



571
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享设计并实现一个简单的网络设备驱动程序(基于 Linux-4.15.x 版本内核)
—— A Simpler Network Device Driver(下文简称 sndd)
snull模块实现在源码公开和支持模块化这样优点的加成下,Linux 系统非常适合作为学习编写设备驱动程序的环境。
设备驱动程序,是应用程序和除了CPU、内存等硬件设备之外的几乎所有外设打交道的桥梁。应用程序使用OS提供的统一接口——系统调用,就像使用了一把万能钥匙,可以打开并访问各种不同外设,而并不用关心这些设备本身的样子。
例如块设备,应用程序说打开它,然后读写一些数据,那么直接使用open,read,write这些系统调用就好了,并不需要考虑数据是怎么在光盘或者磁盘上使用什么不同的介质存储、被组织排列成什么顺序。
正因为有越来越多不同的设备出现,设备驱动也是种类繁杂,一般可以分为三类:字符设备驱动、块设备驱动和网络设备驱动。这样分类有利于模块化编程,但是,当然,对于复杂的设备,也可以把这些都综合为一个模块(以灵活性为代价)。
对于字符设备驱动和块设备驱动来说,Linux 系统都会在/dev目录下创建一个文件节点,把它们都抽象为一个文件,可以打开关闭、可以读写也可以进行配置。
网络设备是要和外界互联的,网络驱动程序要异步地接收来自外界的数据包,然后向内核请求,把这些数据包发送给内核。这和块设备只响应内核的要求、只向固定缓冲区发送数据,是完全不同的。网络驱动没有必要留一个/dev下的节点,因为对它打开关闭也好、读写也罢,并没有实质的意义。网络驱动要做的就是,在收到数据包的时候,发送给内核;在内核要发送数据包的时候,它进行封装(自己的硬件头部)然后发送。
如果说网络驱动是一把万能钥匙,那也是开大门的钥匙吧,那就是在内核了。这是在应用程序和驱动程序的角度来看。
如果说从网络的分层来看,网络驱动程序就是很底层了。LDD3 中提到,Linux 的网络子系统被设计为和协议完全无关。协议隐藏在驱动程序之后,而物理传输又被隐藏在协议之后。内核和网络驱动之间的交互,可能每次处理的是一个网络数据包。
但是同样值得指出的是,驱动接收的是外界发送的数据包,但是传输时要给上层传递下来的数据包封装一个 MAC 的头部信息。所以驱动会使用硬件协议,但是处理传输的是 IP 数据包。

sndd 实现一个基于内存的网络驱动模块,模拟了网络接口和远程主机通信的过程。
