



67,862
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Apache spark 是一个用于大规模数据处理的一站式分析引擎。它提供了 java、 scala、 python 和 r 的高级 api,同时支持图计算。它还支持一系列丰富的高级工具,包括 sql 和结构化数据处理的 spark sql、机器学习的 mllib、图形处理的 graphx 以及增量计算和流处理的结构化流。近10余年的发展,已经形成了一个庞大的生态,包括开源的数据湖解决方案Delta Lake,也将Spark作为核心计算引擎。
spark10年发展史:

spark生态:

Spark1.0:
Hadoop对数据的处理、加工依赖引擎MapReduce,在计算过程中需要将中间数据刷写到磁盘,导致计算效率较低,并且MapReduce编程模型较为复杂,实现简单的WordCount也要写很长的代码。Spark1.0的出现,解决了部分问题,1.0阶段最重要的四个特性。
1. 引入内存计算的理念解决中间结果落盘导致的效率低下。早期官网中给出数据,在理想状况下,性能可达到MR的100倍。
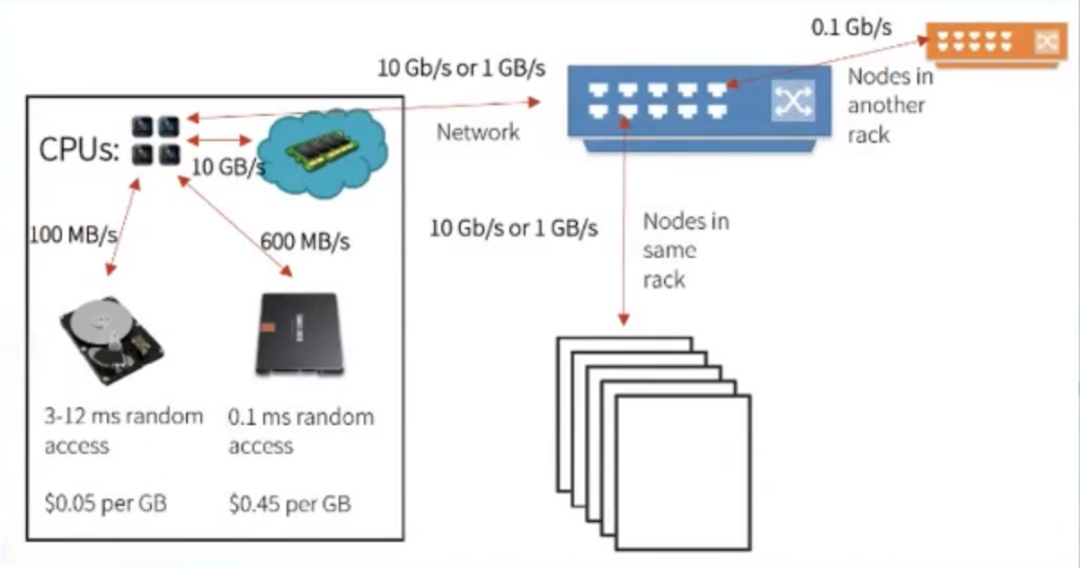
2. 支持丰富的API,支持多种编程语言,如Python、Scala、Java、R等,代码量减少5倍以上,并且受众群体更广。
3. 提供一站式的解决方案,同时支持离线、微批、图计算和机器学习。
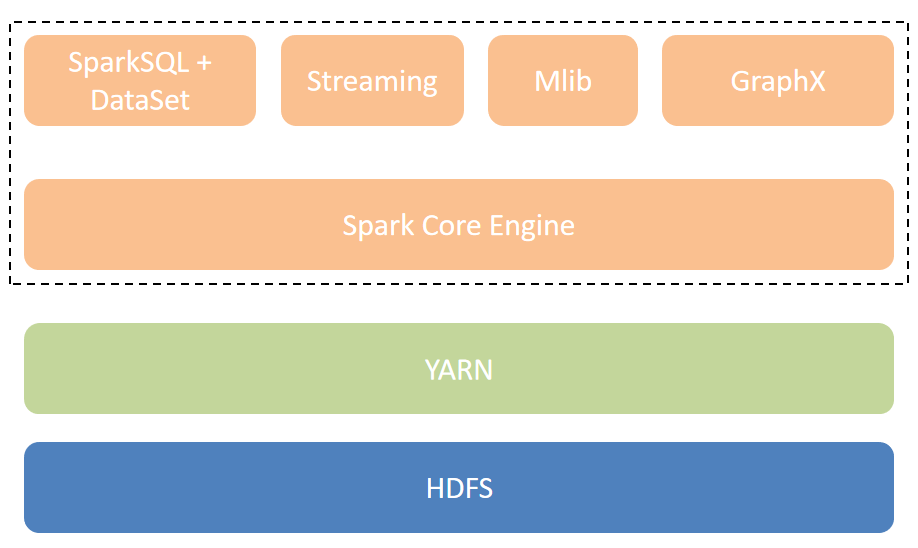
