


113
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享场景:我们在做数据模型(数据集)的时候,源表数据过多或其他复杂原因使得我们必须将源表结构转化、清洗为另一种结构的表,便于我们使用。
工具:自助分析--数据处理
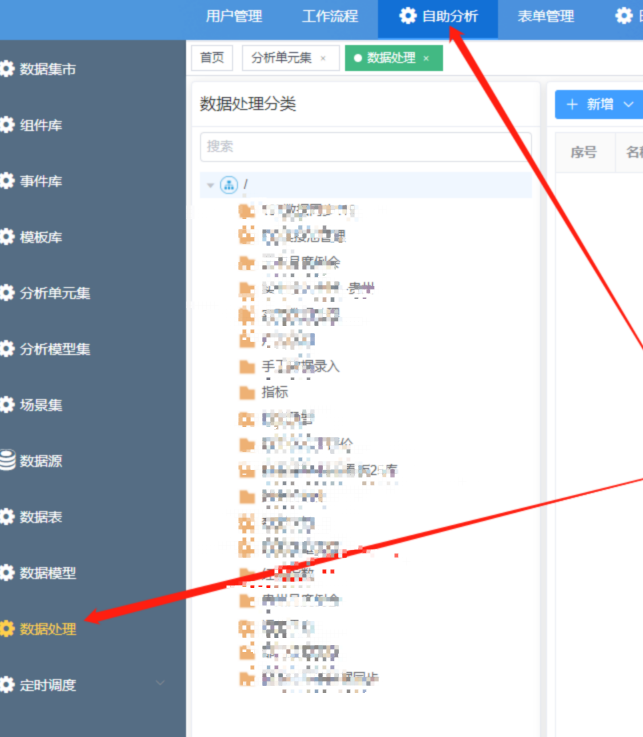
