


197
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享1.程序分析,对程序中的四个函数做简要说明
# 读文件到缓冲区
def process_file(dst):
try: # 打开文件
f = open(dst, 'r') # dst为文本的目录路径
except IOError as s:
print(s)
return None
try: # 读文件到缓冲区
bvffer = f.read()
except:
print('Read File Error!')
return None
f.close()
return bvffer
# 统计词频函数
def process_buffer(bvffer):
if bvffer:
new_bvffer = re.sub(r'[^A-Za-z]', ' ', bvffer) # 使用正则表达式把除了字母和空格以外的符号都去除
words = new_bvffer.split()
word_freqs = {}
for word in words:
if word.lower() in word_freqs:
word_freqs[word.lower()] = word_freqs[word.lower()] + 1
else:
word_freqs[word.lower()] = 1
return word_freqs
# 输出结果
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
print(item)
#函数调用
def main():
dst = "C:\Users\hp\Documents\Tencent Files\2190820592\FileRecv\Gone_with_the_wind.txt
"
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
2.代码风格说明。
一个缩进级别四个空格。
(1). 连续行使用两种方式使封装元素成为一行:括号内垂直隐式连接 & 悬挂式缩进。 使用悬挂式缩进应该注意第一行不应 该 有参数,连续行要使用进一步的缩进来区分。
# 括号内隐式连接,垂直对齐
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 悬挂缩进,进一步缩进区分其他语句def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
# 悬挂缩进,一般是四个空格,但非必须
foo = long_function_name(
var_one, var_two,
var_three, var_four)
否:
# 括号内隐式连接,没有垂直对齐时,第一行的参数被禁止
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 悬挂缩进,需要进一步的缩进区分其他行def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
