


17
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享通常情况下,任何数据库在涉及到性能优化时候,除了参数设置之外,剩下较为关键部分就是如何建立更高效更合理的表结构,QianBase V1也不例外。
本文主要介绍V1常见的建表方式,不一样的建表方式,对SQL执行耗时,会有不同的影响,整体总结而言,主要有下述几个关键选项:
注:上述5类选项,建表时都为可选项
QianBase V1中的表是按簇键(Cluster Key)顺序存储的,所以我们通常认为QianBase的表本身也是一个索引。主键是具有唯一约束的特殊簇键。我们应优先选择那些在WHERE过滤中经常用到的字段作为主键或簇键字段。主键或簇键的设计一般要遵循以下规则,
主键或簇键可以包含一个或多个字段,字段的先后也是非常严格的。
键应尽可能短,尤其是表不使用Aligned Format的时候。
[1] Key中应尽量避免使用CHAR/VARCHAR类型,尤其是比较长的字段。如果CHAR/VARCHAR字段是UTF8格式,尽量使用”n BYTES”而非”n CHARS”,避免为每个字符分配4个bytes。
[2] 不要因为唯一性要求而把Key设置在太多字段上。唯一性可以通过以下一些方式实现。
如何不适合创建Primary Key,下面提供一些方法保证Key的唯一性。
[1] 使用Store By代替,Store By会生成一个隐藏列”SYSKEY”作为Key的最后一个字段。SYSKEY在每一行都是唯一的。
[2] 使用一个CHAR(16)类型的字段作为Key的最后一个字段。当表有数据插入时,使用unique_id()函数生成一个唯一值。
[3] 使用IDENTITY。对于批量插入如Bulk Load或Upsert需要把Cache Size设置大一些(默认25太小)。
注:
QianBase V1 在定义表结构时,支持主键/Store by键的字段为空(但实际数据库server端会存一个非空串),例如primary key nullable(col1,col2)
QianBase V1允许在主键或簇键的子集上进行Salting(盐粒分布)。Salting的目的是把数据均衡分布到不同的Region服务器中,从而避免查询热点问题(只从单个Region服务器查询)。Salting会生成一个hash值作为Key的前缀。如果查询语句的WHERE条件中包含Salt中的字段,那么查询很可能只需要查询对应的Region区域。默认情况下,Salting字段即主键或簇键所有字段,不过也可以选择部分字段作为Salting字段。选择Salting键的原则一般如下:
Salting Key字段组合的UEC必须至少是表partition个数的200倍或更多。表中列的UEC可以通过先更新表的统计信息再通过SHOWSTATS查询。UEC可以通过showstats查看。
Salting Key不能要严重的数据倾斜。数据倾斜会导致数据分布不均从而导致查询性能问题。可以使用SELECT "_SALT_", count(*) from group by 1 order by 2; 来查看数据倾斜问题。
最具有代表性的OLTP查询是WHERE条件中Salting Key中的每个字段都有”=”限制,这样查询会只定位到某一个或很少的几个region上面。
基于上述3个条件,尽量选择一个最少的Salting Key的字段组合。
对于join较多的表,根据经常使用的join字段对表进行Salting,这可以使得只关联到指定的region。
对于高并发场景,应该用高并发查询字段进行Salting
HBase表在表数据量增长时会自动Split。如果能在建表的时候进行预分区,可以防止在业务繁忙的时候频繁Split。
表的region个数可以通过region最大尺寸推断(默认一个region大小是10G,建议增大到100G)。可以在Salt子句中定义建表时创建多少个region。
对于表的扫描,并发度的最大值等于partition的数量。
设置分区数一般原则如下:
[1].分区数要根据节点数、磁盘数及表的据量综合考量,不宜随意指定,一般是节点数的N倍(最佳实践为1=<N<=10),一般设置表的最大region数为8到10*nodes,比如总共有6个nodes,那么最大的region数为8*6=48或者60个。
[2].对于小表(如 <100万)可不分区;对于大表(如>1000万)可适当分区,分区数一般为节点的 n倍( n<=10),生产环境下,每个分区的数据在百万或10G~100G)较合适
[3].单个HBase RS个尽量不超过1000个region,否则HBase可能运行不稳定。
[4].表的分区数可以自适应数据量的变化,使用SALT USING 192 PARTITIONS IN 4 REGIONS语句,初始4个分区,最大192个分区。
注:
1. 在有主键或者Store By键前提下,才能谈分区键或者分区数
2. 分区键可以是主键或者Store By键中字段的单个或者组合
3. 如果primary key (a,b) salt using 10 partititon on (a),那数据实际是按照"_SALT_",a,b顺序排序
4. 第3点中,"_SALT_"列的值,对a字段的取值经哈希计算得出
5. 如果salt using 10 partititon但不注明on哪个字段,那会按照主键所有列来hash预分区
division by属于一种数据属于相对比较取巧的数据排序方式,在某些分析场景的SQL下,可以节约一个索隐引
简单而言,如果主键为(A,B,C)division by (DATE_TRUNC('DAY',C)),那实际数据排序会按照DATE_TRUNC('DAY',C),A,B,C四个列来排序
并且,只有在有主键或者Store by键时,才能新建division by选项
注:
1. Division By也是在有主键或者Store By键前提下
2. Division by通常用在时延要求大于100ms的sql中
3. primary key (a,b) salt using 10 partititon on (a) division by (date_trunc('day',b)),那数据实际是按照"_SALT_","_DIVISION_",a,b顺序排序

