



178
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享大家好! 我是深圳技术大学FSR实验室的同学,在OpenHarmony成长计划啃论文俱乐部里,与华为、软通动力、润和软件、拓维信息、深开鸿等公司一起,学习和研究序列化相关技术…
@
①.【FFH】OpenHarmony啃论文成长计划---为什么JSON将逐渐取代XML?
②.【FFH】OpenHarmony啃论文成长计划---几种常见的JSON解析器比较
③.【FFH】OpenHarmony啃论文成长计划---JSON-RPC
④.【FFH】OpenHarmony啃论文成长计划---浅谈序列化规范
⑤.【FFH】OpenHarmony啃论文成长计划---Flatbuffers应用于MQTT协议
除JSON/XML之外的序列化技术的诞生历年来序列化技术的发展时间线一图概览不同序列化技术的应用场景一图比较不同序列化技术位字符串包含的信息量大小我们都知道JSON/XML拥有非常强大表达力和跨平台能力的序列化技术,使用起来非常地方便,且没什么约束。不过随着各个平台数据量的飙升,方便且自由的JSON/XML序列化技术也展现出了非常多性能方面的不足,而这些问题恰巧是不能忽视的。
JSON和XML属于文本序列化规范,都是使用字符串表示所有的数据,但是像浮点数,布尔值,结构体等一些非字符类型的数据,为了解析出这些非字符类型的数据,在序列化过程中的是会对数据类型进行描述的,最后生成的字面量表达会占用很多额外的存储空间。
在面对庞大的数据处理的时候,在这种序列化规范下,系统甚至有可能会overflow。。。
就在刚刚说的那些序列化瓶颈下,程序员们怎么会妥协于此呢,就在JSON之后,越来越多的序列化技术出现在我们视野内。比如上一期谈到的几乎没有解析时间的Flatbuffers,还有分布式计算经常用到的Microsoft Bond,Cap‘s Proto等等。
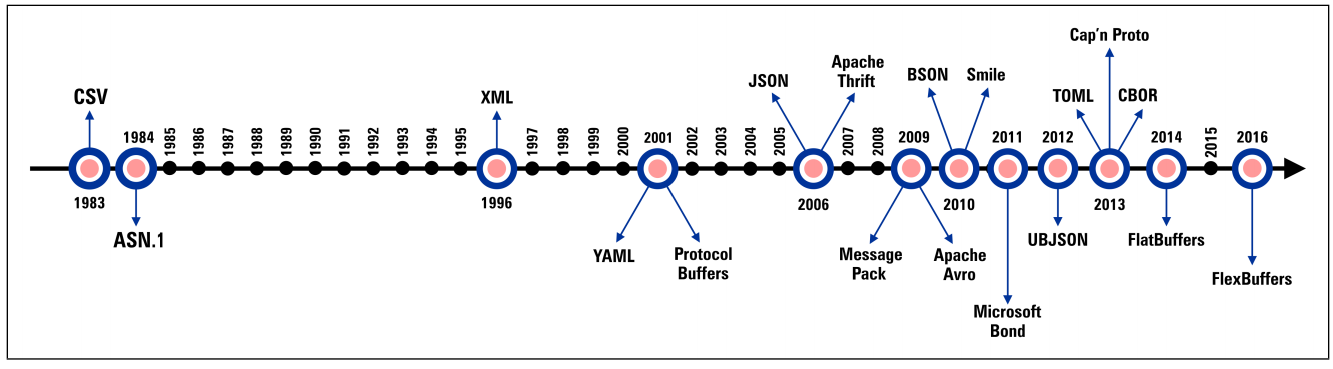
可以看到21世纪开始,因为世界在不断地网络信息化,其中对数据传输过程地要求也越来越高,序列化技术也在被人们不断迭代创新。
