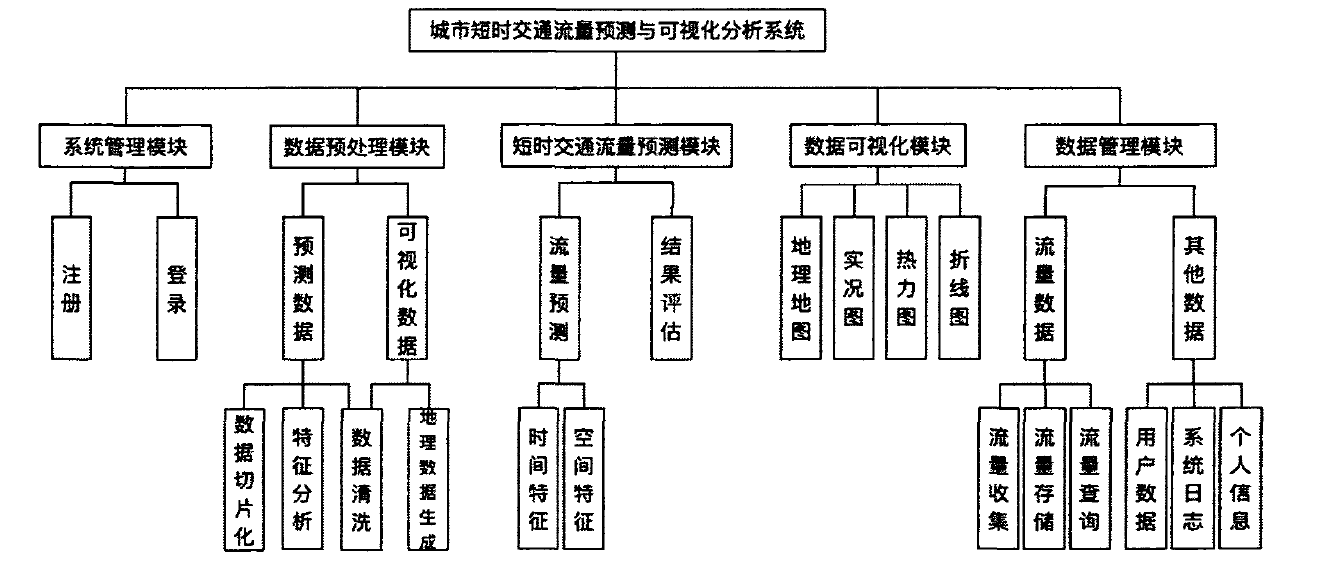
数据预处理模块作为整个系统的数据支持,城市短时交通流量预测模块、数据可视化分析模块以及流量数据管理功能,都依赖数据预处理模块对原始交通流进行数据清洗、数据集成、数据规约和数据变换。数据预处理模块的处理流程如图所示。
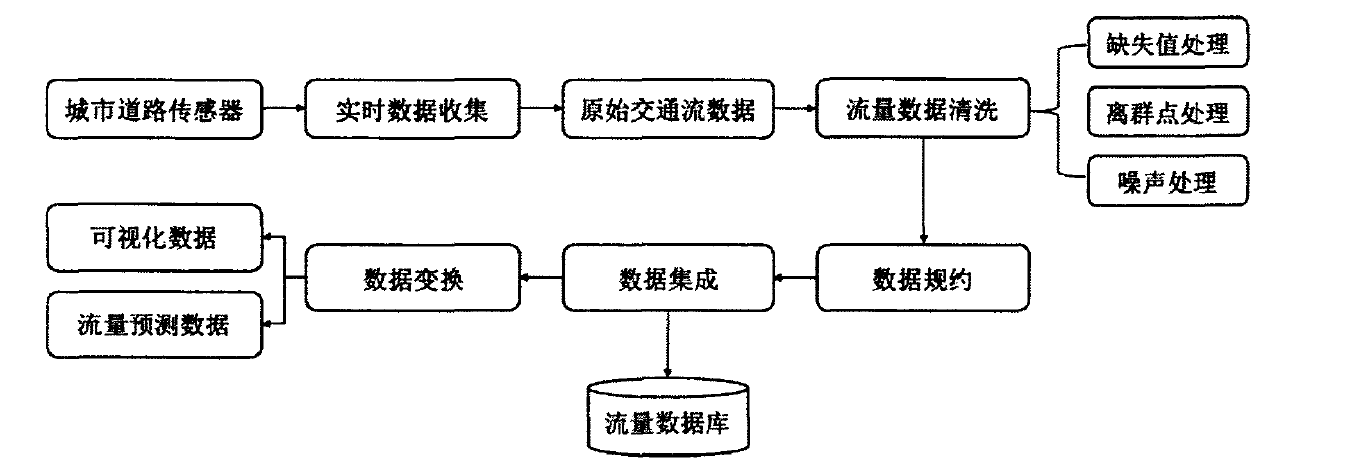
(1)数据清洗:在数据预处理模块接收到原始的交通流*.txt和*.xml数据后,首先对文件进行解析。由于本系统数据来源为PeMS开源数据集,此数据集中数据为线圈采集的原始交通流数据,由于观测站情况和广域网数据传输,不可避免的存在数据缺失、离群点和噪音问题,因此首先需要进行数据清洗。主要使用两种方法,一是直接删除整条异常数据,二是使用估算方法对异常数据进行合理填补。通常有四种估算办法:基于局部系数的邻居线性回归、基于全局系数的邻居线性回归、时间中位数和聚类中位数。在本课题中数据不存在大段缺失的情况,因此使用时间中位数进行填补处理,处理后的数据集不会出现数据间隙,数据更加完善。
