



1,339
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享YOLACT是2019年发表在ICCV的实例分割模型,其主要通过两个并行的子网络来实现实例分割。(1)Prediction Head分支生成各个anchor的类别置信度、位置回归参数以及mask的掩码系数;(2)Protonet分支生成一组原型mask。然后将原型mask和mask的掩码系数相乘,从而得到图片中的每一个目标的mask。论文中还提出了新的NMS算法:Fast-NMS, 和朴素的NMS算法相比只有轻微的精度损失,但却大大提升了分割的速度。YOLACT是一个one-stage模型,它和two-stage模型(Mask R-CNN等)相比起来,速度更快但精度稍差一些。
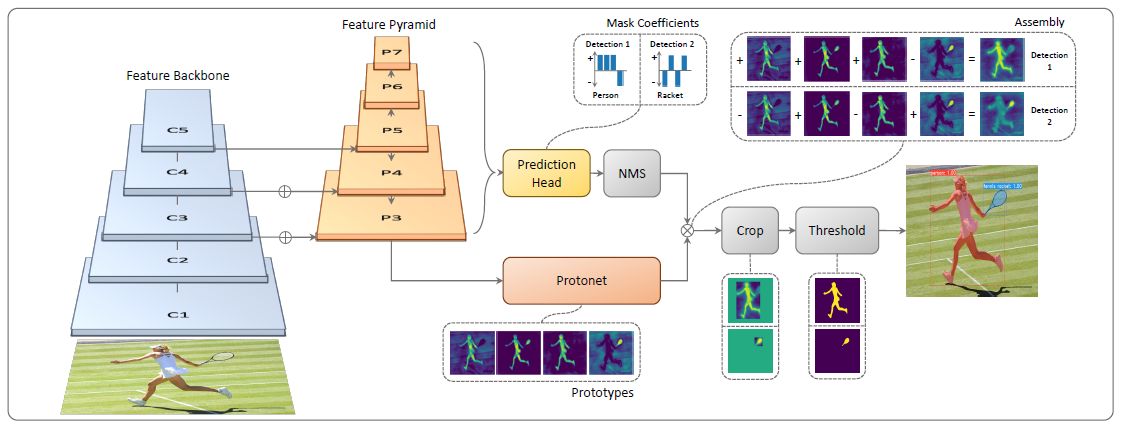
1:1,1:2,2:1。5个特征图的anchor的基本大小分别是24,48,96,192,384。基本大小根据不同比例进行调整,确保anchor的面积相等。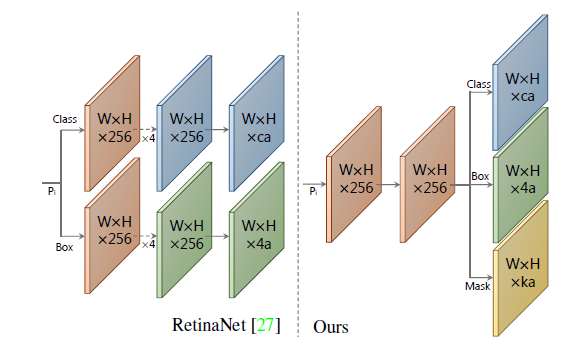
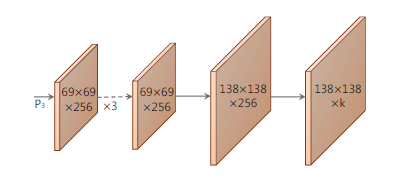
这里以P3为例进行解释说明。假设P3的维度是 $W3 \times H3 \times 256$ ,那么它的anchor个数就是 $a3=W3 \times H3 \times 3$ 。接下来Prediction Head为其生成3类输出:类别置信度,由于COCO中共81类(包括背景), 所以其维度为 $a3 \times 81$ ; 位置偏移,维度为 $a3 \times 4$ ; mask置信度,维度为 $a3 \times 32$ 。对于P4-P7进行的操作是相同的,最后将这些结果进行拼接,标记为 $a=a3+a4+a5+a6+a7$ , 得到全部的置信度维度为 $a \times 81$ ; 全部的位置偏移维度为 $a \times 4$ ; 全部的mask置信度维度为 $a \times 32$ 。
熟悉了YOLACT,下面我们将使用TensorRT API重新搭建该网络,并将网络的NMS后处理部分使用TensorRT Plugin的方式通过TensorRT API加入到TRT Engine中,实现YOLACT的端到端的推断加速。
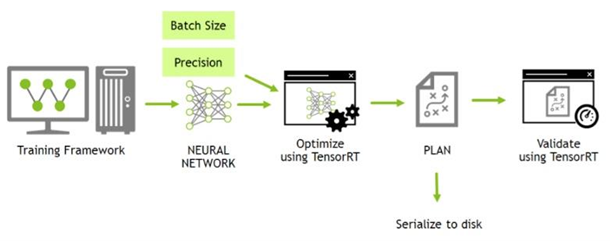
TensorRT是NVIDIA用于高效实现已训练好的深度学习模型的推理过程的SDK,其包含推理优化器和运行时环境和必要一些工具比如:trtexec, onnx-graphsurgeon,polygraphy等优化工具。其可以使深度学习模型能以更高的吞吐量和更低的延迟进行推断,并提供了完整的C++和Python的API和帮助文档。
static Logger gLogger(ILogger::Severity::kERROR); //1.log
IBuilder * builder = createInferBuilder(gLogger); //2.builder and config
INetworkDefinition * network = builder->createNetworkV2(1U << int(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
IOptimizationProfile *profile = builder->createOptimizationProfile();
IBuilderConfig * config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(1 << 30);
// dynamic shape
ITensor *inputTensor = network->addInput("inputT0", DataType::kFLOAT, Dims3 {-1, -1, -1});
profile->setDimensions(inputTensor->getName(), OptProfileSelector::kMIN, Dims3 {1, 1, 1});
profile->setDimensions(inputTensor->getName(), OptProfileSelector::kOPT, Dims3 {3, 4, 5});