准备工作:将需要转换的表加入到数据源中:自助分析--数据源--选择所在数据源--新增[已有表],将源表添加到数据源
STEP1:打开数据处理界面,新增转换
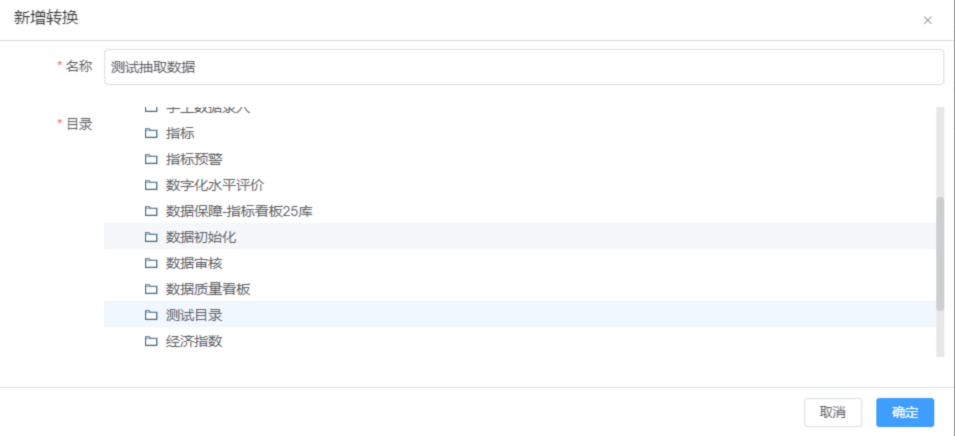
STEP2:点击新建转换后面的设计,打开一个新窗口
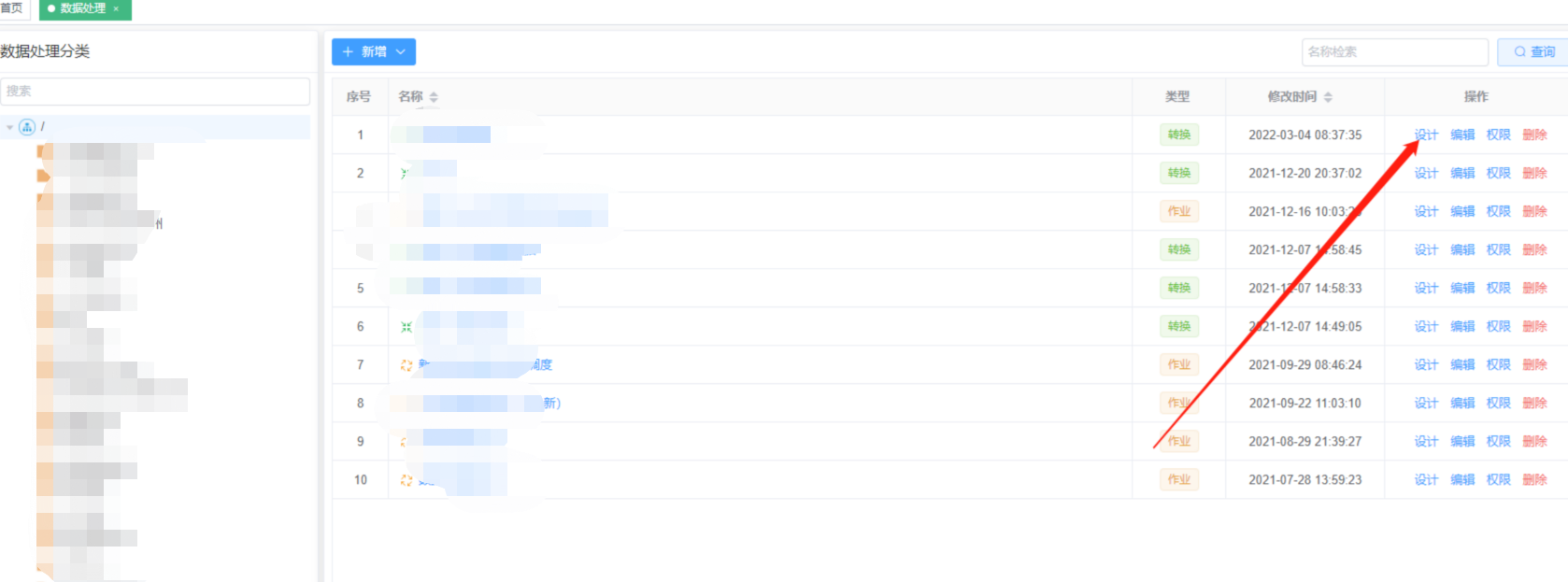
