背景
云计算已经渗透到了互联网的每一个角落, 如今, 几乎每一个大型互联网应用都部署在云端, 以实现较低的运维成本和较高的可扩展性.
概述
本项目将实现搭建 OpenStack 云计算平台, 并基于 OpenStack 平台进行云计算平台中的数据转发, 路由更新, 虚机迁移, 健康检测等应用场景进行研究和优化, 以期提高云平台的可扩展性和鲁棒性.
OpenStack 是一个由 OpenStack 基金会管理的开放标准的云计算平台, 其通常作为基础设施即服务 (IaaS) 在公有云或私有云中被部署. OpenStack 涵盖了管理数据中心的各个方面, 包括计算, 存储, 网络等资源.
架构
OpenStack 的逻辑架构如下:
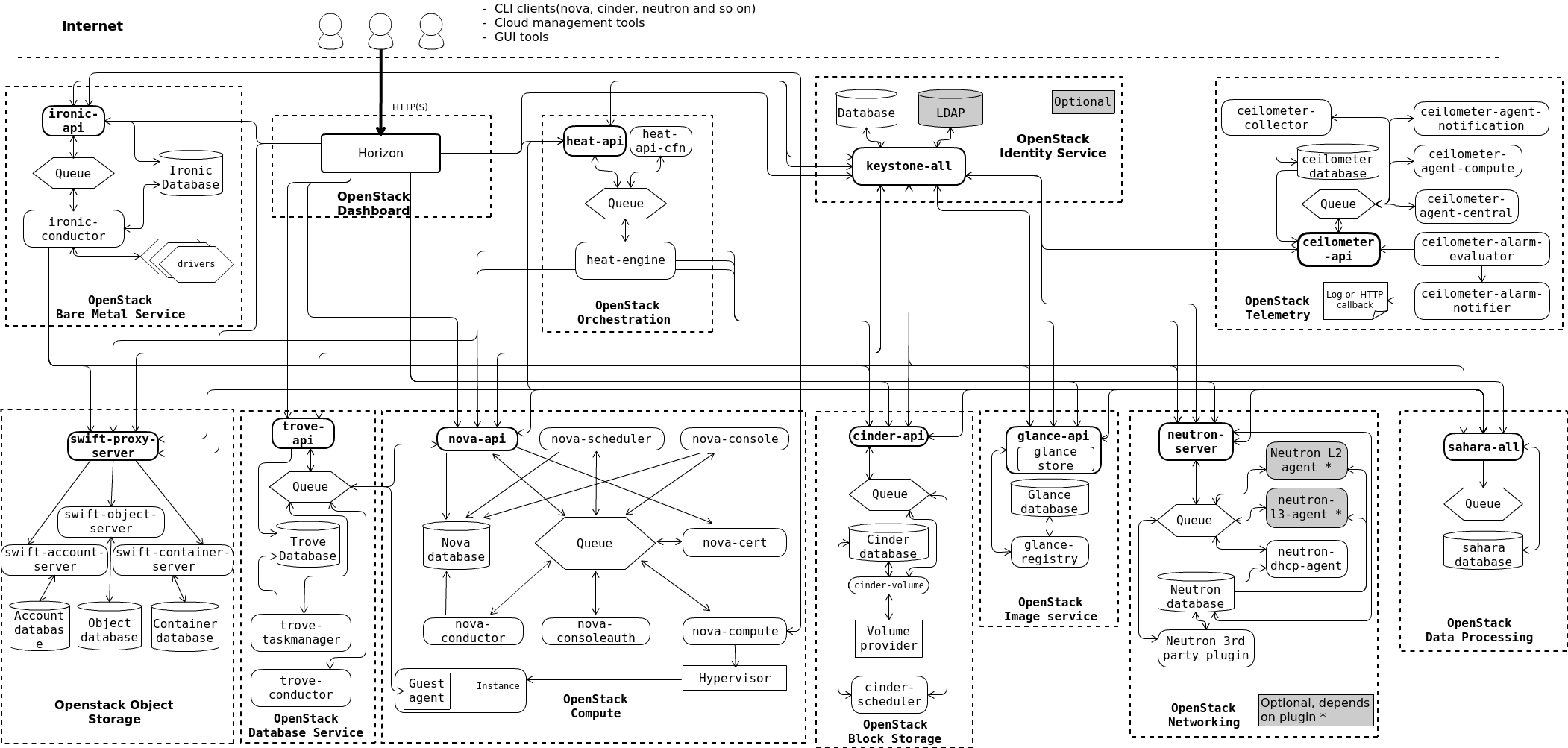
图源:
https://docs.openstack.org/install-guide/get-started-logical-architecture.html
OpenStack 遵循了高内聚, 低耦合的原则, 所有组件均可独立部署, 组件之间通过 RESTful API 通信.
由于需求的不断更新, 越来越多的组件被加入到了 OpenStack 中, 上图仅展示了 OpenStack 的核心组件, 其中包括:
- Horizon, 管理前端, 是与用户交互的主要通道.
- Keystone, 身份认证组件, 管理用户数据库, 管理所有组件的认证 (Authentication) 和鉴权 (Authorization).
- Nova, 计算服务, 管理虚拟机资源, 包括虚拟机的创建, 销魂, 迁移等
- Ironic, 管理裸金属服务器, 提供包括 PXE 等的管理协议的支持
- Swift, 对象存储, 管理大量无结构的数据
- Trove, 数据库即服务, 提供数据库引擎接口
- Cinder, 块存储, 提供挂载到虚拟机上的卷资源
- Galance, 镜像服务, 虚拟机镜像的存储和检索
- Heat, OpenStack 的编排服务, 管理所有 OpenStack 组件的部署
- Ceilometer, 遥测服务, 从各个组件收集运行状态数据
- Neutron, 管理网络资源, 提供网络虚拟化的支持
- Sahara, 数据处理的调度引擎, 对 Nova, Swift 等组件进行编排来进行大数据处理
我们在这里以 Nova 组件为例, 描述其简化的需求和设计.
