




332
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Curve(https://github.com/opencurve/curve )是网易数帆自主设计研发的高性能、易运维、全场景支持的云原生软件定义存储系统,旨满足Ceph本身架构难以支撑的一些场景的需求,于2020年7月正式开源。当前由CurveBS和CurveFS两个子项目构成,分别提供分布式块存储和分布式文件存储两种能力。其中CurveBS已经成为开源云原生数据库PolarDB for PostgreSQL的分布式共享存储底座,支撑其存算分离架构。
![]()
在CurveBS的设计中,数据服务器ChunkServer数据一致性采用基于raft的分布式一致性协议去实现的。
典型的基于raft一致性的写Op实现如下图所示:
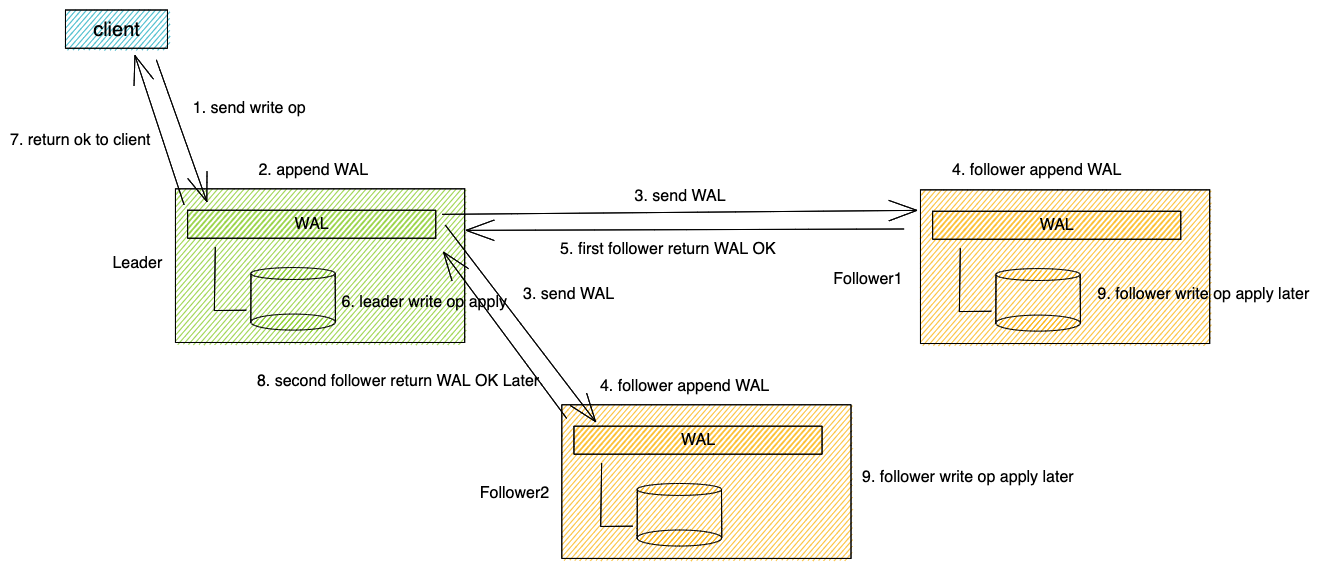
以常见的三副本为例,其大致流程如下:
在目前CurveBS的实现中,写Op是在raft apply 到本地存储引擎(datastore)时,使用了基于O_DSYNC打开的sync写的方式。实际上,在基于raft已经写了日志的情况下,写Op不需要sync就可以安全的向client端返回,从而降低写Op的时延,这就是本文所述的写时延的优化的原理。
其中的代码如下,在chunkfile的Open函数中使用了O_DSYNC的标志。
CSErrorCode CSChunkFile::Open(bool createFile) {
WriteLockGuard writeGuard(rwLock_);
string chunkFilePath = path();
// Create a new file, if the chunk file already exists, no need to create
// The existence of chunk files may be caused by two situations:
// 1. getchunk succeeded, but failed in stat or load metapage last time;
// 2. Two write requests concurrently create new chunk files
if (createFile
&& !lfs_->FileExists(chunkFilePath)
&& metaPage_.sn > 0) {
std::unique_ptr<char[]> buf(new char[pageSize_]);
memset(buf.get(), 0, pageSize_);
metaPage_.version = FORMAT_VERSION_V2;
metaPage_.encode(buf.get());
int rc = chunkFilePool_->GetFile(chunkFilePath, buf.get(), true);
// When creating files concurrently, the previous thread may have been
// created successfully, then -EEXIST will be returned here. At this
// point, you can continue to open the generated file
// But the current operation of the same chunk is serial, this problem
// will not occur
if (rc != 0 && rc != -EEXIST) {
LOG(ERROR) << "Error occured when create file."