(2)数据规约:原始数据集中存在重复属性和可忽略字段,如所在城市、第N车道的速度、流量、占有率等。因此,数据预处理模块使用数据规约技术进行数据维度规约,压缩属性集使模式更易于理解,只提取出系统所需要的相关交通流量字段,如时间片、整条路上的交通流量、车速、占有率等。
(3)数据集成:对于清洗和规约完的数据,本模块将其映射到持久化数据库MySQL中,并构建了一个字段完整的流量数据库,提供接口以方便后续流量管理。
(4)数据变换:根据不同模块的数据需求,数据预处理模块需要提供两种不同格式的数据,一种是为可视化模块提供GeoJSON地理信息数璀,另一种则是需要为城市短时流量预测模块提供以时间为单位的交通流量数据,和以传感器相对位置信息为基础的城市路网数据,并将其整合为*.csv数据和*.npz格式数
据。
城市短时交通流量预测模块是系统的核心模块,也是本课题的研究重点与创新点所在。本模块通过历史交通流量预测未来5-60分钟城市内交通流量,并对预测结果进行评估,最后将评估结果反馈给用户。
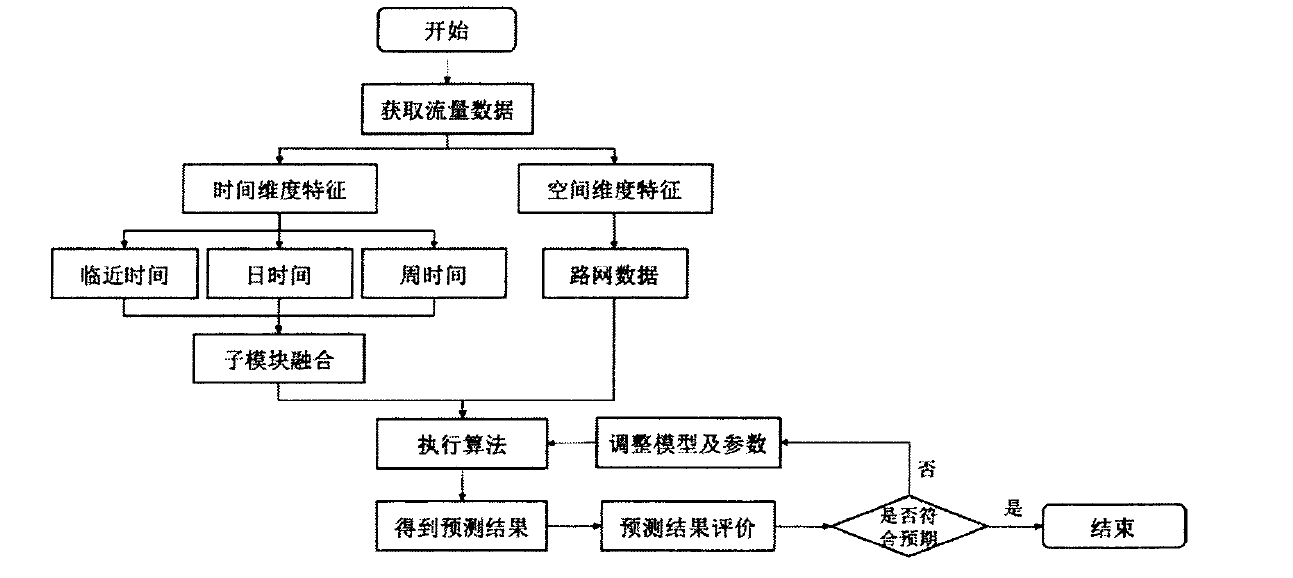
城市短时交通流量预测模块处理的难点,首先是如何充分利用大量历史数据,本系统预测的城市中存在超过350个环形线圈,每个环形线圈每5分钟汇总一次车流数据,每天产生五万余条数据,而PeMS数据集提供的全部历史车流数据超过12TB。