



571
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
随着计算机技术、计算机硬件上的快速发展,现在的项目都会非常庞大,文件是非常多的,每次进行修改之后进行编译工作将会是一件非常耗时的事情。为了提升编译速度,主要有三种方式:
第一种是将本地文件差异分发到高配服务器编译,例如PatchBuild,由于编译操作不在本地,这对本地环境的要求非常低,甚至可以是完全异构的环境。
第二种是对编译结果缓存,主要有ccache,xcache,sccache,其中ccache是本地缓存,xcache、sccache是云端缓存。以ccache为代表简单描述一下思想,它是“compiler cache”的缩写,是一个编译器缓存,该工具会高速缓存编译生成的信息,并在编译的特定部分使用高速缓存的信息, 比如头文件,这样就节省了通常使用 cpp 解析这些信息所需要的时间。如果某头文件中包含对其他头文件的引用,ccache会用那个文件的 cpp-parsed版本来取代include声明,不是真正去读取、理解并解释其内容,ccache 只是将最终的文本拷贝到文件中,使得它可以立即被编译。ccache是以空间换取速度,ccache非常适合经常make clean(或删除out目录)后重新编译的情况。
第三种则是分布式编译。这类产品多采取本地预处理、云端编译的实现。以往的普通编译方式是串行工作的,机器将模块逐个进行编译成目标模块,但是分布式编译是结合分布式的思想,将串行的工作转化为并行的工作,从而提高编译速度。准确的来说,
分布式编译是指将源程序通过网络中的多台计算机的协同编译过程编译成目标程序的技术。分布式编译一般通过TCP或SSH等协议将编译任务分配至网络中不同的计算机上,使这些计算机协同完成编译工作。
对于分布式编译的工具是比较多的,例如distcc,是Linux常用的一种编译工具。distcc是一个通过网络中的多台计算机对C、C++、Objective C或Objective C++代码进行分布式编译的程序。distcc是一款编译速度快且容易安装的分布式编译工具,它能产生和本地编译一致的编译结果。distcc并不要求所有的机器共享一个文件系统或有同步的时钟,也不要求它们有相同的library或头文件。当安装了交叉编译器时,distcc甚至不需要这些机器有相同的处理器或操作系统。
但是本文,我们将要介绍的的是Yadcc工具:
Yadcc是一套腾讯广告自研的工业级C++分布式编译系统。2021 年 6 月,正式对外开源。取决于代码逻辑及本地机器配置,yadcc可以利用几百乃至1000+核同时编译(内部而言我们使用512并发编译),大大加快构建速度。
yadcc的基本原理和编译过程是将客户端伪装成编译器,通过将客户端伪装的编译器加入PATH头部,这样构建系统就会实际执行yadcc来编译,yadcc会按照命令行对源代码进行预处理,得到一个自包含的的预处理结果,以预处理结果、编译器签名、命令行参数等为哈希,查询缓存,如果命中,直接返回结果,如果不命中,就请求调度器获取一个编译节点,分发过去做编译,等待直到从编译集群中得到编译结果,并更新缓存。简单来说,是与ccache、sccache、distcc等类似,可通过创建名为g++等的符号链接至yadcc的客户端,并将之加入PATH,来截获编译器调用。之后yadcc的客户端会将任务分发出去至编译机编译,降低本地负载。
通过本地预处理、集群编译的方式(相对于代码生成、优化等的计算成本,预处理通常可以很快的完成。通过将速度较慢的代码生成等逻辑分发至编译集群,可以提高编译的并行度)和分布式编译缓存(对于基于大仓库的开发模式而言,由不同人重复编译相同代码的场景是较为常见的。通过使用集中的编译缓存,允许不同机器上的编译任务共享编译结果来加速)的方式来进行编译的加速。
在编译加速方面,腾讯的测试中,AMD EPYC (Rome)机型上GCC8.2使用-E -fdirectives-only参数进行预处理的代码产出速度大约为100MB/s。而同等数量(100MB)的预处理结果的代码生成、优化等大约需要2分钟。
加入了中心调度节点,所有请求均由调度节点统一分配,低负载时可允许客户端尽可能提交更多的任务,集群满载时可阻塞新请求避免过载。
中心的调度节点也避免了需要客户机感知编译集群的列表的需要,降低运维成本。
编译机向调度器定期心跳,这样不需要预先在调度器处配置编译机列表,降低运维成本。
使用本地守护进程和外界通信,这避免了每个客户端均反复进行TCP启动等操作,降低开销。另外,无论编译器进行何种操作(预处理、失败回落本地编译、链接),均会和本地守护进程协商,在本地任务过多时排队等待,避免导致本地过载死机。。