<< " filepath = " << chunkFilePath;
return CSErrorCode::InternalError;
}
}
int rc = lfs_->Open(chunkFilePath, O_RDWR|O_NOATIME|O_DSYNC);
if (rc < 0) {
LOG(ERROR) << "Error occured when opening file."
<< " filepath = " << chunkFilePath;
return CSErrorCode::InternalError;
}
...
}
先前之所以使用O_DSYNC,是考虑到raft的快照场景下,数据如果没有落盘,一旦开始打快照,日志也被Truncate掉的场景下,可能会丢数据,目前修改Apply写不sync首先需要解决这个问题。
首先需要分析清楚Curve ChunkServer端打快照的过程,如下图所示:

打快照过程的几个关键点:
解决方案有两个:
方案二则更为复杂,既然去掉O_DSYNC写之后,我们目前不能保证last_applied_index为止的写Op都被Sync了,那么考虑将ApplyIndex拆分称为两个,即last_applied_index和last_synced_index。具体做法如下:
以下进行poc测试,测试在直接去掉O_DSYNC情况下,针对各种场景对IOPS,时延等是否有优化,每组测试至少测试两次,取其中一组。
测试所用fio测试参数如下:
[global]
rw=randwrite
direct=1
iodepth=128
ioengine=libaio
bsrange=4k-4k
runtime=300
group_reporting
size=100G
[disk01]
filename=/dev/nbd0
[global]
rw=write
direct=1
iodepth=128
ioengine=libaio
bsrange=512k-512k
runtime=300
group_reporting
size=100G
[disk01]
filename=/dev/nbd0
[global]
rw=randwrite
direct=1
iodepth=1
ioengine=libaio
bsrange=4k-4k
runtime=300
group_reporting
size=100G
[disk01]
filename=/dev/nbd0
集群配置:
| 机器 | roles | disk |
|---|---|---|
| server1 | client,mds,chunkserver | ssd/hdd * 18 |
| server2 | mds,chunkserver | ssd/hdd * 18 |
| server3 | mds,chunkserver | ssd/hdd * 18 |
| 场景 | 优化前 | 优化后 |
|---|---|---|
| 单卷4K 随机写 | IOPS=5928, BW=23.2MiB/s, lat=21587.15usec | IOPS=6253, BW=24.4MiB/s, lat=20465.94usec |
| 单卷512K顺序写 | IOPS=550, BW=275MiB/s,lat=232.30msec | IOPS=472, BW=236MiB/s,lat=271.14msec |
| 单卷4K单深度随机写 | IOPS=928, BW=3713KiB/s, lat=1074.32usec | IOPS=936, BW=3745KiB/s, lat=1065.45usec |
上述测试在RAID卡cache策略writeback下性能有略微提高,但是提升效果并不明显,512K顺序写场景下甚至略有下降,并且还发现在去掉O_DSYNC后存在IO剧烈抖动的现象。
我们怀疑由于RAID卡缓存的关系,使得性能提升不太明显,因此,我们又将RAID卡cache策略设置为writethough模式,继续进行测试:
| 场景 | 优化前 | 优化后 |
|---|---|---|
| 单卷4K随机写 | IOPS=993, BW=3974KiB/s,lat=128827.93usec | IOPS=1202, BW=4811KiB/s, lat=106426.74usec |
| 单卷单深度4K随机写 | IOPS=21, BW=85.8KiB/s,lat=46.63msec | IOPS=38, BW=154KiB/s,lat=26021.48usec |
在RAID卡cache策略writethough模式下,性能提升较为明显,单卷4K随机写大约有20%左右的提升。
SSD的测试在RAID直通模式(JBOD)下测试,性能对比如下:
| 场景 | 优化前 | 优化后 |
|---|---|---|
| 单卷4k随机写 | bw=83571KB/s, iops=20892,lat=6124.95usec | bw=178920KB/s, iops=44729,lat=2860.37usec |
| 单卷512k顺序写 | bw=140847KB/s, iops=275,lat=465.08msec | bw=193975KB/s, iops=378,lat=337.72msec |
| 单卷单深度4k随机写 | bw=3247.3KB/s, iops=811,lat=1228.62usec | bw=4308.8KB/s, iops=1077,lat=925.48usec |
可以看到在上述场景下,测试效果有较大提升,4K随机写场景下IOPS几乎提升了100%,512K顺序写也有较大提升,时延也有较大降低。
上述优化适用于Curve块存储,基于RAFT分布式一致性协议,可以减少RAFT状态机应用到本地存储引擎的一次立即落盘,从而减少Curve块存储的写时延,提高Curve块存储的写性能。在SSD场景下测试,性能有较大提升。对于HDD场景,由于通常启用了RAID卡缓存的存在,效果并不明显,因此我们提供了开关,在HDD场景可以选择不启用该优化。
本文作者:许超杰,网易数帆资深系统开发工程师