sndd 中使用的接口不依赖于任何硬件,是纯软件实现的数据包传输和发送。
在二层协议上选择以太网协议,处理传输的是 IP 数据包(对其他非 IP 数据包的修改会破坏原本数据包)。
由于使用以太网协议,在实际测试的时候可以使用 tcpdump 工具进行抓包验证数据包的传输。
驱动模拟了四个网络接口,接口名:sndd0,sndd1,sndd2 和 sndd3
对应的主机名为 lc0,lc1,lc2 和 lc3
三个接口位于三个不同的子网,网络名分别为 snet0,snet1,snet2 和 snet3
在三个网段中,各自分别有一台主机,主机名:rm0,rm1,rm2 和 rm3
网络结构如下图所示:
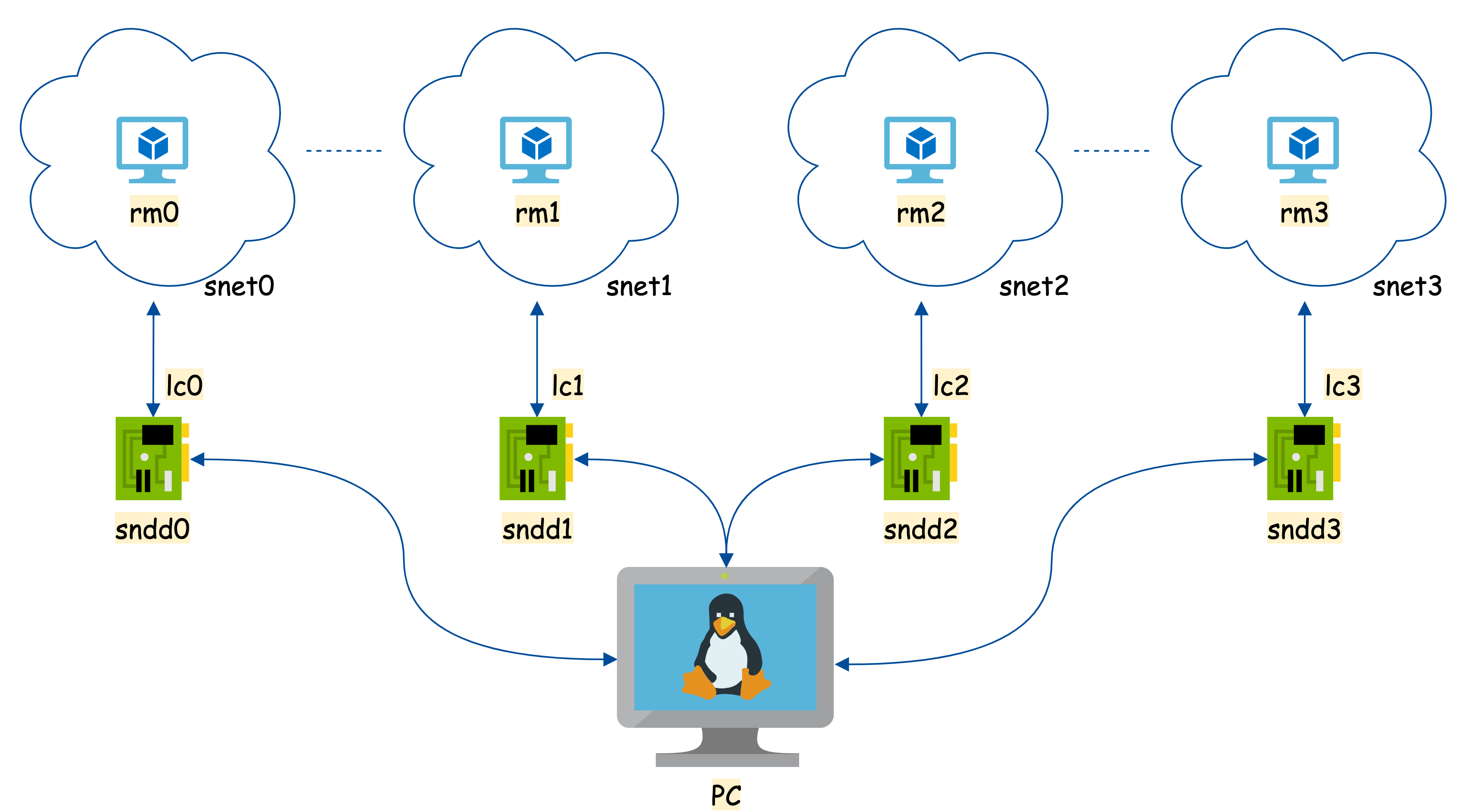
驱动要实现的功能如下,两个扩展的回环网络:
rm0 的数据包,要从 sn1 接收到rm1 的数据包,要从 sn0 接收到rm2 的数据包,要从 sn3 接收到rm3 的数据包,要从 sn2 接收到为了实现上述功能,给各接口和主机分配 IP 地址如下:
# 网络号 /etc/networks
snet0 192.168.4.0
snet1 192.168.5.0
snet2 192.168.6.0
snet3 192.168.7.0
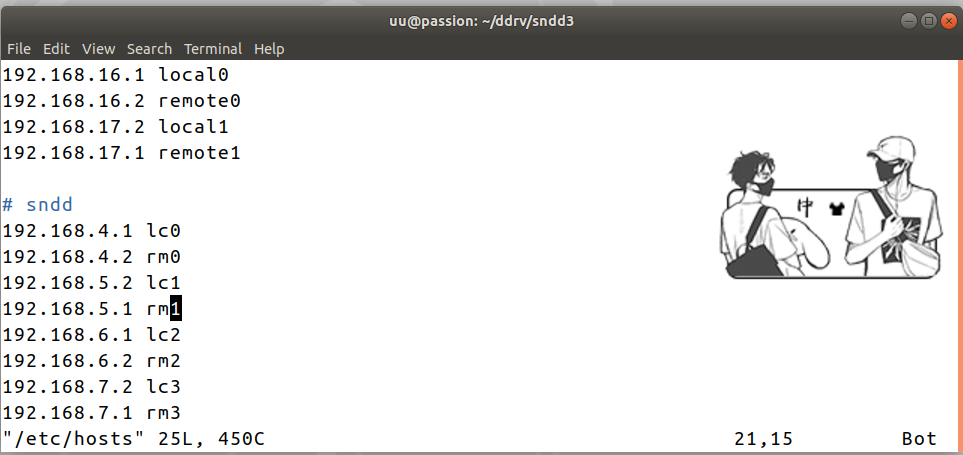
# 主机号 /etc/hosts
192.168.4.1 lc0
192.168.4.2 rm0
192.168.5.2 lc1
192.168.5.1 rm1
192.168.6.1 lc2
192.168.6.2 rm2
192.168.7.2 lc3
192.168.7.1 rm3
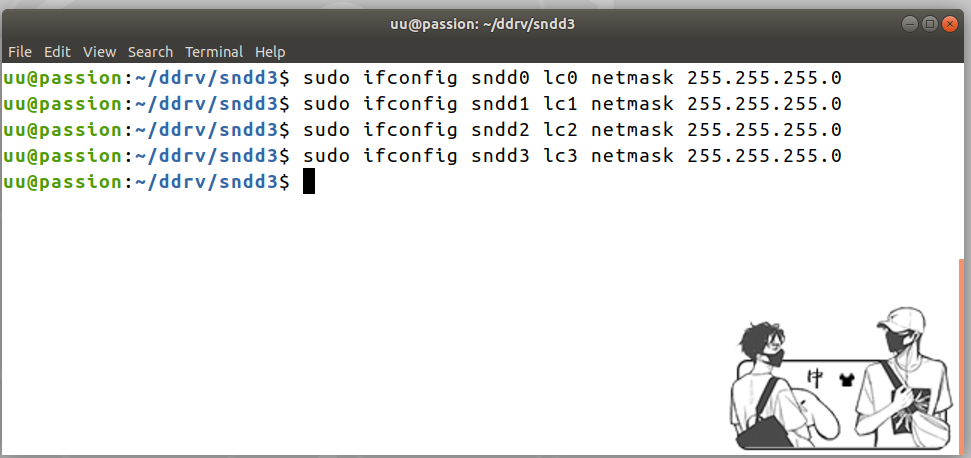
同时,在终端里配置网络接口:
$ sudo ifconfig sndd0 lc0 netmask 255.255.255.0
$ sudo ifconfig sndd1 lc1 netmask 255.255.255.0
$ sudo ifconfig sndd2 lc2 netmask 255.255.255.0
$ sudo ifconfig sndd3 lc3 netmask 255.255.255.0
根据所设置的 IP 地址,为了实现功能,要在驱动中接收到数据包时,修改 IP 数据包的头部中的源 IP 地址和目的 IP 地址:
实现一个简单的模块,至少需要包含如下几个部分:
对于要实现的简单网络设备驱动,
包含的数据结构:
struct net_device *struct header_opsstruct net_device_opsstruct sndd_packetstruct sndd_priv包含操作:
sndd_init_module()sndd_cleanup()sndd_init()sndd_open()sndd_release()sndd_tx()sndd_rx()sndd_header()sndd_get_tx_buffer()sndd_release_buffer()sndd_setup_pool()sndd_teardown_pool()sndd_enqueue_buf()sndd_dequeue_buf()sndd_regular_interrupt()net_device_stats *sndd_stats()sndd_ioctl()使用一些简化:
首先是每个模块的注册和注销函数:
module_init(sndd_init_module);
module_exit(sndd_cleanup);
注册,完成的功能就是给每个接口申请内存(在这个步骤里要进行接口的初始化 sndd_init),最关键的就是使用注册函数register_netdev(sndd_devs[i]),把接口注册到内核中。
/*
* Register the module
*/
int sndd_init_module(void)
{
int result, i, ret = -ENOMEM;
sndd_interrupt = sndd_regular_interrupt;
/* Allocate the devices */
sndd_devs[0] = alloc_netdev(sizeof(struct sndd_priv), "sndd%d",
NET_NAME_UNKNOWN, sndd_init);
sndd_devs[1] = alloc_netdev(sizeof(struct sndd_priv), "sndd%d",
NET_NAME_UNKNOWN, sndd_init);
sndd_devs[2] = alloc_netdev(sizeof(struct sndd_priv), "sndd%d",
NET_NAME_UNKNOWN, sndd_init);
sndd_devs[3] = alloc_netdev(sizeof(struct sndd_priv), "sndd%d",
NET_NAME_UNKNOWN, sndd_init);