2.当 if 语句过长时,可选的处理方式,但不限于此:
# 不使用额外缩进if (this_is_one_thing and
that_is_another_thing):
do_something()
# 增加注释区分,支持语法高亮if (this_is_one_thing and
that_is_another_thing):
# Since both conditions are true, we can frobnicate.
do_something()
# 条件连续行额外缩进if (this_is_one_thing
and that_is_another_thing):
do_something()
3.程序运行命令、运行结果截图
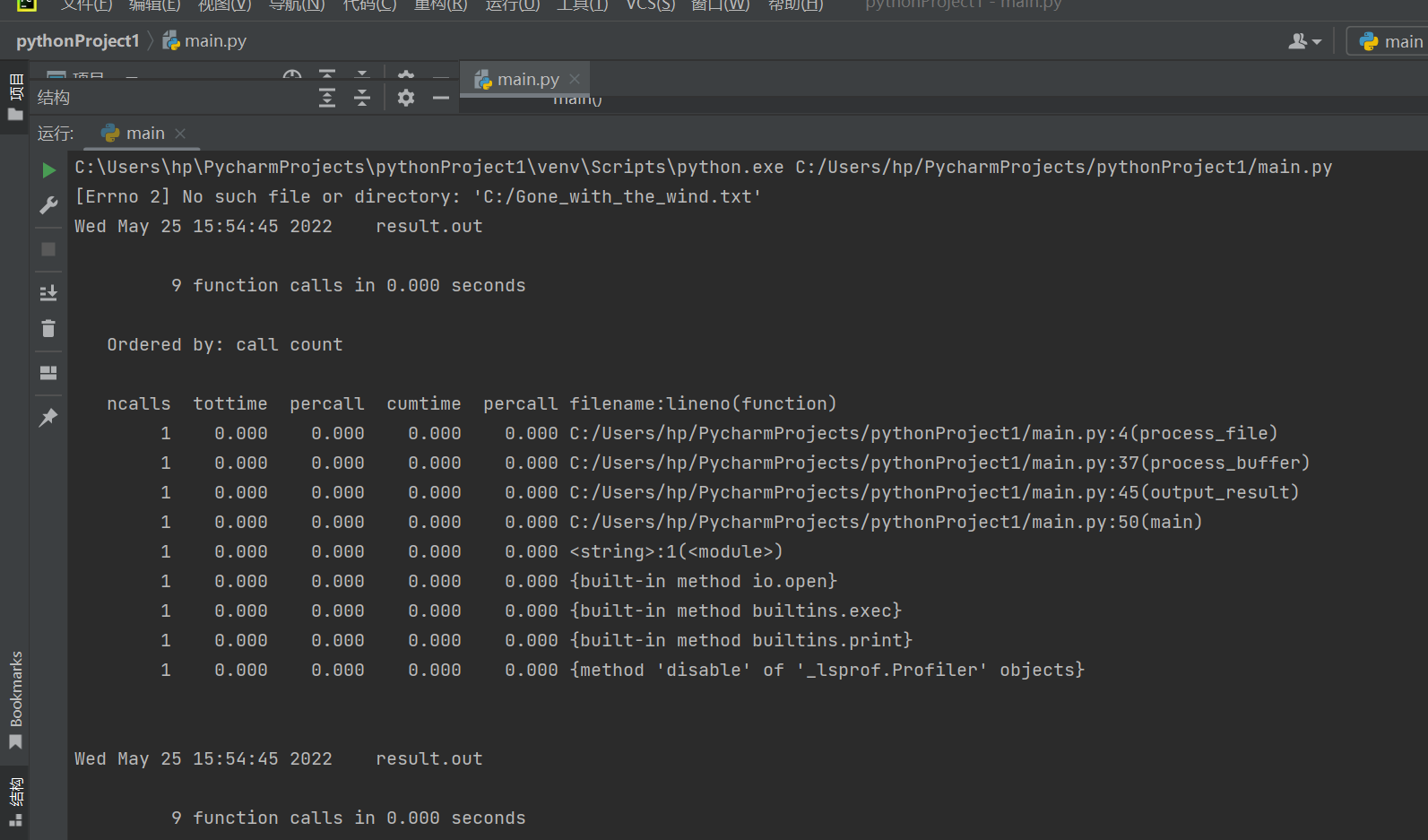
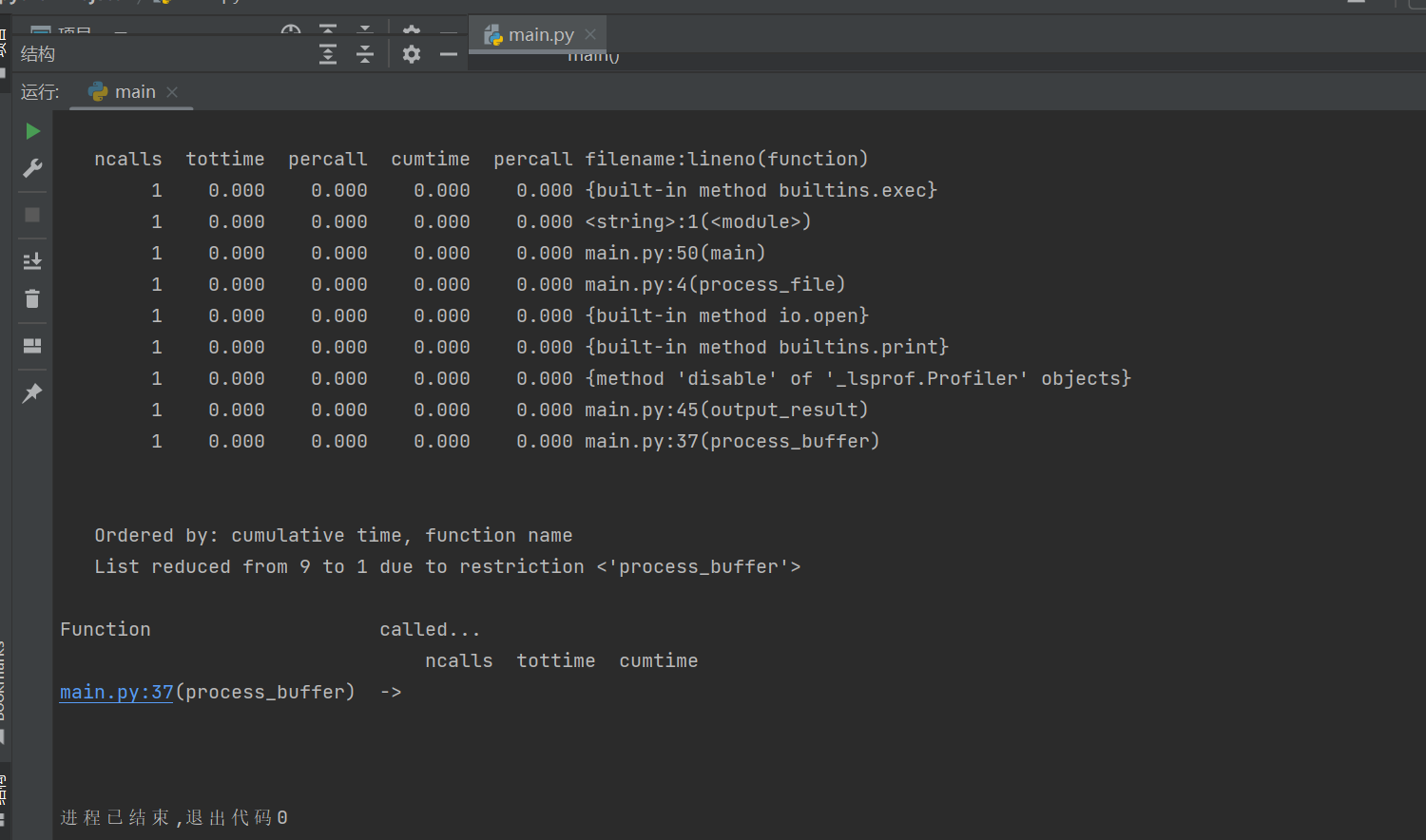
4.性能分析结果及改进
运行次数最多的代码
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
def process_buffer(bvffer):
if bvffer:
word_freq = {} # 新建一个空字典word_freq
# 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
for word in bvffer.split(): # .split()函数将bvffer切片
if word not in word_freq:
word_freq[word] = 0
word_freq[word] += 1
return word_freq
句首的大写单词被当作新单词,应该改写process_buffer,使用.lower()将句首的大写字母改为小写,同时去除文本中的中英文标点符号
def process_buffer(bvffer): # 处理缓冲区,返回存放每个单词频率的字典word_freq
if bvffer:
# 下面添加处理缓冲区bvffer代码,统计每个单词的频率,存放在字典word_freq
word_freq = {}
# 将文本内容都改为小写且去除文本中的中英文标点符号
for ch in '“‘!;,.?”':
bvffer = bvffer.lower().replace(ch, " ")
# strip()删除空白符(包括'/n', '/r','/t');split()以空格分割字符串
words = bvffer.strip().split()
for word in words:
word_freq[word] = word_freq.get(word, 0) + 1
return word_freq
通过cprofile性能评估可知,调用次数、执行时间最多的部分代码是process_buffer函数部分。