编译器wrapper会和本地守护进程通信,控制本地任务并发度避免本地过载。
分布式缓存避免不必要的重复编译。可以优化少数情况下本地因为各种原因的重复编译,同时本地守护进程处会维护缓存的布隆过滤器,避免无意义的缓存查询引发不必要的网络延迟。
通过编译器哈希区分版本,这允许集群中存在多个不同版本的编译器。(广告集群中同时存在GCC7/8/9/10)。
实现了类似于P2P的“互助互利”的思想。yadcc集群中,各个机器即可以在编译时提交任务,也会在空闲时贡献一部分CPU来编译网络上的任务。随着用户的增多,不但不会降低每个人分到的资源,反而会增大整个集群的处理能力。
从经验来讲,预处理后再编译的耗时总和要大于直接编译。
分布式编译过程中无论是多次运行编译器又或是(为了减少网络带宽)压缩等操作均有以毫秒(某些情况下可能以十毫秒)为单位的时间开销。
部分编译机性能过差(或突发的相对于yadcc的外界负载过高)导致分发上去的任务编译缓慢,成为关键路径拖慢整体编译。
分发至编译机引入的网络延迟。
对于非C++类编译任务,`adcc不提供支持。贸然使用可能会因为启动过多编译任务消耗大量内存。
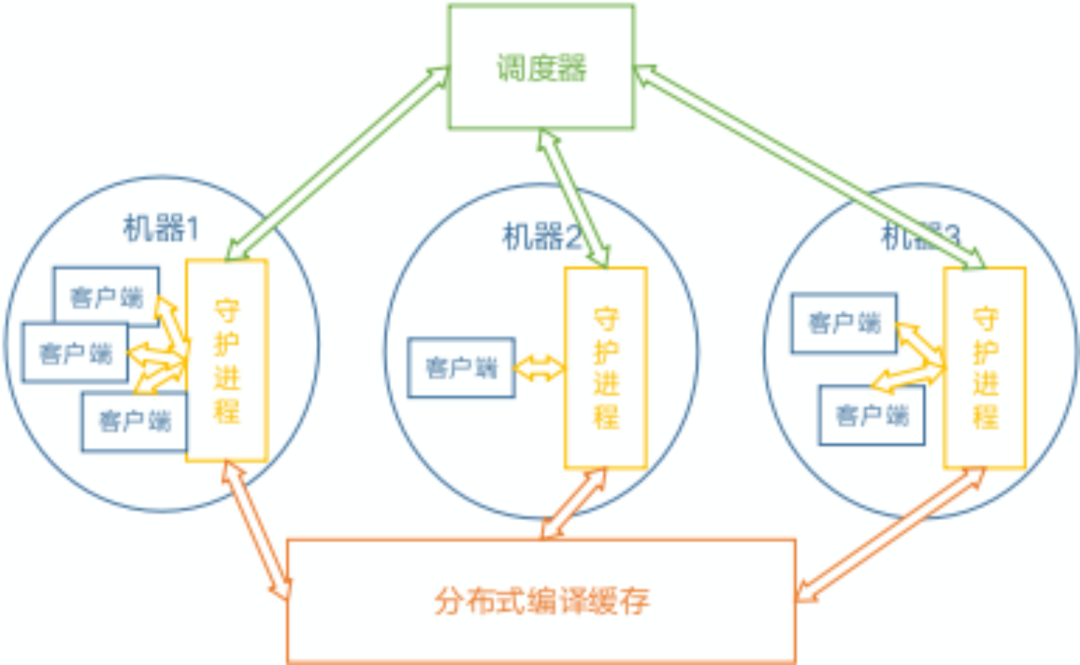
整体的设计包括以下部分:
1、调度器:具备全局视图,负责任务分发等;
2、编译缓存:全局共享,用于优化重复编译的场景;
3、守护进程:同时包含两种角色:
(1)客户端本地守护进程,接收本地编译器wrapper提交的任务、请求调度器获取空闲的编译机、将任务提交至具体编译机、等待任务完成并将结果返回给wrapper。
(2)编译机守护进程,接受网络上其他编译机提交的任务、执行、和提交方通信(返回结果等)。
取决于实际部署,一台机器可能同时身兼两种职责,也可能只作为客户机或只作为编译机。
4、客户端wrapper:伪装成编译器,截获编译任务并通过yadcc分发出去进行分布式编译,负责调用编译器进行预处理并压缩,并将预处理的结果及其他一些信息(如源代码的BLAKE3哈希)传递给守护进程进行编译。
如下图所示:
Yadcc自带了必要的第三方库,因此通常不需要额外安装依赖。
需要注意的是,yadcc通过git-submodule引用flare。
Flare 是后台服务开发框架,是腾讯吸收先前服务框架和业界开源项目及最新研究成果开发的现代化的后台服务开发框架,旨在提供针对目前主流软硬件环境下的易用、高性能、平稳的服务开发能力。Flare 是开箱即用的,已经自带了所需的第三方库,因此通常不需要额外安装依赖库。只需要在 Linux 下,拉取代码,即可使用。具体的构建、调试、测试可以参考具体的技术文档。
因此编译之前需要执行git submodule update拉取flare。另外由于flare代码仓库需要git-lfs支持,因此还需要安装git-lfs。以上工作完成之后执行如下的命令即可:
git clone https://github.com/Tencent/yadcc
cd yadcc
git submodule init
git submodule update .
使用如下命令编译yadcc:
./blade build yadcc/...
./yadcc-scheduler --acceptable_tokens=some_fancy_token
--acceptable_tokens:逗号分隔的一系列token。调度器会校验请求中的token,如果不匹配于这一参数中的任何一个,则会拒绝请求。
./yadcc-cache --acceptable_tokens=some_fancy_token
该部分是为了加速编译(用户之间互相共享编译结果),非必须部分。
./yadcc-daemon --scheduler_uri=flare://ip-port-of-scheduler --cache_server_uri=flare://ip-port-of-cache-server --token=some_fancy_token
--scheduler_uri:调度器的地址,通常形如flare://ip-port-of-scheduler或其他Flare能够解析的地址格式。
目前调度器并不支持高可用,因此即便使用某些名字解析服务地址,解析结果也只能为一台机器。(但是使用这种地址有助于减轻机房裁撤导致的IP变化的运维困难)。
--cache_server_uri:缓存服务器地址,格式同--scheduler-uri。通常解析结果只能为一台服务器。
--token:用于请求调度器、缓存服务器的token。具体能被调度器、缓存服务器接受的token列表取决于这两个服务器的配置(--acceptable_tokens)。
其他具体的参数可以参考相关文档。