if (sndd_devs[0] == NULL || sndd_devs[1] == NULL)
goto out;
ret = -ENODEV;
for (i = 0; i < 4; i++)
if ((result = register_netdev(sndd_devs[i])))
printk("sndd: error %i registering device \"%s\"\n",
result, sndd_devs[i]->name);
else
ret = 0;
out:
if (ret)
sndd_cleanup();
return ret;
}
注销,就是注册的倒序,先从内核中注销,然后清除内部的数据结构,最后释放接口。
/*
* Unregister the module
*/
void sndd_cleanup(void)
{
int i;
for (i = 0; i < 4; i++) {
if (sndd_devs[i]) {
unregister_netdev(sndd_devs[i]);
sndd_teardown_pool(sndd_devs[i]);
free_netdev(sndd_devs[i]);
}
}
return;
}
初始化:
/*
* The init function (sometimes called probe).
* It is invoked by register_netdev()
*/
void sndd_init(struct net_device *dev)
{
struct sndd_priv *priv;
/*
* Then, assign other fields in dev, using ether_setup() and some
* hand assignments
*/
ether_setup(dev); /* assign some of the fields */
dev->netdev_ops = &sndd_netdev_ops;
dev->header_ops = &sndd_header_ops;
/* keep the default flags, just add NOARP */
dev->flags |= IFF_NOARP;
dev->features |= NETIF_F_HW_CSUM;
/*
* Then, initialize the priv field. This encloses the statistics
* and a few private fields.