[1].Replicate表,也可称为复制表
[2].Replicate 4 ways,意味该表会建立成4个分区,每个分区都有一样的数据,并编号0-3。建议复制数与节点数相同。
[3].建议只读表设置为replicate表,或者读占绝大部分场景
[4].作用:降低单分区小表的并发读热点
注:
对应的索引也会继承replicate属性
QianBase V1沿用了几种常见的HBase Option,例如:
[1] DATA_BLOCK_ENCODING -- 数据块编码方式
[2] COMPRESSION -- 压缩方式
[3] MEMSTORE_FLUSH_SIZE -- memstore刷磁盘的阈值大小
[4] PREFETCH_BLOCKS_ON_OPEN -- blockcache预期选项
[5] IN_MEMORY -- 数据是否优先放缓存
[6] DURABILITY -- WAL方式,可选的值有ASYNC_WAL, FSYNC_WAL, SKIP_WAL,SYNC_WAL(默认值),USE_DEFAULT等
【下面列举几种常用建表的案例】

[1].该表没有HBASE_OPTION
[2].数据不会压缩
[3].表只有一个分区,在表大小达到分区的临界值(100G之后),HBase会将该分区自动分裂成2个分区
[4].一般不推荐该种表结构
[5] 该表在数据库端后台,会自动生成唯一的key,即syskey,作为K-V存储中的键值部分(syskey可以直接通过select syskey,* from trafodion.seabase.no_hbopt查询出来,并且数据按照syskey排序),这里syskey是伪列

[1].对于数据量较小的表,不需要建立分区
[2].该表没有主键
[3].一般不推荐该种表结构
[4] 该表在数据库端后台,也会自动生成唯一的key,作为K-V存储中的键值部分

[1].该表定义了主键
[2].该表未预分区(默认1个分区)
[3].适用于小表,并且对该表并发查询较低情况
[4].此时数据按照(b,a)排序,实际存储主键也是(b,a)

[1].该表主键列可以为空
[2].如果因业务无法确定是否字段为空,但又碍于需要建立主键并预分区,可以使用该做法
[3].该做法才易鲸捷实际场景使用并不冷门
[4].此时数据按照("_SALT_",b,a)排序,实际存储主键也是("_SALT_",b,a),这里"_SALT_"是伪列,并且可以根据(b,a)组合的值哈希算出来
[5].该表预分成了8个分区

[1].通常情况下,如果表有主键,请设置主键
[2].分区数一般视数据量与节点数而定。物理机条件下,一般按照100万数据量1个分区。如果节点数是3,那500万数据量可以分成6个分区。
[3].极端情况下,表数据量非常大,那可以考虑1000万数据量一个分区,分区数一般不要超过节点数*10
[4].此时数据按照("_SALT_",b,a)排序,实际存储主键也是("_SALT_",b,a),这里"_SALT_"是伪列,也可以根据(b,a)组合的值哈希算出来

[1].如果表数据量较大,需要分区,但是并不能设置主键(比如说有重复值),请使用store by方式来分区
[2].分区键a请选择UEC较大的列,UEC需要超过分区数200倍
[3].a列的UEC代表a列中不同值的个数,也就是count(distinct)的数量,表示该列数据分散情况
[4].默认store by的字段不可为空
[5].此时数据按照("_SALT_",b,a,syskey)排序,实际存储主键也是("_SALT_",b,a,syskey),这里"_SALT_"与syskey都是伪列,并且"_SALT_"可以根据b的值哈希算出来
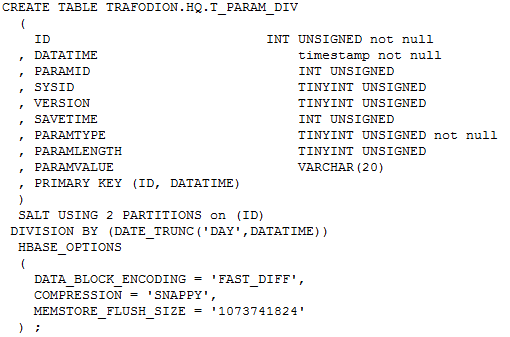
[1].如果同时考虑写入性能、基于ID列查询、基于DATATIME列查询三种情况,可以考虑如上表结构
[2].该表结构,不会创建隐式索引
[3].此时数据按照("_SALT_","_DIVISION_",ID,DATATIME)排序,实际存储主键也是("_SALT_","_DIVISION_",ID,DATATIME),这里"_SALT_"与"_DIVISION_"都是伪列,并且"_SALT_"可以根据b的值哈希算出来,"_DIVISION_"根据DATE_TRUNC('DAY',DATATIME)计算