yadcc可以通过软链接的方式链接到g++/gcc实现整合,也可以直接在环境变量上进行整合。
创建目录~/.yadcc/bin、~/.yadcc/symlinks。
复制build64_release/yadcc/client/yadcc至~/.yadcc/bin。
创建软链接~/.yadcc/symlinks/{c++,g++,gcc}至~/.yadcc/bin/yadcc。
将~/.yadcc/symlinks加入PATH的头部。
执行完毕上述操作之后which gcc应当输出类似于~/.yadcc/bin/yadcc的结果。
如blade/cmake的部分构建系统在检测到用户覆盖到CXX/CC/LD变量的时候,会使用指定的命令来编译:
CXX='/path/to/yadcc g++' CC='/path/to/yadcc gcc' LD='/path/to/yadcc g++' ./blade build //path/to:target -j500
8C虚拟机,256并发度,使用llvm-project-11.0.0.tar.xz测试。
可能取决于机器环境,不同机器上cmake3生成的目标数不一定一样。此处我们的环境中共计6124个编译目标。
命令行:time ninja
[6124/6124] Linking CXX executable bin/opt
real 47m51.414s
user 356m17.391s
sys 23m25.461s
分布式256并发、本地4并发
YADCC_CACHE_CONTROL=2表示不读取缓存,但是执行缓存相关逻辑并写入缓存。主要用于调试目的。
命令行:time YADCC_CACHE_CONTROL=2 ninja -j256
[6124/6124] Linking CXX executable bin/clang-check
real 3m11.292s
user 16m48.304s
sys 4m24.946s
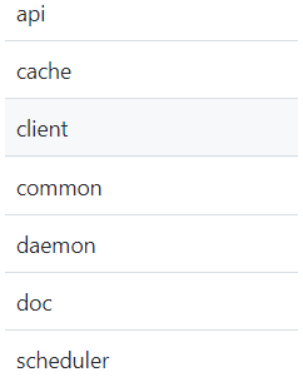
cache文件夹保存共享缓存代码,client文件夹保存客户端代码,common文件夹保存通用代码,daemon文件夹保存本地守护进程代码,schedule文件夹保存中心调度器代码。
因为cache主要维护了一个L1缓存和一个L2缓存。L1缓存是基于内存,直觉上是缓存热点数据,并采用一定淘汰策略保持大小可控。L2缓存为了便于系统今后方便扩展,适应更多存储方案,抽象了底层存储引擎实现。当我们需要其他存储方案时,可以快速实现一套底层存储方案,并通过修改配置选择对应的存储方案,并不需要修改核心逻辑。
以下代码是摘自 cache_service_impl.c:这也方法也被封装在了同名的头文件中,这个源码主要说明了跟cache服务相关的函数的实现逻辑,例如start()用来初始化服务,必须在启动服务器之前调用它。
CacheServiceImpl::CacheServiceImpl()
: internal_exposer_("yadcc/cache", [this] { return DumpInternals(); }) {
// Timers are started in `Start()`.
auto max_size = TryParseSize(FLAGS_max_in_memory_cache_size);
FLARE_CHECK(max_size, "Flag max_in_memory_cache_size is invalid.");
in_memory_cache_ = std::make_unique<InMemoryCache>(*max_size);
cache_ = cache_engine_registry.New(FLAGS_cache_engine);
}
void CacheServiceImpl::FetchBloomFilter(
const FetchBloomFilterRequest& request, FetchBloomFilterResponse* response,
flare::RpcServerController* controller) {
flare::AddLoggingItemToRpc(controller->GetRemotePeer().ToString());
if (!token_verifier_->Verify(request.token())) {
controller->SetFailed(STATUS_ACCESS_DENIED);
return;
}
if (request.seconds_since_last_fetch() >
request.seconds_since_last_full_fetch()) {