本模块主要从时间维度和空间维度两方面提取数据特征,在时间维度上,本模块通过三个不同时间段:临近时间、日时间和周时间,对每个时间段分别建模,并通过历史交通流量特征分析将三者进行有权重的融合。在空间维度上,本模块将环形线圈的相对位置对应到路网中,将路网结构抽象为一个图结构。将时间维度和空间维度的特征提取共同组成一个时空残差卷积块,通过堆叠多个残差卷积块进行区域内的交通流量预测。
本系统设计了一个基于Java语言使用微服务架构的原型系统,通过Eureka实现服务的发现与注册,短时交通流量模块由于需要使用PyTorch库,因此使用Python语言实现。为了实现跨语言的服务调用,且保持微服务架构的优点,如负载均衡、服务消费者与服务使用者解耦合等,需要实现非Java应用使用Eureka的方法。有两种解决方法:(1)在Python服务中,手动实现各种REST操作,并且注册到其XSD中;(2)使用SpringCloud Netflix Sidecar,它与Python服务在同一服务器上运行,通过定义应用程序名称将其注册到Eureka服务注册表中,并通过REST操作检查Python服务的健康状况,并报告给Eureka。Sidecar只需要一句注解和少量配置即可在SpringCloud项目中使用非Java语言服务。因此本系统使用Sidecar方式进行异构服务调用。