STEP3: 拖一个表输出和表输入
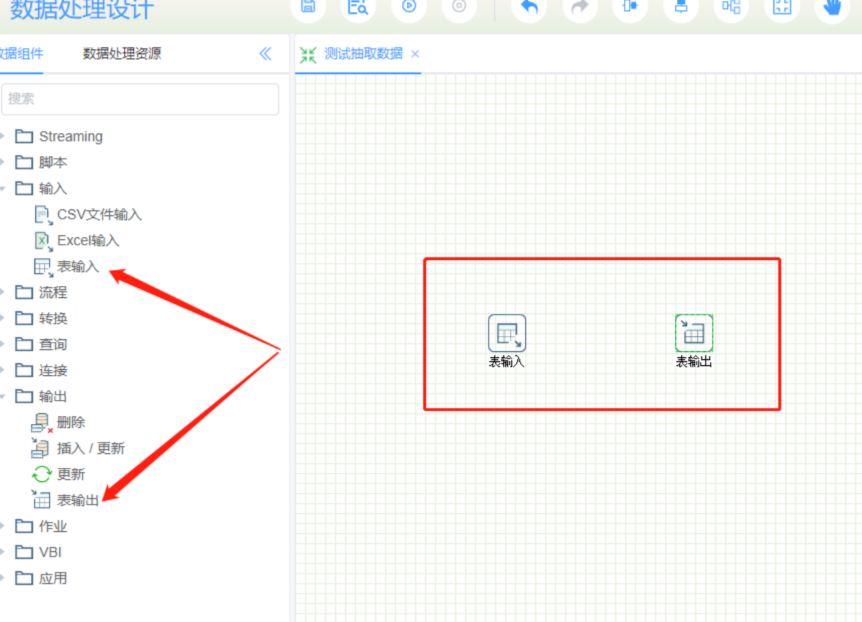
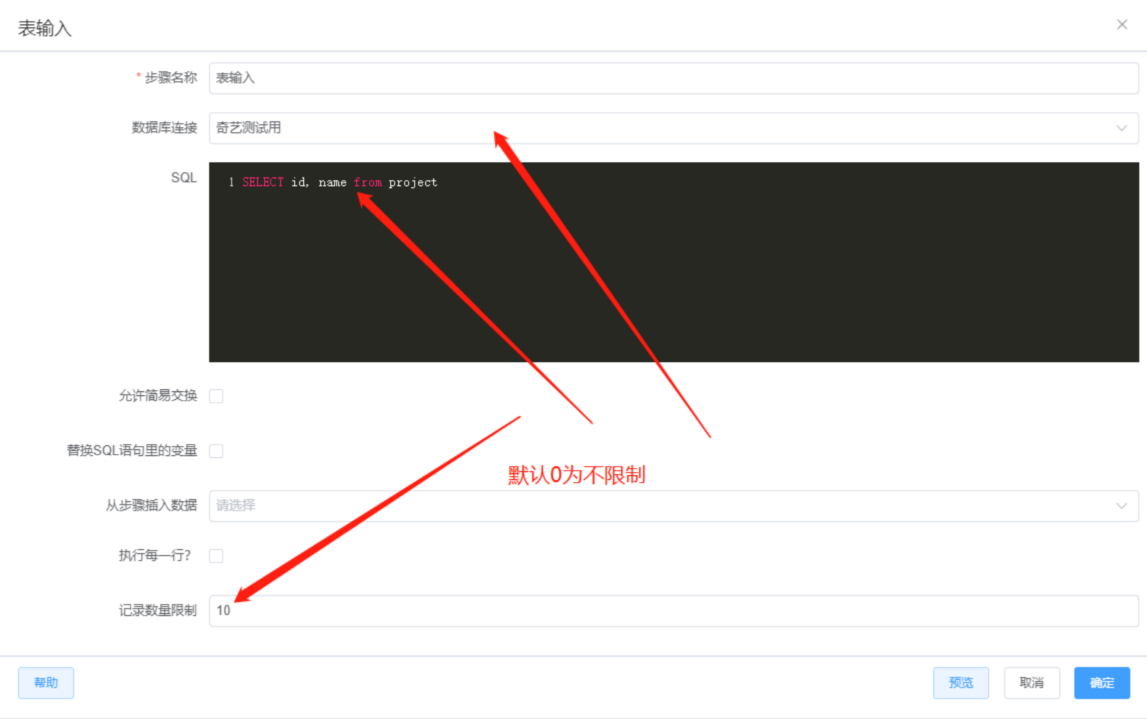
STEP4: 双击表输入,选择数据源,编写sql语句
STEP5: 连接表输入和表输出,双击表输出,选择数据源,模式名和表。点击更新选择输入和输出字段的关系