4. 支持多部署模式:支持Standalone、Cluster等多种模式。
Spark1.0的主要问题
内存计算的引入,虽然提高了一定的计算效率,但也带来了大量的内存管理问题,MR阶段的计算主要是磁盘IO带来的性能瓶颈,在Spark1.0阶段转换为了CPU性能瓶颈
早期Spark中SQL的支持主要依赖于Shark,而Shark对Hive的依赖太大,做版本的升级时需要考虑多方的兼容性,所以出现了迫切的SQL优化需求。
微批的流式计算接口不通用。
以上几个核心问题在Spark2.0中有了很好的改善。
Spark2.0
1. 引入Tungsten engine进行内存优化
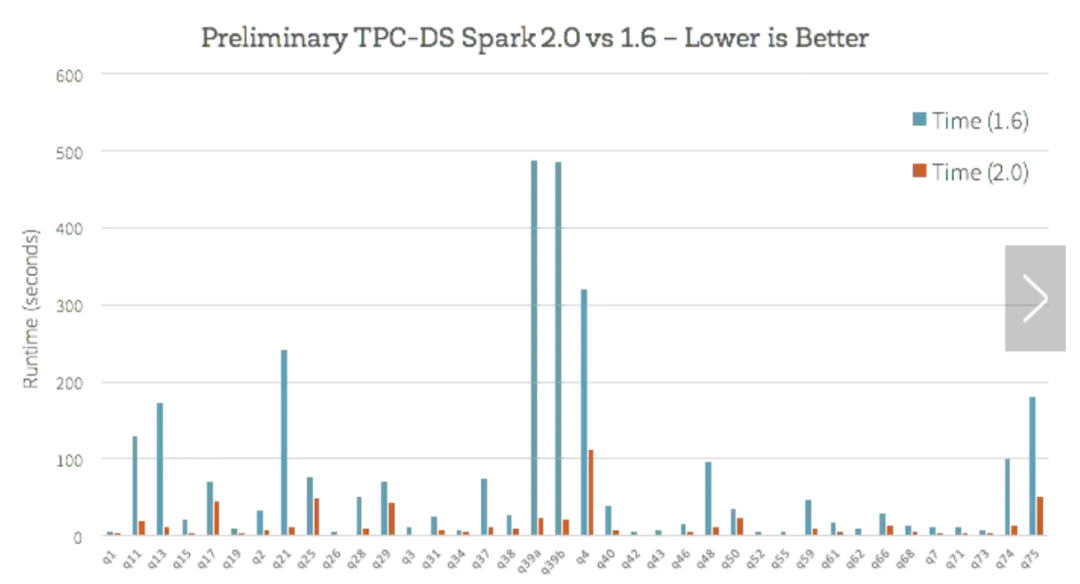
在Spark2.0中,首先是发起了一个名为“Tungsten”的项目,主攻Spark1.0中内存管理、 内存优化的问题。“Tungsten engine”是建立在现代编译器和MPP数据库上的想法,主要是通过运行期间优化那些拖慢整个查询的代码到一个单独的函数中,消除虚拟函数的调用以及利用CPU寄存器来存放中间数据,下图是Spark1.6和Spark2.0在一个核上处理一行的操作时间(单位:纳秒)

基于Spark1.6和Spark2.0在使用TPC-DS的基本分析,对比如下
2. 更好的SQL支持
在SQL支持层面,1.0阶段,SQL的很多功能并不能很好的支持,在2.0阶段,引入了ANSI SQL解析器,并且支持子查询,已经可以运行TPC-DS所有的99个查询,基本覆盖了常见的99%应用场景。
