

178
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享中原工学院-大二
朱美颖
目录
对象概念:一个对象数据表明一个将被建模的真实实体
简单用对象三元组来举例,对象三元组有三个元素:身份标识OID,状态state,行为interface。即表示了一条简单的对象数据。
复杂对象举例:
(i2,{11,22,33})
(i3,[LF:i7,RF:i8])
逗号前是OID其后是它的状态,这就牵扯到了构造器的定义。
元组构造器和集合构造器。
[ ]是元组构造器的标识,{ }是集合构造器的标识
元组构造器定义了一系列属性名和其相对应的值,用属性名:值/对象标识符 结构表示。
集合构造器则是单一由对象标识符或值组成组成
这是由状态的不同所构成的多种多样的复杂对象
关系数据库和对象数据库的元组区别
学号 姓名 成绩
001 小明 98
为一个关系数据库的一个元组,通过ID标识
(001,{98,97,96,95,94})
此为对象数据库的数据,通过oid来标识,不受特定关系的约束,状态在数据内部。
类是一个种类的对象的统一定义(模板)。
例如定义一个类名叫做Cat,和一些属性例如color,age等
黄色的五岁猫是一个对象,但它使用了Cat类的属性定义,成为了一个对象。
组合对象和复杂对象相似,区别在于组合对象之间允许引用共享而复杂对象不允许。
例:复杂对象车有轮胎这个属性,但一个轮胎不能同时给两个车共享。
特化:如果类A接口是B类接口的超集,类A是类B的特化。
因为A是B的特化,即A是B的子类。
单子类划分:一个子类只有一个父类。
多子类划分:一个子类有多个父类。
类的扩展
浅外延:Animal类对象即完全符合类定义的对象是浅外延
深外延:Cat就是除了类定义的属性还有扩展
给一个符合几种类的某些定义(模板)
假设定义一个类叫Animal,有种类class,年龄age属性
Cat继承Animal后获得了属性class,age
参考论文:Query Optimisation in Distributed Object-Oriented Database
Systems
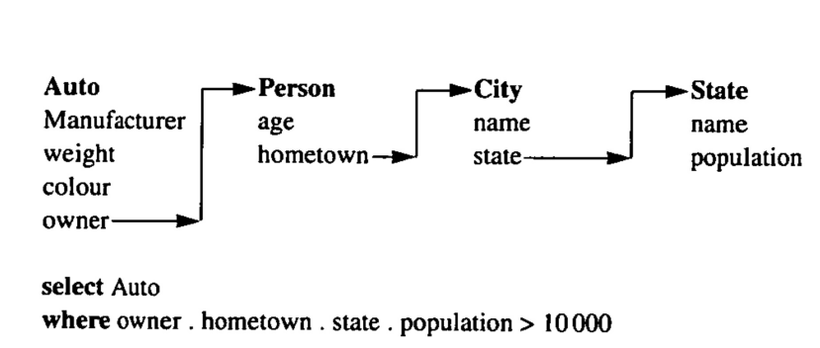

通过标识唯一的标识ID的类到下一个类通过标识ID依次寻找直到找到包含查询请求属性的类,这种查询称为链式查询,在文章中无论是查询还是遍历都是通过某种‘链的连接’来实现的。

Ci表示类,Ci,i表示只包含ID属性的简化器类
1<i<n-1中
IDi是连接Ci-1,i-1和Ci,i的标识
IDi+1是Ci,i和Ci+1,i+1连接的标识