序列化技术也被从简单地字符分割值CSV文件,再到1996年,在SGML的基础之上,简化出一种规范,提出了一种标记型语言命名为XML(可扩展标记语言)。2006年现在依旧广受人们喜爱地JSON也出现在了我们的视野,随着技术的创新与发展,序列化技术也因为不同的场景需求,在近15年间,许多新序列化技术在不断地涌现出来。
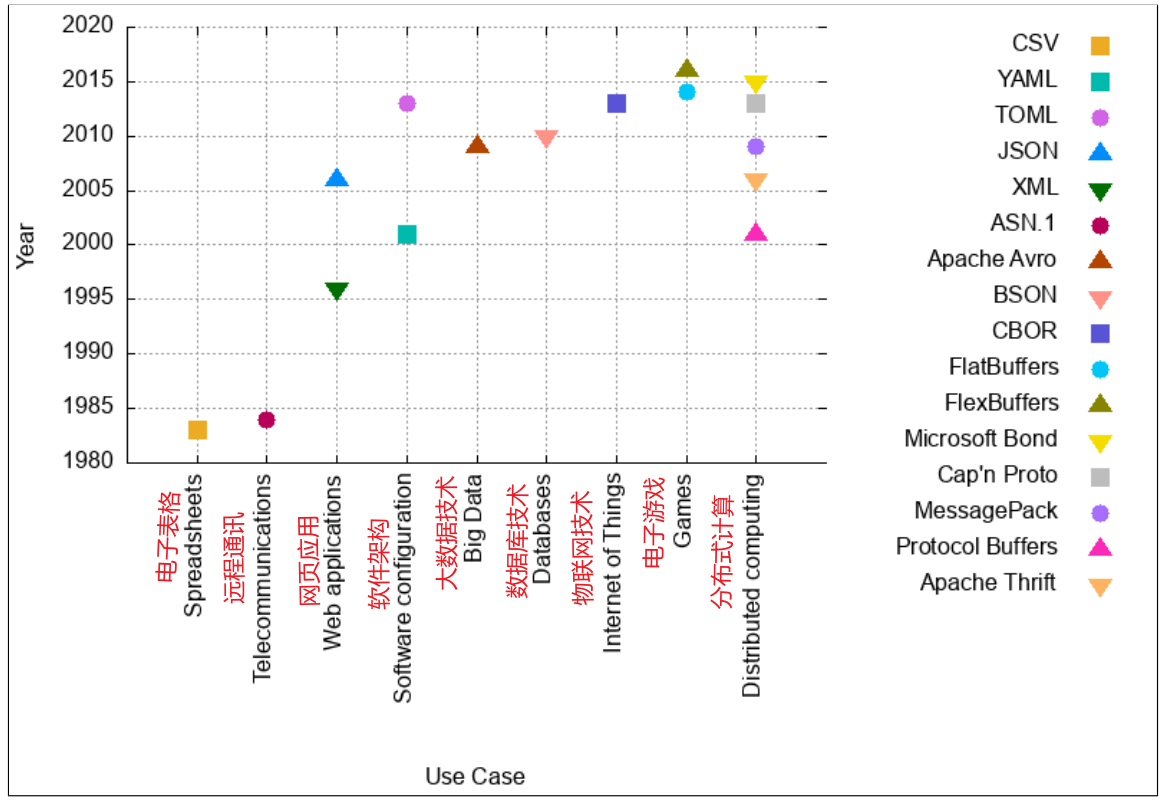
在上面这幅图我们可以直观地看到不同序列化技术地应用场景,可能这些技术还可以被应用于其他场景,但是相对于其他序列化技术,它们更多地被应用于特定地场景中。从80年代电子表格的出现,CSV被人们所熟知,再到同时期应用于远程通信的ASN.1。再紧接着的就是象征着网络时代正式开始的web应用,从1996年采用XML,再到2006年开始JSON盛行,一直沿用至今。
在软体架构中,使用着YAML还有TOML。近些年大火地大数据在使用Apache Avro;数据库技术也引入了序列化技术BSON;未来大势所趋地物联网使用着CBOR;再到我们现在的疯狂的网络游戏,应用着FlatBuffers ,后面更是基于FlatBuffers创新除了兼容性更佳的FlexBUffers。当然也离不开闹得沸沸扬扬的分布式计算,用于这个场景的序列化技术也是不断地再迭代,先后有Protocol Buffers,Apache Thrift,Message Pack,Cap'n Proto以及Microsoft Bond。
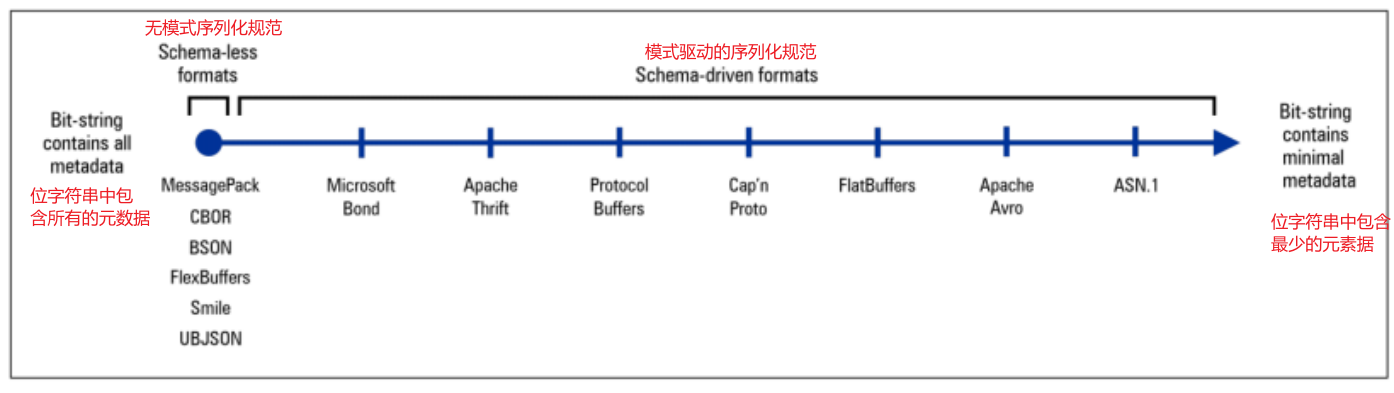
最左边的处理方法序列化后的位字符串的信息量是最大的,都是无模式序列化规范(Schema-less Serialization Specififications),比如BSON,Smile,FlexBuffers等,因为最大地保留了原始数据及其结构的信息描述。最右边的信息量是最小的,比如ASN.1,因为他们把非常多的结构信息已经在规范中提前约定,因此不需要写入序列化后的位字符串中。
A Survey of JSON-compatible Binary Serialization Specifications