在编程API方面,对API做了精简,合并dataframe和datasets,1.6的dataset包含了dataframe的功能,这样两者存在很大冗余,所以2.0将两者统一,保留dataset api,把dataframe表示为dataset[Row],即dataset的子集。dataframe是sql查询结果rdd的抽象类,相当于java里的resultset。。引入了SparkSession,用于替代旧的SQLContext和HiveContext,之前在用1.6时,最大的困惑就是不知道用哪个Context,现在只需要使用SparkSession,就涵盖了两个Context。

3. 引入Structured Streaming
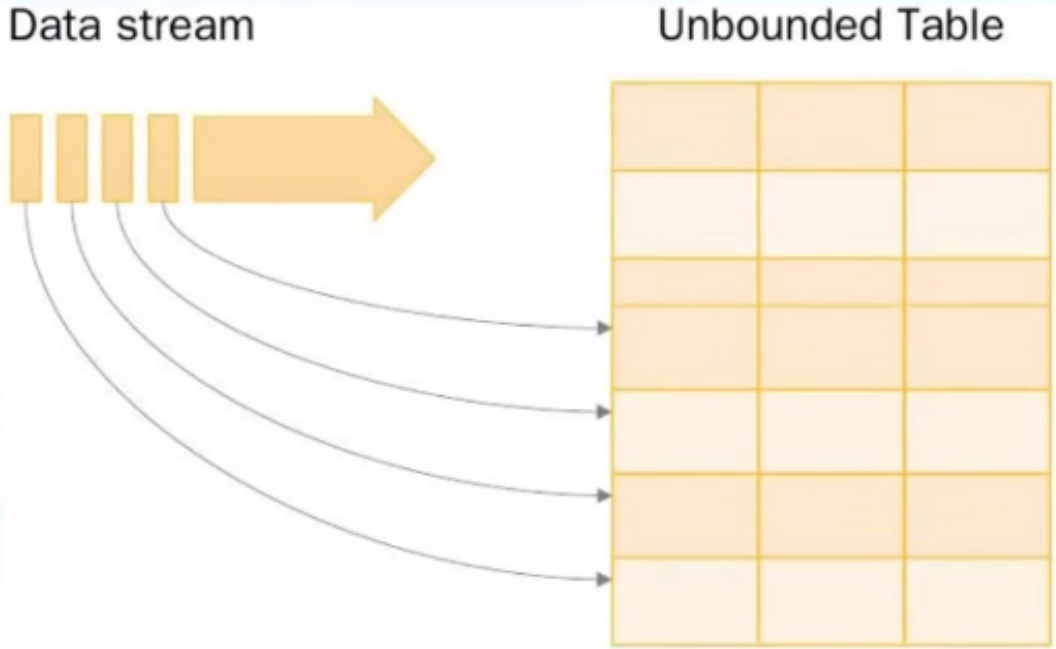
Structured Streaming是构建在Spark SQL引擎上的流式数据处理引擎,使用户可以像使用静态RDD一样来编写流式计算过程。当流数据连续不断的产生时,Spark SQL将会增量的,持续不断的处理这些数据并将结果更新到结果集中。Structured Streaming系统通过checkpoints和write ahead logs方式保证端到端数据的准确一次性以及容错性。简而言之,Structured Streaming提供了快速的,Scalable,容错的,端到端一次性的流数据处理,并且不需要用户关注数据流
Spark3.0
Spark3.0在2019年发布,在2.0的基础上又做了大量的优化,以下是最核心的几个关键特性。