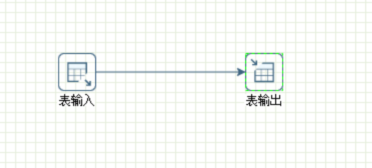
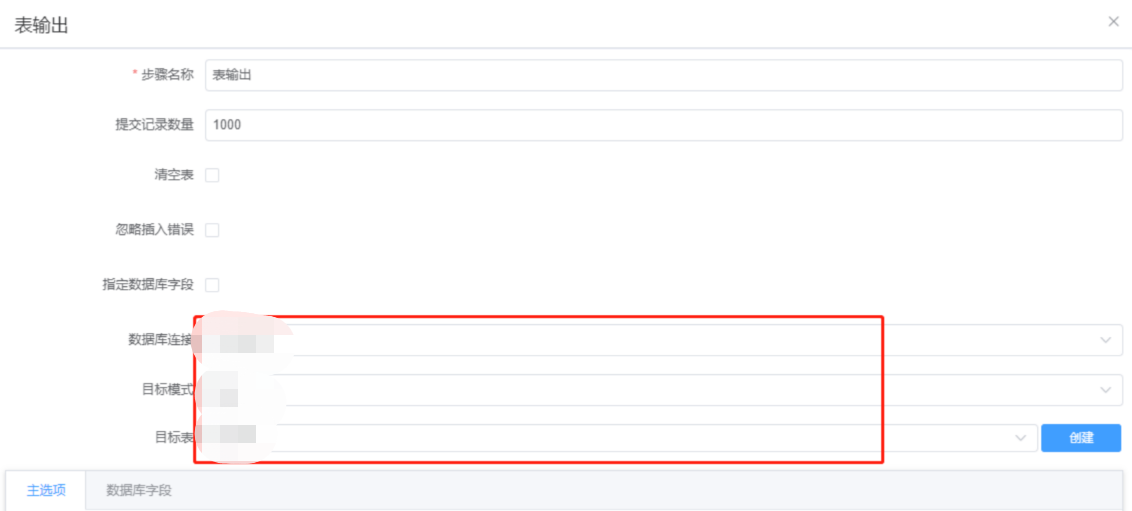
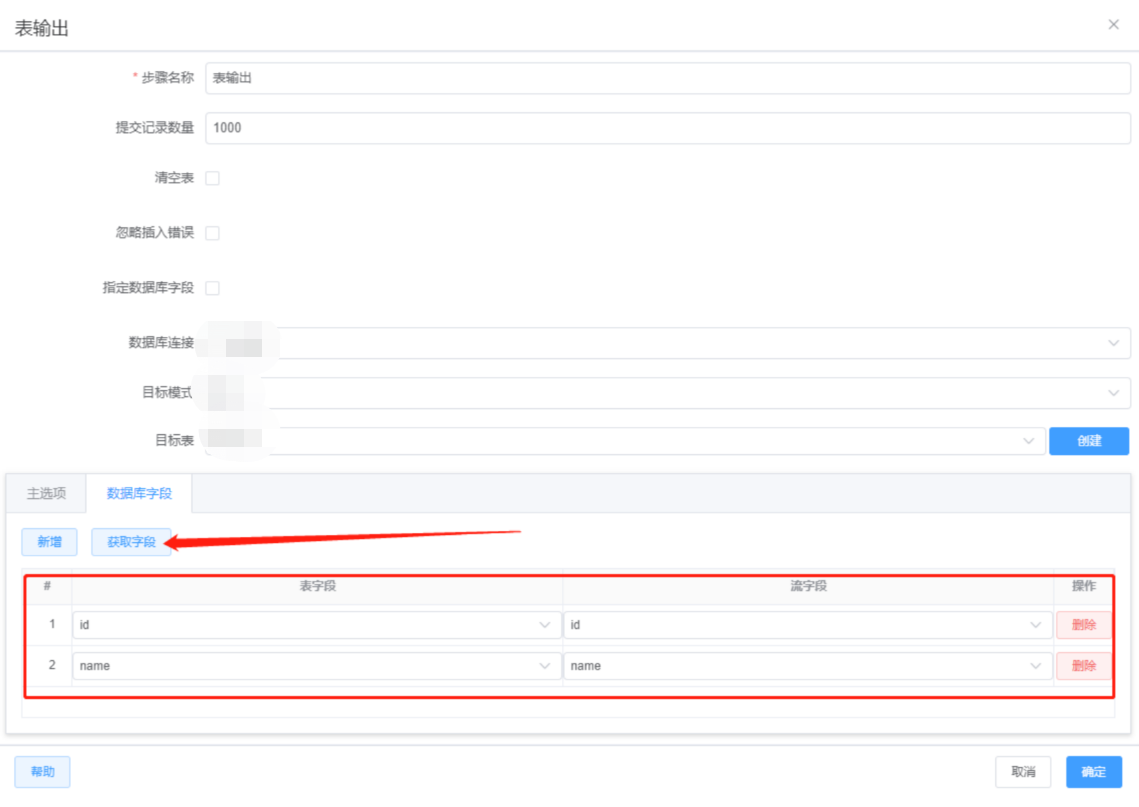
STEP6: 点击运行测试抽取结果
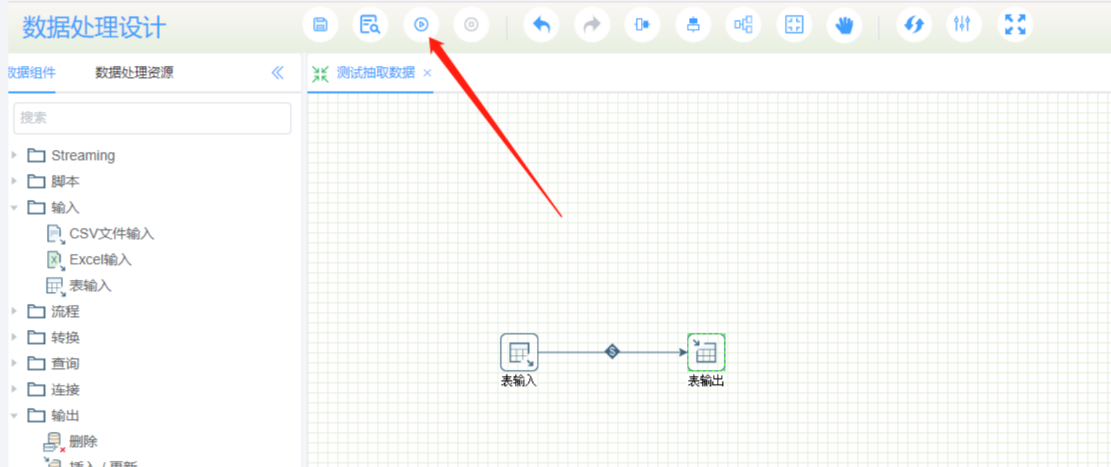