controller->SetFailed(STATUS_INVALID_ARGUMENT);
return;
}
//我们需要保持较低的完全更新频率,这会消耗带宽。
//如果在过去10分钟内有太多新填充的密钥,那么返回一个full Bloom Filter可能会更节省带宽。如果有太多的新密钥,我们可能需要设置一个阈值并返回full Bloom Filter。
response->set_incremental(
request.seconds_since_last_full_fetch() <
GetBloomFilterFullFetchIntervalFor(controller->GetRemotePeer()) / 1s);
if (response->incremental()) {
constexpr auto kNetworkDelayCompensation = 5s;
// It's fresh enough, let it update its Bloom Filter incrementally.
for (auto&& e :
bf_gen_.GetNewlyPopulatedKeys(request.seconds_since_last_fetch() * 1s +
kNetworkDelayCompensation)) {
response->add_newly_populated_keys(e);
}
} else {
// Return the full Bloom Filter then.
auto filter = bf_gen_.GetBloomFilter();
auto compressed_bytes =
flare::Compress(flare::MakeCompressor("zstd").get(), filter.GetBytes());
FLARE_CHECK(compressed_bytes);
response->set_num_hashes(filter.GetIterationCount());
controller->SetResponseAttachment(*compressed_bytes);
}
}
void CacheServiceImpl::TryGetEntry(const TryGetEntryRequest& request,
TryGetEntryResponse* response,
flare::RpcServerController* controller) {
flare::AddLoggingItemToRpc(controller->GetRemotePeer().ToString());
if (!token_verifier_->Verify(request.token())) {
controller->SetFailed(STATUS_ACCESS_DENIED);
return;
}
auto bytes = in_memory_cache_->TryGet(request.key());
if (bytes) {
controller->SetResponseAttachment(*bytes);
return;
}
bytes = cache_->TryGet(request.key());
if (!bytes) {
controller->SetFailed(STATUS_NOT_FOUND, "Cache miss.");
return;
}
in_memory_cache_->Put(request.key(), *bytes);
controller->SetResponseAttachment(*bytes);
}
void CacheServiceImpl::PutEntry(const PutEntryRequest& request,
PutEntryResponse* response,
flare::RpcServerController* controller) {
flare::AddLoggingItemToRpc(controller->GetRemotePeer().ToString());
if (!token_verifier_->Verify(request.token())) {
controller->SetFailed(STATUS_ACCESS_DENIED);
return;
}
auto&& key = request.key();
auto&& body = controller->GetRequestAttachment();
// For better auditability.