*/
priv = netdev_priv(dev);
memset(priv, 0, sizeof(struct sndd_priv));
spin_lock_init(&priv->lock);
priv->dev = dev;
sndd_rx_ints(dev, 1); /* enable receive interrupts */
sndd_setup_pool(dev);
}
从上层接收到的数据包,要先封装硬件协议(这里是以太网协议)的头部,然后放入发送队列。
每一个数据包都包含在一个 sk_buff 结构中,就是一个 socket 缓冲区。
最后调用 sndd_hw_tx 实现网络驱动的具体操作,就是修改源和目的,实现一个回环功能。
/*
* Transmit a packet (called by the kernel)
*/
int sndd_tx(struct sk_buff *skb, struct net_device *dev)
{
int len;
char *data, shortpkt[ETH_ZLEN];
struct sndd_priv *priv = netdev_priv(dev);
data = skb->data;
len = skb->len;
if (len < ETH_ZLEN) {
memset(shortpkt, 0, ETH_ZLEN);
memcpy(shortpkt, skb->data, skb->len);
len = ETH_ZLEN;
data = shortpkt;
}
netif_trans_update(dev);
/* Remember the skb, so we can free it at interrupt time */
priv->skb = skb;
/* actual deliver of data is device-specific, and not shown here */
sndd_hw_tx(data, len, dev);
return 0; /* Our simple device can not fail */
}
由于是使用中断驱动,当数据包异步到达的时候,中断程序调用 sndd_rx 将数据包和附加信息发送到上层。
/*
* Receive a packet: retrieve, encapsulate and pass over to upper levels
*/
void sndd_rx(struct net_device *dev, struct sndd_packet *pkt)
{
struct sk_buff *skb;
struct sndd_priv *priv = netdev_priv(dev);
/*
* The packet has been retrieved from the transmission
* medium. Build an skb around it, so upper layers can handle it
*/
skb = dev_alloc_skb(pkt->datalen + 2);
if (!skb) {
if (printk_ratelimit())
printk(KERN_NOTICE "sndd rx: low on mem - packet dropped\n");
priv->stats.rx_dropped++;
goto out;
}
skb_reserve(skb, 2); /* align IP on 16B boundary */
memcpy(skb_put(skb, pkt->datalen), pkt->data, pkt->datalen);
/* Write metadata, and then pass to the receive level */