需求
Nova 提供了统一的计算资源抽象, 这些计算资源可以是物理机, 虚拟机或容器.
画出用例图如下:
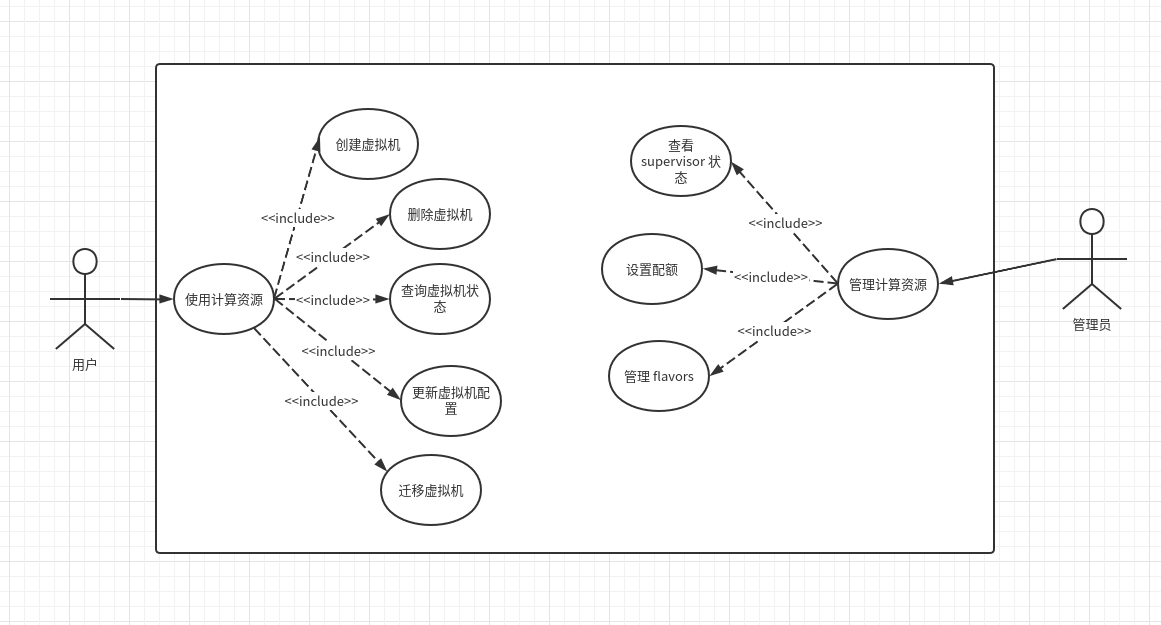
设计

图源:
https://docs.openstack.org/nova/latest/user/architecture.html
遵循 Openstack 的总体设计, Nova 对外提供 RESTful API, 而其内部则使用 RPC 进行通信, 使用一个中心化的数据库来存储数据.
Nova 内部共有五个组件, 其中除 db 之外均可进行横向扩展, 以提高其处理能力:
- API: 作为对外的接口提供了 RESTful API
- Conductor: 负责长时任务 (新建/迁移虚拟机等) 的协调, 同时也作为 Compute 等组件访问数据库的代理
- Scheduler: 负责决定在哪个 host 上创建虚拟机
- Compute: 管理 hypervisor, 负责和虚拟机通信
- DB: 数据库
以创建虚拟机为例, 操作的时序图如下:
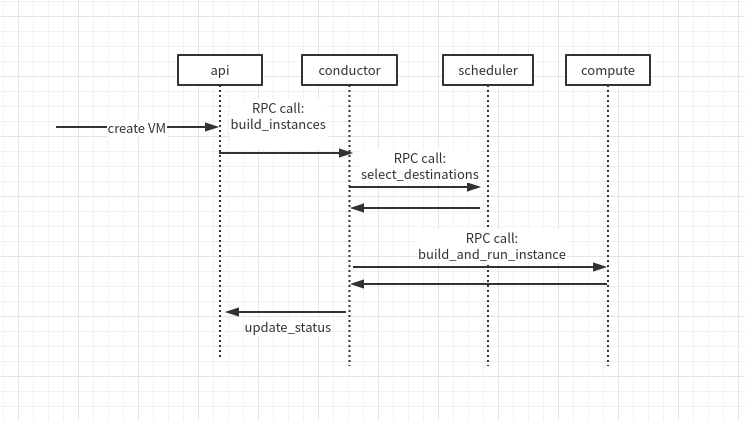
API 首先向 conductor 分配任务, conductor 生成虚拟机的元数据并向 schduler 分发调度任务, 收到响应后 conductor 再去请求 compute 执行创建操作, 并向 api 返回结果.
设计模式
Conductor 提供了数据库的代理机制, 应用了代理模式. 应用代理模式主要有以下几点考虑:
- 提升 Compute 服务对数据库访问的性能. 对数据库本身的访问是阻塞的, 而 RPC 通信是非阻塞的.
- 提升访问数据库的安全性
- 在数据库升级过程中对旧组件提供了向下的兼容性
API 提供了统一的对外接口应用了外观模式, 其对外提供了一个简单的接口, 提升了易用性.
各个组件间的通信应用了观察者模式, 组件间 RPC 使用了消息队列以实现非阻塞式的调用, 调用者通过订阅调用的结果来避免轮询结果导致的性能开销.
作者: 144



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