FLARE_LOG_INFO("Filled cache entry [{}] with {} bytes.", key,
body.ByteSize());
cache_->Put(key, body);
in_memory_cache_->Put(key, body);
bf_gen_.Add(key);
}
void CacheServiceImpl::Start() {
// They're heavy operation, so don't to it too frequently.
cache_purge_timer_ =
flare::fiber::SetTimer(1min, [this] { cache_->Purge(); });
bf_rebuild_timer_ = flare::fiber::SetTimer(60s, [this] { OnRebuildTimer(); });
// Make sure the Bloom Filter is ready before we start serving the clients.
bf_gen_.Rebuild(GetKeys(), 0s /* Not applicable. */);
}
void CacheServiceImpl::Stop() {
flare::fiber::KillTimer(cache_purge_timer_);
flare::fiber::KillTimer(bf_rebuild_timer_);
}
void CacheServiceImpl::Join() {
// NOTHING.
}
// Bloom filter can deal with the duplicate keys case. We can get the advantage
// of fast insertions.
std::vector<std::string> CacheServiceImpl::GetKeys() const {
std::vector<std::string> keys;
for (auto&& k : in_memory_cache_->GetKeys()) {
keys.emplace_back(std::move(k));
}
for (auto&& k : cache_->GetKeys()) {
keys.emplace_back(std::move(k));
}
return keys;
}
void CacheServiceImpl::OnRebuildTimer() {
auto keys = GetKeys();
bf_gen_.Rebuild(keys, 10s /* Arbitrarily chosen. */);
}
这部分我在上文中也介绍了,该包下的类主要负责调用编译器进行预处理并压缩,并将预处理的结果及其他一些信息传递给守护进程进行编译,有一些类也做到了不错的优化。
针对广告线的开发环境(各个机器的GCC通常手动安装至可能不同的路径),还存在编译器路径不同导致预处理结果不同的问题。这会影响缓存命中率。针对这一问题,作了一些优化,统一化了预处理结果中的路径。这样预处理后的哈希(不考虑系统头文件不同的场景)即可保证不同机器上一致、对编译器安装路径不敏感并命中缓存。
这一部分的代码如下,摘自fakeroot.c:
PfnFprintf GetOriginalPrintf() {
static PfnFprintf orig_fprintf;
if (!orig_fprintf) {
orig_fprintf = (PfnFprintf)dlsym(RTLD_NEXT, "fprintf");
}
return orig_fprintf;
}
SelfPathDesc GetSelfPath() {
static SelfPathDesc desc;
if (!desc.path) {
// Provided by yadcc client if it wants us to rewrite compiler path.
desc.path = getenv("YADCC_INTERNAL_COMPILER_PATH");
desc.size = desc.path ? strlen(desc.path) : 0;
}
return desc;
}
// We're expected to be loaded via `LD_PRELOAD`. Therefore, because of "symbol
// interposing", all calls to `fprintf` should be direct to us.
int fprintf(FILE* stream, const char* format, ...) {
int result;
va_list args;
va_start(args, format);
// We only take care of "linemarkers".
//
// @sa: https://gcc.gnu.org/onlinedocs/cpp/Preprocessor-Output.html
// Not a linemarker.
if (strcmp(format, "# %u \"%s\"%s")) {
result = vfprintf(stream, format, args);
goto out;
}
// Copy the args as we're going to inspect it.
va_list args_copy;
va_copy(args_copy, args);
int line = va_arg(args_copy, int);
const char* path = va_arg(args_copy, const char*);
const char* extra = va_arg(args_copy, const char*);
// Replace any references back to compiler's path with our fake root.