skb->dev = dev;
skb->protocol = eth_type_trans(skb, dev);
skb->ip_summed = CHECKSUM_UNNECESSARY; /* don't check it */
priv->stats.rx_packets++;
priv->stats.rx_bytes += pkt->datalen;
netif_rx(skb);
out:
return;
}
更多具体的实现可见源代码并参考 LDD3 中的 snull 模块。
利用 Makefile 生产 .ko 加载到内核之后,使用 ping 和 tcpdump 可以测试本驱动。
和 LDD3 中所给示例基本是一样的。
# Comment/uncomment the following line to disable/enable debugging
#DEBUG = y
# Add your debugging flag (or not) to CFLAGS
ifeq ($(DEBUG),y)
DEBFLAGS = -O -g -DSNULL_DEBUG # "-O" is needed to expand inlines
else
DEBFLAGS = -O2
endif
EXTRA_CFLAGS += $(DEBFLAGS)
EXTRA_CFLAGS += -I..
ifneq ($(KERNELRELEASE),)
# call from kernel build system
obj-m := sndd.o
else
KERNELDIR ?= /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
default:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
endif
clean:
rm -rf *.o *~ core .depend .*.cmd *.ko *.mod.c .tmp_versions *.mod modules.order *.symvers
depend .depend dep:
$(CC) $(EXTRA_CFLAGS) -M *.c > .depend
ifeq (.depend,$(wildcard .depend))
include .depend
endif
$ make
$ sudo insmod sndd.ko
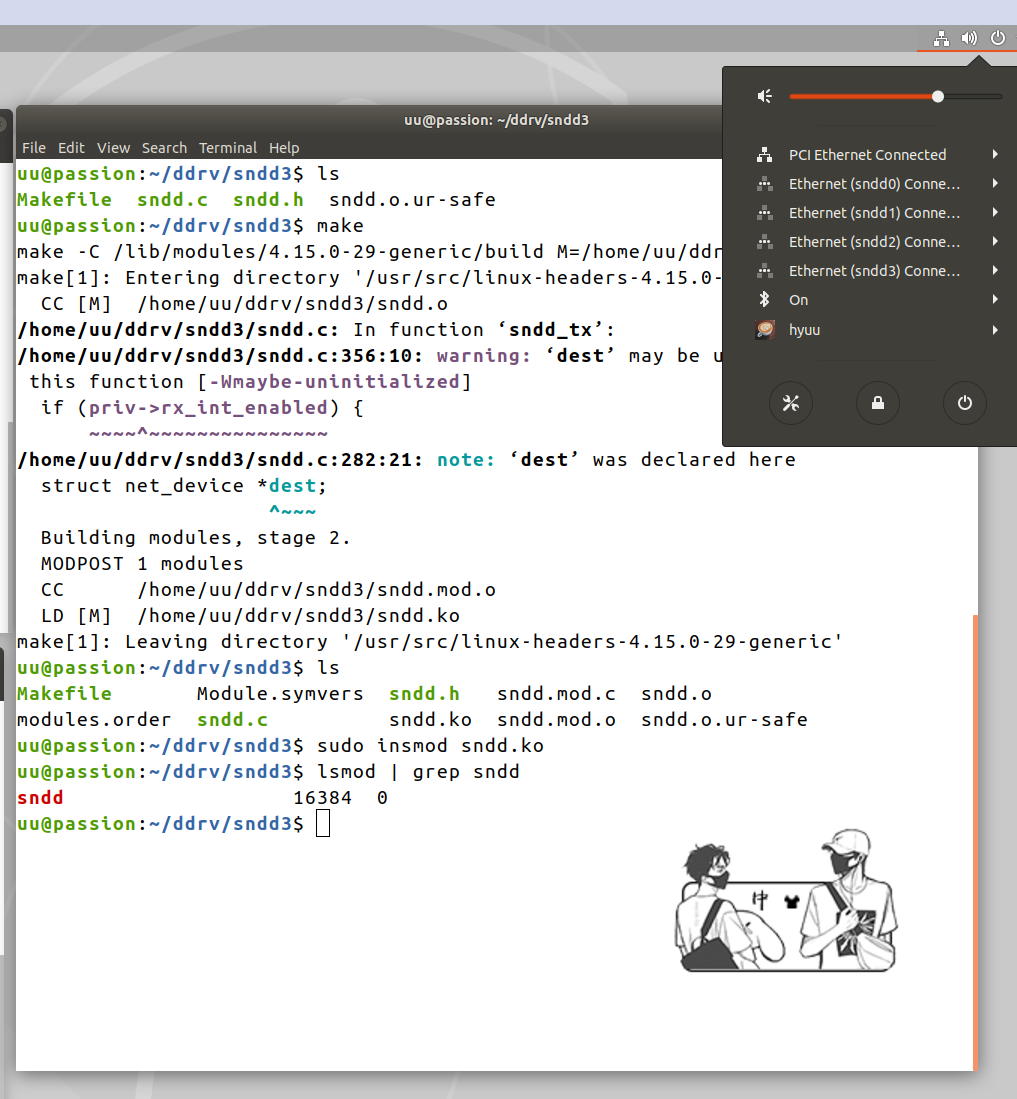
模块加载到内核之后,模拟的网络接口就出现了,使用 ifconfig 命令可以查看:
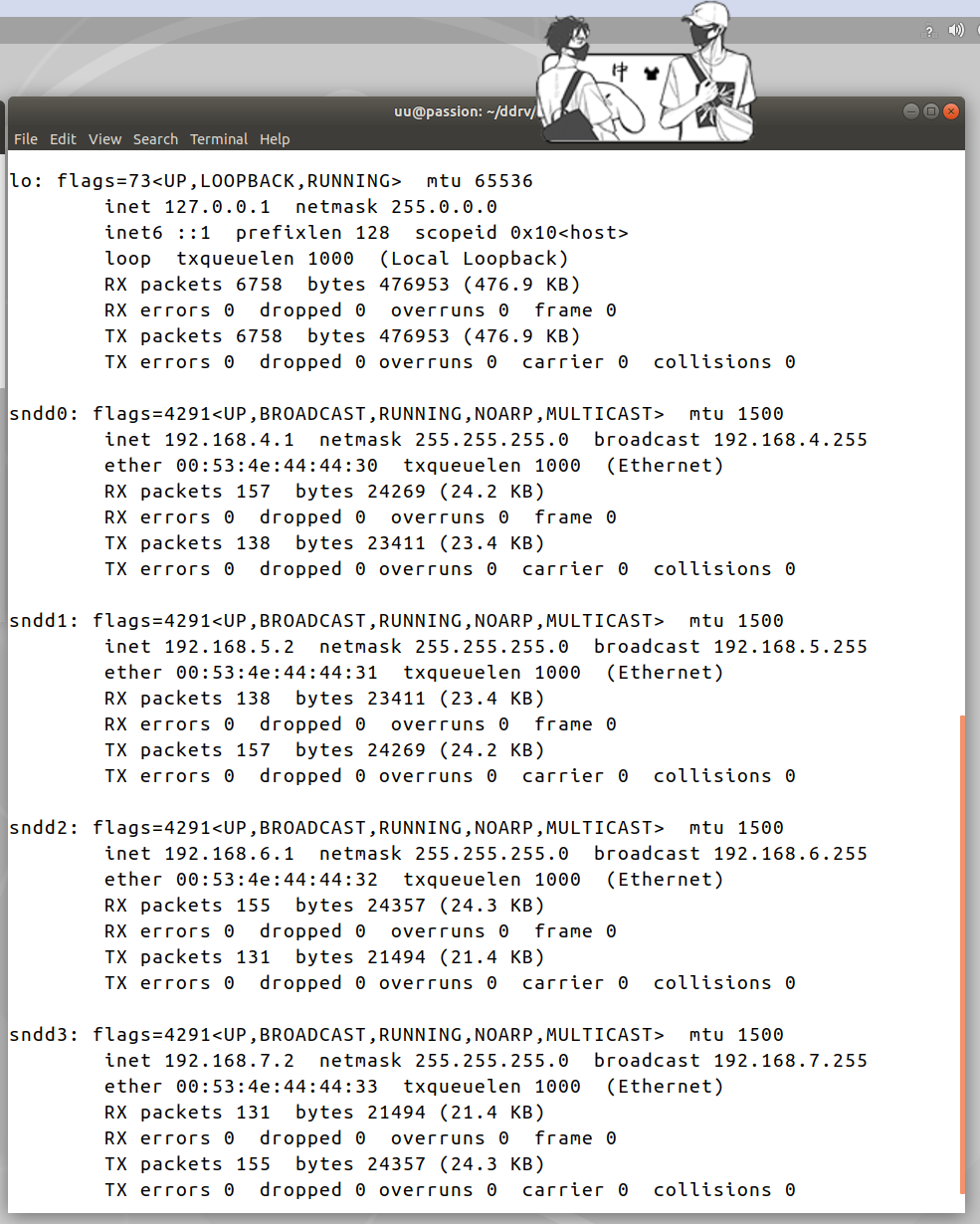
如前所述,配置网络和主机号,同时绑定接口的 IP。
测试效果如下图。
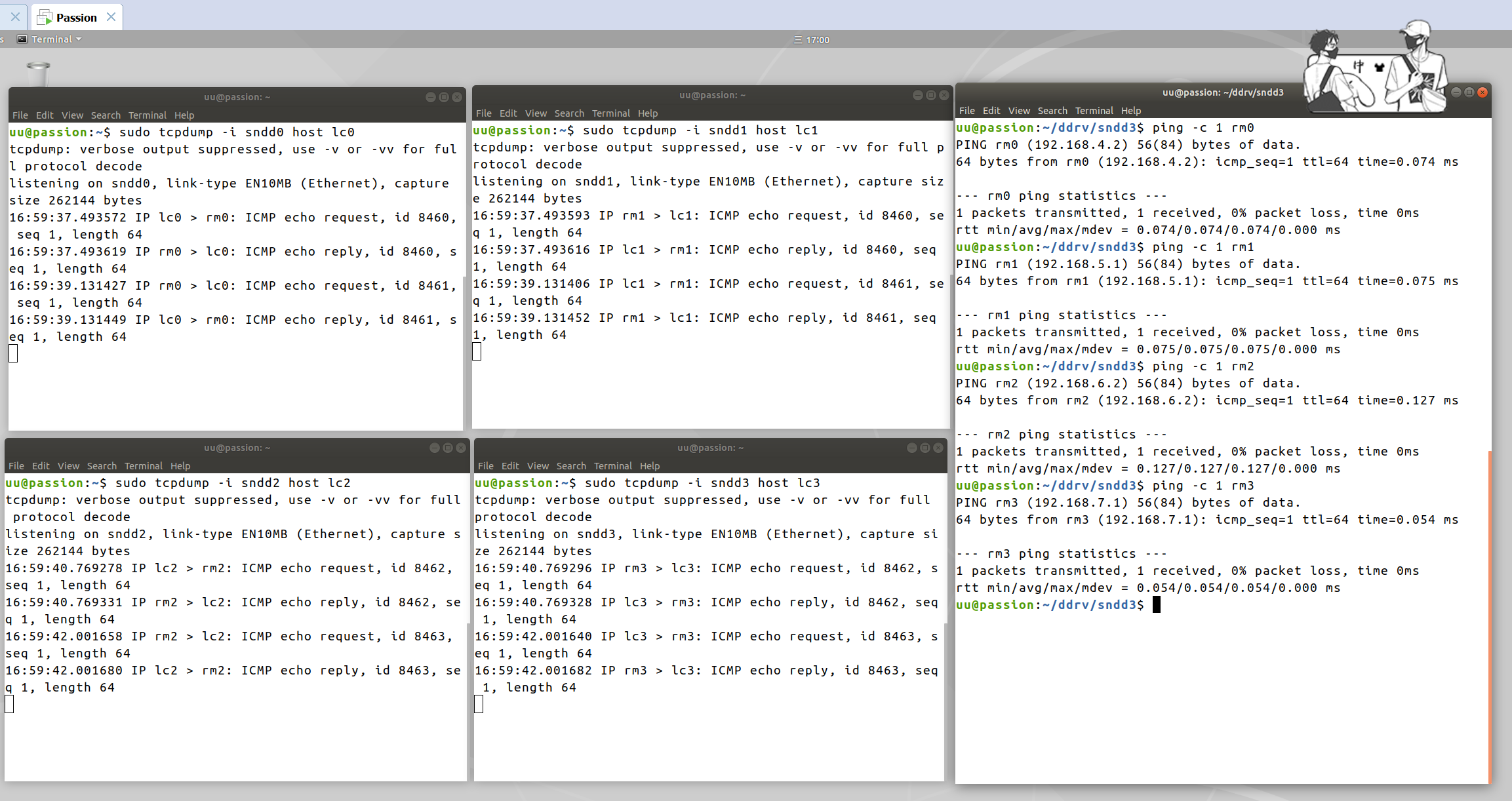
当发出ping -c1 1 rm0命令,发送目的地址为 rm0 的数据包请求时,按顺序发送了如下事件:
sndd0 上观察到,从 lc0 > rm0 发起了一次请求;sndd1 上观察到,从 rm1 > lc1 发起了一次请求;sndd1 上观察到,从 lc1 > rm1 发起了一次回应;sndd0 上观察到,从 rm0 > lc0 发起了一次回应。这个过程就实现了一个扩展的回环网络,从 lc0 到 lc1,然后从 lc1 再到 lc0,实现了一次双向的通信。
同理,使用 ping 访问 rm1,rm2 和 rm3 时,也实现了这样的过程。
ifconfig 配置一下;snull 示例参考代码(基于新版内核修改):https://github.com/martinezjavier/ldd3snull 在新版内核上编译不通过问题:Linux设备驱动程序(LDD)中snull的编译问题作者:NP 244