动态分区裁剪(Dynamic Partition Pruning),是指根据运行时推断出的信息来进一步进行分区裁剪,达到数据剪枝优化,在之前的版本中,无法进行动态计算代价,在运行时会扫出大量无效的数据,经过这个优化,性能大概提升了33倍。主要参数 spark.sql.optimizer.dynamicPartitionPruning.enabled = true
自适应查询(Adaptive Query Execution):查询执行计划的优化,允许 Spark Planner 在运行时执行可选的执行计划,这些计划将基于运行时统计数据进行优化。AQE目前提供了三个功能,动态合并shuffle partitions、动态调整join策略、动态优化倾斜的join
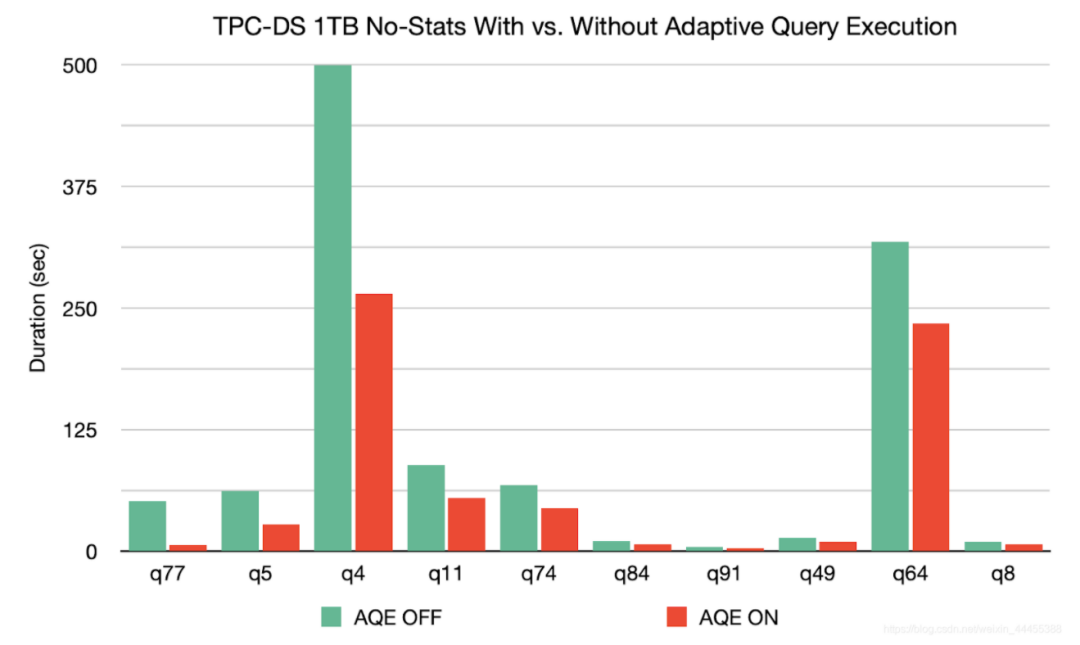
基于没有统计数据的 1TB TPC-DS 基准,Spark 3.0 可以使 q77 的速度提高8倍,使 q5 的速度提高2倍,而对另外26个查询的速度提高1.1倍以上。可以通过设置 SQL 配置 spark.sql.adaptive=true 来启用 AQE,这个参数默认值为 false
支持GPU等计算加速调度:大规模机器学习中,计算迭代时间会比较长,AI从业者会使用GPU、FPGA、TPU等加速计算,hadoop3.1已经支持GPU、FPGA。目前Spark的主要两个资源调度管理器Yarn和K8S都已经支持了GPU,spark支持GPU,在技术层面需要提供用户灵活的API,控制GPU资源的使用和分配。
可插拔的CataLog:支持DataSource的自定义扩展。
文章来源:https://www.modb.pro/db/336186

