



178
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享我们是来自各地的大学生,一起参加openharmony的啃论文计划
作者:朱美颖 中原工学院
DDBMS
目录
1.它可以解决组织位置散落较多但是相互之间有数据往来的问题。
2.当组织需要不定时扩充时,由于集中系统的容量有限,但如果使用分布式系统的话,扩充时就不会有超容的情况,而且代价相对来说较小。
3.如果数据集中在一个地方,那可靠性会变低,当这个点挂掉了之后就没有办法只能挂掉整个应用,但如果采用分布式系统则不会出现这种问题,一个点挂掉后可换为另一个点,实现快速解决故障,也可根据权重设置,在实际情况下实现负载均衡。
分布式数据库系统是物理上分散但逻辑上集中的数据库系统。
物理上的分散指的是分布式数据库的数据分散在指定网络的各个位置上,这个位置称为站点,站点拥有处理数据的能力。
逻辑上的集中指的是,站点分配的数据对于用户来说是透明的,对于用户来说,数据库系统是集中的,使用统一的数据库管理系统,通过网络对数据站点进行操作。
分布式数据库系统技术是数据库系统和计算机网络技术的结合。
分布式数据库系统将传统的每个应用只定义并且维护自己数据的形式改变成数据的集中管理,使数据拥有数据独立性。
体现如下:
数据从存储到个人设备中通过每个程序的数据描述从数据库从分别提取,改变为一个设备集合了所有程序的数据描述,根据所需从分布式数据库中提取相应的全部数据到个人设备,再分发给每个程序。
数据库系统动机之一是为了集中存取数据,而计算机网络技术则提倡的是一种对集中的工作模式。此种矛盾引出分布式数据库技术最重要的目标是集成而不是集中。
由于以上所说,我们知道用户操作分布式数据库系统是像操作集中数据库系统一样的,但是它们的物理存储是分散的,所以操作的细节实现将会不同。
关于数据操作,我们第一时间会想到查询,那就从查询操作来分析。
分布式数据库的查询处理与集中型数据库不同的是,分布式数据库不仅需要考虑CPU代价和I/O代价之外,还需要考虑站点的数据在网络中传输的代价。
分布式数据库查询的效率会影响整个分布式数据库管理系统的性能(查询优化后响应时间会变快,许多操作都是以数据查询为基础,在查询效率改变的情况下继而影响一系列的操作),如果优化得当,数据的可用性(提取数据所费代价降低,数据使用效率变高)和可扩展性包括管理系统的效率和可靠性都会提高。
由于数据的分布性,一次查询的数据可能分布于好几个站点之中,每次查询的情况可能会根据实际场景的改变进行改变,因此查询的可能性是多种多样的,开销和执行速度也不一样,优化需要考虑的方面是非常之多的,因此就更为复杂。
现已有许多经典的算法,例如: 使用连接操作对查询进行优化;利用关系代数的等价原则对查询进行优化;利用代价模型查询图和贪心思想相结合实现优化;以多表连接查询的特征为基础,对粒子进行树形编码以实现全局的优化策略。
同时在近几年也有改进的优化算法,例如:基于蚁群算法的查询优化、基于鱼群算法的查询优化、 基于并行遗传-蚁群算法的查询优化等等。
统共有四层
第一层查询分解:将全局的查询问题转化成一个统一的查询关系表达式,即从现实问题到计算机语言的转换。(例如SQL语句)
第二层数据本地化:将全局表达式分解为在相应片段上的表达式。
第三层全局优化:利用代价函数(CPU代价+I/O代价+通信代价)计算片段的代价,根据计算算出最佳的查询操作次序。若是在广域网中,通信代价是将会很大,称为取决性因素。
第四层局部优化:查询请求根据上一层分配到局部处理站点后,相当于一个集中数据库的环境,此时可以用集中性数据库的方法来进行查询优化。
参考层次结构描述为:把全局查询分为若干个子查询对应相应的局部数据库,如果查询语言不一样那就根据查询下发位置的数据库语言更改查询语言,在局部数据库进行查询操作之后返回查询所得的数据,将各个查询所得的数据进行合并得到一个全局的查询结果统一返回。
图书馆借阅管理系统
功能
(1)查询图书
(2)查询图书的借阅信息
(3)浏览图书
学生信息管理系统
功能
(1)查询学生信息
(2)查询学生借阅情况
(3)浏览学生信息
图书馆在线借阅系统
功能
(1)显示登录学生的借阅情况
(2)显示所有库存图书
(3)在线查询库存图书
(4)在线借阅
(5)在线预约
图书借阅管理数据库:student_login(Number,Name,PassWord),
books(BookID,BookName,State),
borrow(Number,BookName,BorrowData).
学生信息数据库:student(Number,Name,Details)
因为本例采用的是分布式数据库,图书借阅管理数据库和学生信息数据库不存储在一个地点,他们之间通过过网络进行连接,利用分布式系统的特点两个数据库存在着互相访问的可能性。
本例使用半联接算法可实现。
基本原理:数据在数据库网络中的传输一般都是整个关系的传输,但在这个传输过程中,并非整个关系的所有数据都是有用的。半联接算法就是传输时舍弃无用的数据/不参与联接的数据。
举例说明:
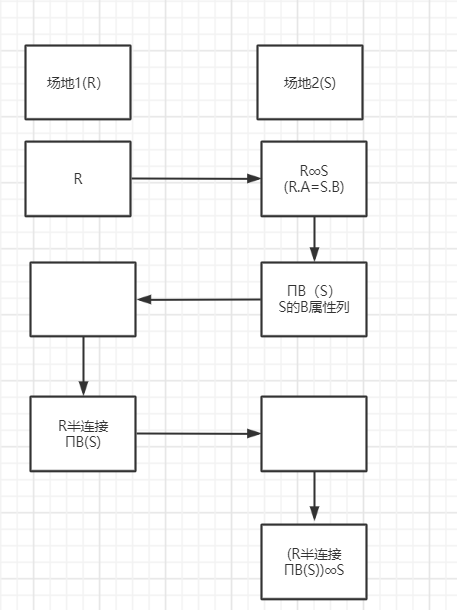
跟半连接算法不同的是,直接连接在传输的过程中不会舍弃无用的片段,因此在传输过程中数据过于繁多,传输效率会下降。
半连接在传输代价上比直接连接小,但局部处理时延比直接连接大,而图书馆管理系统显然是以传输代价为主要代价,所以图书管理系统可采用半连接算法比较合适。
陆海晶. 分布式数据库系统查询优化算法的研究[D]. 辽宁工程技术大学, 2007
王慧玉.基于分布式数据库系统查询优化的研究与应用[D].大连海事大学,2005
M. Tamer ·zsu Patrick Valduriez .分布式数据库系统原理[M]