连接’join’用⊗表示
ID在用于连接后就失效了,每个连接只能用于连接一次
Ci,j(1<i<j<n)中,Ci,j前可通过IDi向前连接,可通过IDj+1向后连接
C1,i(i<=n-1)中,C1,i可通过IDi+1向后连接,无法再向前连接,所以ID1被放弃
Ci,n(i>=2)中,Ci,i可通过IDi向前连接,无法再向后连接,所以IDn+1被放弃,而且没有IDn+1的存在
C1,n = C1⊗C2⊗…⊗Cn
设C1,k=C1⊗C2⊗…⊗Ck[IDk+l]
Ck+1,n=Ck+1⊗Ck+1⊗…⊗Cn[IDk+l]
C1,k和Ck,n连接即得到上式
为了更容易理解,在此举特例说明
仍旧看这个图,若想用正向嵌套循环遍历这四个类,Auto做第一个已知类,通过Auto中的PersonID找到唯一的Person类连接,连接后的类再根据上面方法连接下一个类,直到遍历完成。
如果已经连接的头部类,例如Auto和Person,他们是按ID排列有序的,那么对于未遍历完的中间体也是按ID排列的,整个类的遍历也是有序的。
cost和有序无序无关。
顾名思义就是上述过程的反向,即根据州来确定城市,再依次向前循环。
但会出现一种情况,即知道了StateID去找City,City会不只有一个,成本比RNL高。
RNL无论后部连接类/前部待遍历类是否按按照ID有序,因为由一对多的遍历关系并非一定会按照ID排列顺序来遍历,所以RNL整个类的遍历是不会有序的。
假设如果州的数量远远小于州前类的数量,用RNL会比FNL更好,因为一个州有很多个城市可以通过一个StateID去找到很多个城市,但如果用FNL,只能一个一个的找。
正向嵌套循环遍历(FNL)和逆向嵌套循环遍历(RNL)的简单过程
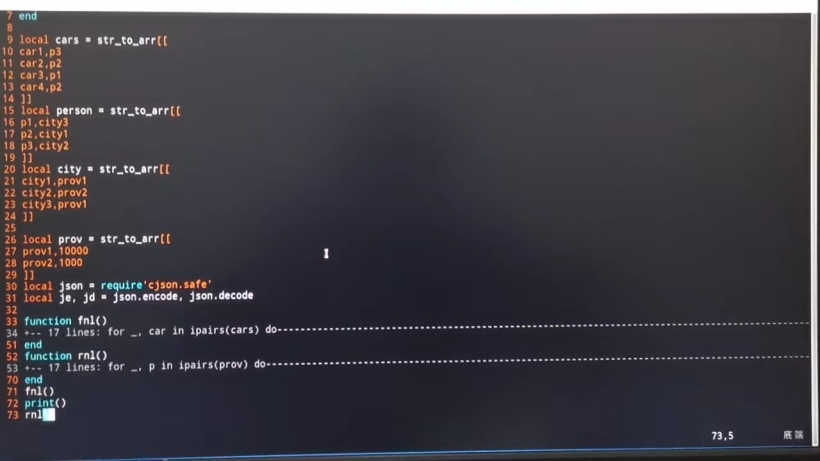
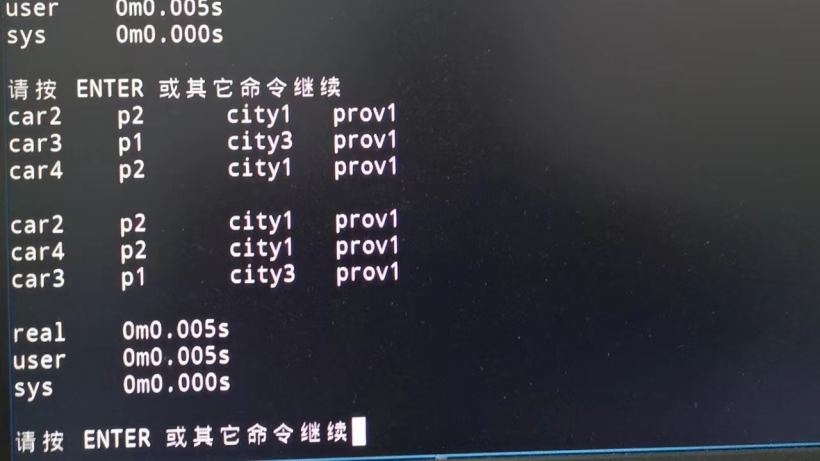
就是利用先把Ci,k分为Ci,j和Cj+1,k先分别的排序再合并到一起。
这种算法适用连接对象的大规模数据,排序之后再连接可大大提高连接的效率。
未完待续
 【采用BPSK或GMSK的Turbo码】MSK、GMSK调制二比特差分解调、turbo+BPSK、turbo+GMSK研究(Matlab代码实现)【采用BPSK或GMSK的Turbo码】MSK、GMS
【采用BPSK或GMSK的Turbo码】MSK、GMSK调制二比特差分解调、turbo+BPSK、turbo+GMSK研究(Matlab代码实现)【采用BPSK或GMSK的Turbo码】MSK、GMS