//
// /opt/gcc/lib/gcc/x86_64-pc-linux-gnu/8/include
// /opt/gcc/lib/gcc/x86_64-pc-linux-gnu/8/include-fixed
// /opt/gcc/include
// ...
SelfPathDesc self_path = GetSelfPath();
int path_length = strlen(path);
if (path_length >= PATH_MAX /* How can it be? */ ||
self_path.size == 0 /* We shouldn't patch the path then. */ ||
path_length < self_path.size ||
memcmp(path, self_path.path, self_path.size)) {
// The path does not reference us, let it go then.
result = vfprintf(stream, format, args);
goto out2;
}
// Now replace the path prefix.
const char* end_of_prefix = path + self_path.size;
size_t rest_size = path_length - (end_of_prefix - path);
char temp_buffer[PATH_MAX + 64 /* Space for our fake root. */];
memcpy(temp_buffer, kFakeRoot, sizeof(kFakeRoot)); // Our fake root.
memcpy(temp_buffer + sizeof(kFakeRoot) - 1 /* Terminating null. */,
end_of_prefix,
rest_size); // Rest of the path.
temp_buffer[sizeof(kFakeRoot) - 1 + rest_size] = 0;
result = GetOriginalPrintf()(stream, format, line, temp_buffer, extra);
goto out2;
out2:
va_end(args_copy);
out:
va_end(args);
return result;
}
上文中说明了守护进程主要肩负两种责任:处理本地请求、处理网络请求。
对于本地请求,主要控制并发度、处理编译任务。对于网络请求主要是向调度器上报本地支持的编译环境(编译器版本等)、接受网络上的编译任务并运行。
以下代码说明了守护进程的启动过程,比较清晰,主要是一些初始化参数,摘自entry.cc:
int DaemonStart(int argc, char** argv) {
// 重置可能影响GCC行为的环境变量。
//
// TODO(luobogao): We can instead pass environment variables from client to
// GCC. This can reduce cache hit ratio though.
//
// @sa: https://gcc.gnu.org/onlinedocs/gcc/Environment-Variables.html
setenv("LC_ALL", "en_US.utf8", true); // Hardcoded to UTF-8.
unsetenv("GCC_COMPARE_DEBUG");
unsetenv("SOURCE_DATE_EPOCH");
// 如果我们以特权运行,请删除特权。
DropPrivileges();
// 通常我们不想在用户的机器上生成核心转储。
if (!FLAGS_allow_core_dump) {
DisableCoreDump();
}
// 删除与`{temp\u dir}/yadcc\*`匹配的所有内容。如果这些文件就在那里,因为我们上次没有完全退出。
RemoveTemporaryFilesCreateDuringOurPastLife();
// 尽早初始化单例
cloud::InitializeSystemInfo();
(void)cloud::CompilerRegistry::Instance();
(void)cloud::DistributedCacheWriter::Instance();
(void)local::DistributedCacheReader::Instance();
(void)local::DistributedTaskDispatcher::Instance();
(void)local::LocalTaskMonitor::Instance();
// TODO(luobogao): Set up a timer which periodically if we're still on disk.
// If not we'd better leave (to prevent some weird output from compilation.).
//
// This is partly mitigated in `ExecuteCommand` by resetting CWD to `/` before
// running compiler.
FLARE_LOG_INFO("Using scheduler at [{}].", FLAGS_scheduler_uri);
FLARE_LOG_INFO("Using cache server at [{}].", FLAGS_cache_server_uri);
flare::ServerGroup server_group;
// 初始化守护进程,为来自本地客户端的请求提供服务。
auto local_daemon = std::make_unique<flare::Server>();
local_daemon->AddProtocol("http");
local_daemon->AddHttpHandler(std::regex(R"(\/local\/.*)"),
std::make_unique<local::HttpServiceImpl>());
local_daemon->ListenOn( // Or perhaps we can use a UNIX socket?
flare::EndpointFromIpv4("127.0.0.1", FLAGS_local_port));
// This daemon listens on localhost only, therefore it's safe not to apply a
// basic-auth filter on `/inspect/`.