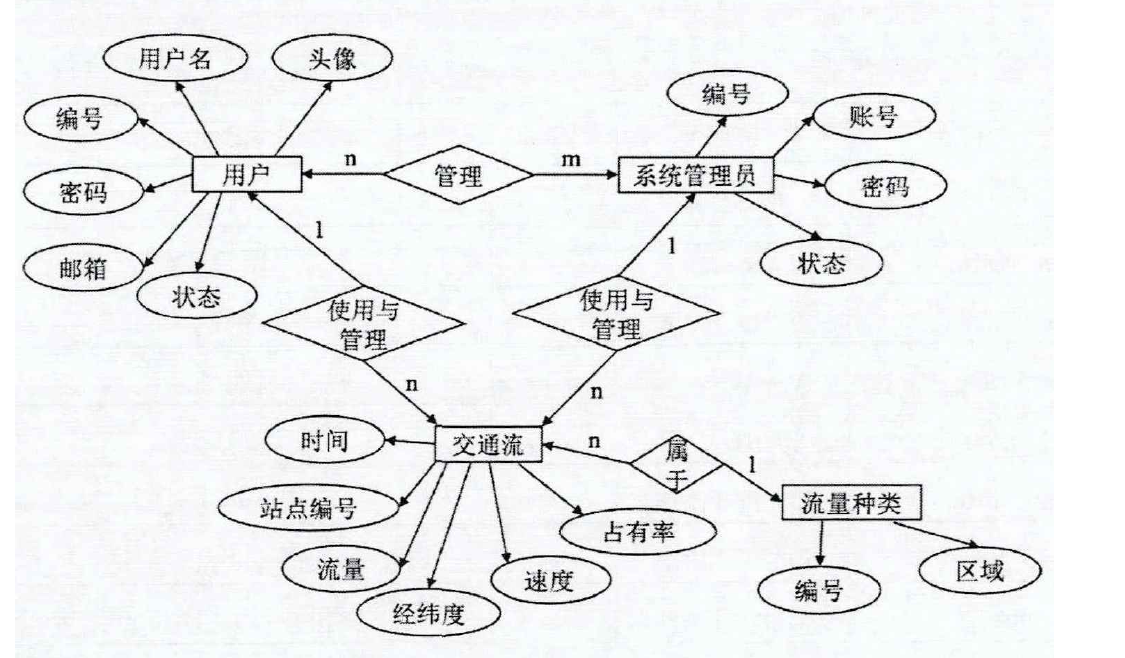
在城市短时交通流量预测与可视化分析系统中数据按照其结构主要分为两类:一类是系统业务相关的对象实体,包括用户信息、用户权限、历史交通流量;另一类是地理空间GeoJSON数据,即前端展示的热力图、地理折线图所需要的数据。因此将系统业务相关的数据使用MySQL数据库进行存储,将地理信息数据使用文件的方式进行存储。图4-11是本系统的E-R实体关系图,由实体关系图可以清晰得到本系统相关对象实体之间的关系。根据E-R实体关系图给出了相关实体具体表设计。
交通流量表:
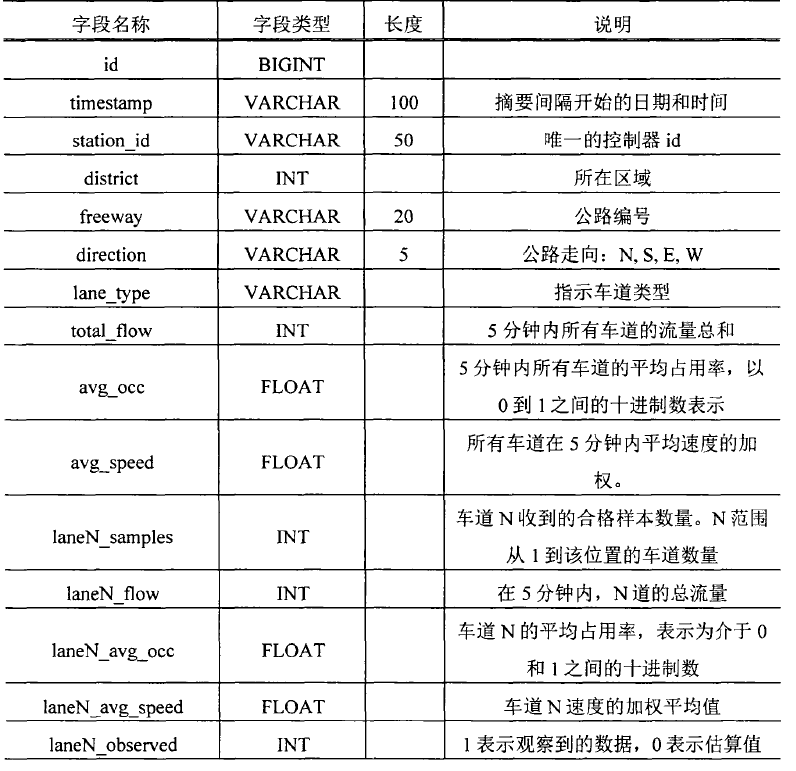
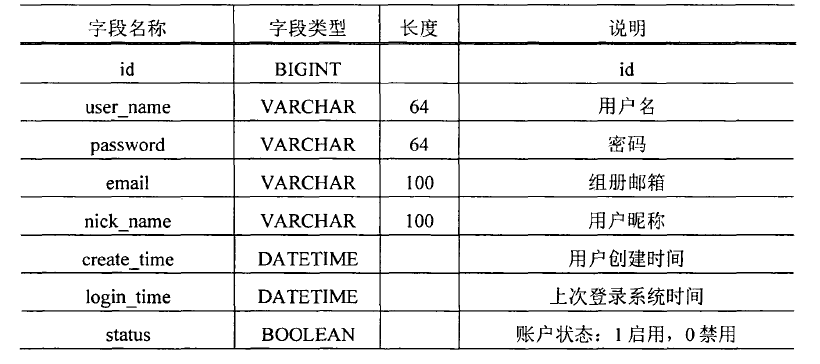
用户信息表:
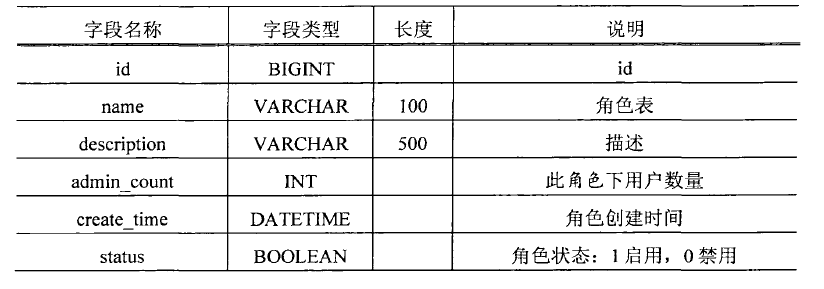
角色表:
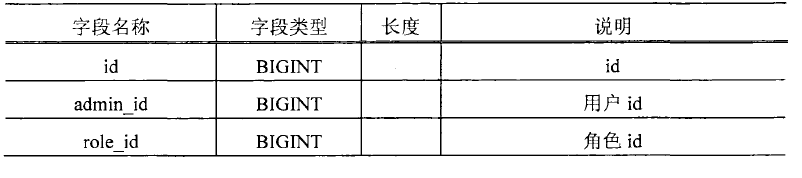
用户-角色关系表:
351 msp