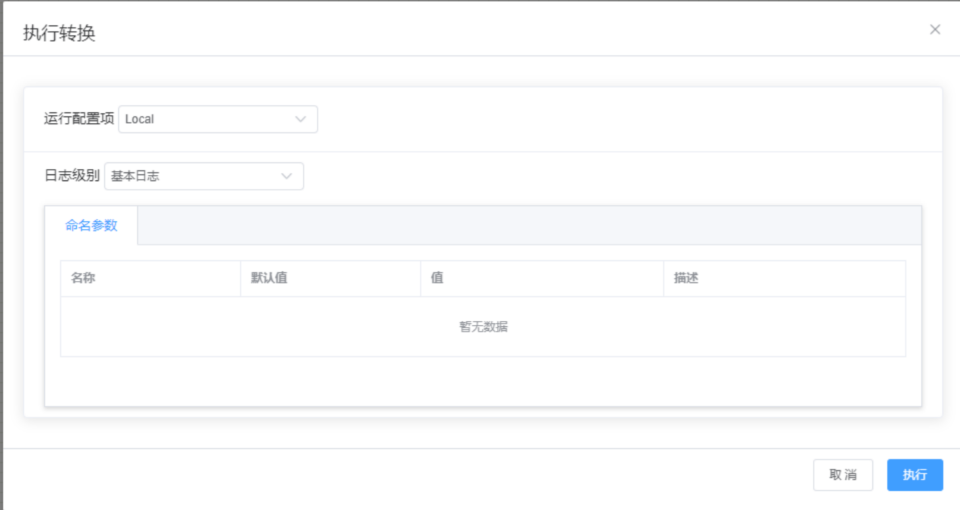
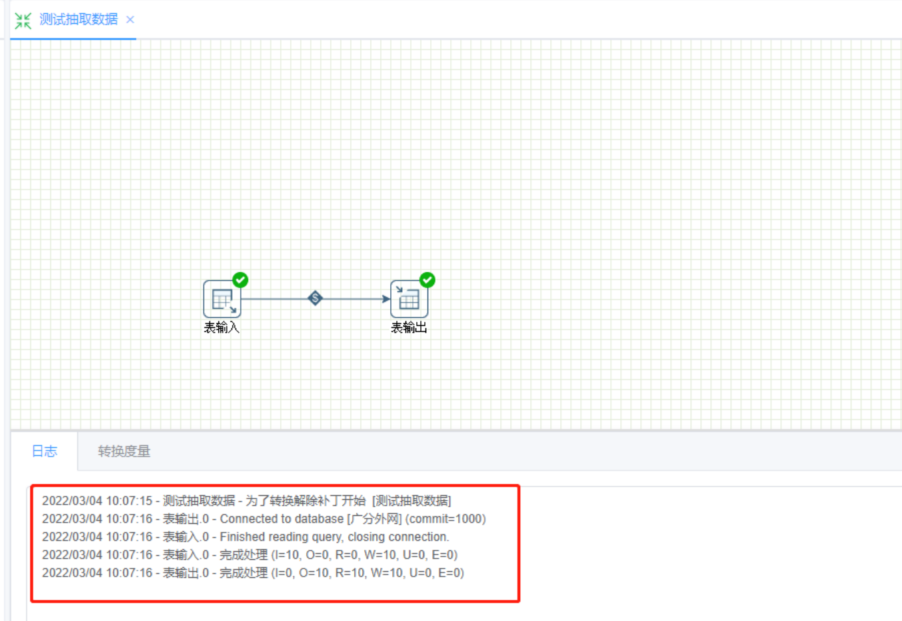
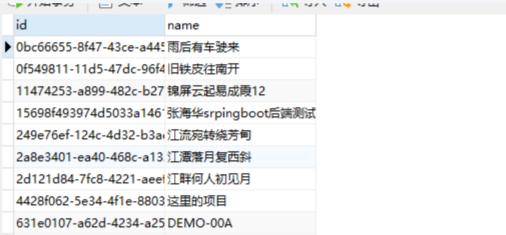
STEP7:使用转换后的表,在数据源,新增已有表,将转化后的表添加到你的数据源,即可使用该表创建数据模型(数据集)