// 初始化为来自网络的请求提供服务的守护进程。
auto serving_daemon = std::make_unique<flare::Server>();
cloud::DaemonServiceImpl daemon_svc(
flare::Format("{}:{}", GetPrivateNetworkAddress(), FLAGS_serving_port));
// FIXME: What about IPv6?
serving_daemon->AddProtocol("flare");
serving_daemon->AddService(&daemon_svc);
serving_daemon->AddHttpFilter(MakeInspectAuthFilter());
serving_daemon->ListenOn(
flare::EndpointFromIpv4("0.0.0.0", FLAGS_serving_port));
// 开启服务
server_group.AddServer(std::move(local_daemon));
server_group.AddServer(std::move(serving_daemon));
server_group.Start();
// 等待直到被要求退出
flare::WaitForQuitSignal();
// 停止访问新请求。
server_group.Stop();
// 刷新正在运行的任务。
cloud::ExecutionEngine::Instance()->Stop();
cloud::DistributedCacheWriter::Instance()->Stop();
local::DistributedTaskDispatcher::Instance()->Stop();
local::DistributedCacheReader::Instance()->Stop();
daemon_svc.Stop();
cloud::ExecutionEngine::Instance()->Join();
cloud::DistributedCacheWriter::Instance()->Join();
local::DistributedTaskDispatcher::Instance()->Join();
local::DistributedCacheReader::Instance()->Join();
cloud::ShutdownSystemInfo();
daemon_svc.Join();
server_group.Join();
quick_exit(0); // BUG: For the moment we don't exit cleanly.
return 0;
}
} // namespace yadcc::daemon
调度器具备全局视图,负责将各个编译任务关联到一台编译机。
不同于distcc,全局视图可以避免由任务提交机器进行本地决策而导致负载不均衡,如压垮某台编译机的同时还有另外的机器空闲等。
调度器会定期扫描我们的缓存并构造相应的缓存布隆过滤器.
除此之外,为了保证布隆过滤器的时效性,在守护进程和调度器的心跳中,我们会:
对于接收编译任务的守护进程:上报新填充的缓存的Key来更新调度器维护的布隆过滤器。
对于提交编译任务的守护进程:返回其上次心跳至今,整个编译集群新填充的缓存的Key。
部分情况下一台守护进程即提交任务又接受任务,此时上述两种行为这个守护进程和调度器之间均会发生。
调度器启动,摘自entry.cc:
int SchedulerStart(int argc, char** argv) {
// 初始化单例。
TaskDispatcher::Instance();
flare::Server server;
// 开启服务
server.AddProtocol("flare");
server.AddHttpFilter(MakeInspectAuthFilter());
server.AddService(std::make_unique<SchedulerServiceImpl>());
// TODO(luobogao): What about IPv6?
server.ListenOn(
// We can't listen on loopback only, as obvious.
flare::EndpointFromIpv4("0.0.0.0", FLAGS_port));
server.Start();
// 等待直到被要求退出
flare::WaitForQuitSignal();
server.Stop();
server.Join();
return 0;
}
} // namespace yadcc::scheduler
int main(int argc, char** argv) {
return flare::Start(argc, argv, yadcc::scheduler::SchedulerStart);
}
调度算法是其以如下几点为目标来分配编译机:
优先考虑专有编译机。专有编译机负载不超过50%时任务始终分配至专有编译机。
负载超过50%之后需要考虑SMT导致的单核性能下降,因此此时如果有更空闲的机器会优先考虑。
除非没有其他机器,尽量避免将负载分配至提交任务的机器:这允许提交任务的机器有更多的CPU资源进行预处理。
为避免某些机器自身已有负载过高而导致新分配的编译任务执行过慢,调度算法会考虑参与编译任务的机器负载。如果机器空闲CPU少于机器本身所能接受的最大任务数,则以较小值作为“实际能接受的最大任务数”。
目前,Daemon定期在心跳包内上报自己15s内的平均负载,选择15s也是为了让daemon机器负载变化对调度算法更加敏感。
在剩余可选机器中尽量保证各个机器的编译负载(任务数/实际能接受的最大任务数)均衡。
在没有机器有空闲资源(包括提交方自身)时,调度器会阻塞分配请求,避免过多任务压垮编译集群。
作者:NP132

