


31
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在Python 中文处理(1)---获取中文个数题目中(题目如下),
# -*- coding: UTF-8 -*-
import re
def getnum_of_cn(inputdata):
'''计算字符串中 中文字符 数量'''
# TODO(You): 请编写正则查询代码
return len(chi)
def test():
n = getnum_of_cn('你好,lajfldkjaklda123')
print(n)
if __name__ == '__main__':
test()
查看代码段,最终运行的是test()函数,而在test()函数中,其通过调用getnum_of_cn()函数,并将其得到的值赋值给n,最后n的值就是中文字符的个数。
在getnum_of_cn(inputdata)函数中,可以看出chi的作用就是在字符串中获取中文字符,然后通过len()函数,获得中文字符的数量
选项1
chi = re.findall(r'\u4E00-\u9FFF', inputdata)
①findall()函数的解释是:返回字符串中所有非重叠匹配的列表。如果模式中存在一个或多个捕获组,则返回组列表;如果模式有多个组,这将是元组列表。结果中包含空匹配项.通俗的讲,findall()是寻找所有能匹配到的字符,并以列表的方式返回。
②在书写正则表达式时,我们通常会使用“原始字符串”的写法(在字符串前面加上r)。所谓“原始字符串”就是字符串中每个字符都是它原始的意义,通俗的讲,就是字符串中没有转义字符。因为正则表达式中有很多元字符和需要进行转义的地方,如果不使用原始字符串就需要反斜杠\写成\,这样不仅写起来不便,读代码时也不便。
③\u4E00-\u9FFF表示汉字的正则表达式写法
因此选项1中匹配不到相关内容,最终chi为空列表,最后结果为0.
选项2
chi = re.findall(r'[\u4E00-\u9FFF]', inputdata)
其与选项1最大的区别就是加了个[],其表示匹配[]中列举的字符
chi = re.findall(r'[\u4E00-\u9FFF]', inputdata)
print(chi)
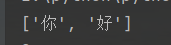
因此最终匹配成功,结果为2.
选项3
chi = inputdata.findall(r'[\u4E00-\u9FFF]')
结果报错,如下图

因为inputdata是字符串类型,其没有findall()。不过可以使用re.compile()函数,compile 函数用于编译正则表达式,生成一个 Pattern 对象
re.compile(pattern[, flag])
其中,pattern 是一个字符串形式的正则表达式,flag 是一个可选参数,表示匹配模式,比如忽略大小写,多行模式等。
因此,选项3的正确改法为
c = re.compile(r'[\u4E00-\u9FFF]')
chi = c.findall(inputdata)
选项4
chi = re.find(r'[\u4E00-\u9FFF]', inputdata)
re模块中根本没有find()函数
因此最终如下:
# -*- coding: UTF-8 -*-
import re
def getnum_of_cn(inputdata):
'''计算字符串中 中文字符 数量'''
chi = re.findall(r'[\u4E00-\u9FFF]', inputdata)
return len(chi)
def test():
n = getnum_of_cn('你好,lajfldkjaklda123')
print(n)
if __name__ == '__main__':
test()


笔记不错,给博主打赏!