profile->setDimensions(inputTensor->getName(), OptProfileSelector::kMAX, Dims3 {6, 8, 10});
config->addOptimizationProfile(profile);
//3.network
IIdentityLayer *identityLayer = network->addIdentity(*inputTensor);
network->markOutput(*identityLayer->getOutput(0));
//4.build engine
IHostMemory *engineString = builder->buildSerializedNetwork(*network, *config);
//5.save engine
std::ofstream engineFile(trtFile, std::ios::binary);
engineFile.write(static_cast<char *>(engineString->data()), engineString->size());
//1.创建 engine和 context
IRuntime *runtime {createInferRuntime(gLogger)};
engine = runtime->deserializeCudaEngine(engineString->data(), engineString->size());
IExecutionContext *context = engine->createExecutionContext();
context->setBindingDimensions(0, Dims3 {3, 4, 5});
//2.准备数据
// 涉及数据host to device的copy
int inputSize = 3 * 4 * 5, outputSize = 1;
Dims outputShape = context->getBindingDimensions(1);
for (int i = 0; i < outputShape.nbDims; i++)
{
outputSize *= outputShape.d[i];
}
std::vector<float> inputH0(inputSize, 1.0f), outputH0(outputSize, 0.0f);
std::vector<void *> bufferD = {nullptr, nullptr};
cudaMalloc(&bufferD[0], sizeof(float) * inputSize);
cudaMalloc(&bufferD[1], sizeof(float) * outputSize);
for (int i = 0; i < inputSize; i++)
{
inputH0[i] = (float)i;
}
cudaMemcpy(bufferD[0], inputH0.data(), sizeof(float) * inputSize, cudaMemcpyHostToDevice);
//3.执行推理(Execute),支持同步和异步
context->executeV2(bufferD.data());
//4.推理结果device to host的copy
cudaMemcpy(outputH0.data(), bufferD[1], sizeof(float) * outputSize, cudaMemcpyDeviceToHost);
print(inputH0, context->getBindingDimensions(0), std::string(engine->getBindingName(0)));
print(outputH0, context->getBindingDimensions(1), std::string(engine->getBindingName(1)));
//5.释放显存
cudaFree(bufferD[0]);
cudaFree(bufferD[1]);
可以通过以下几种方式使用TensorRT
onnx-graphsurgeon可以方便高效的对ONNX进行修改等操作,是推荐的方式。
TensorRT API提供了相对完整的训练框架中出现的算子的实现,比如常用的卷积,池化,激活,切片,拼接,循环和Plugin调用的API等, 比较好的一点是TensorRT提供了比较全面和详细的API说明文档,并且近期NVIDIA的团队也开源了针对于中文的cookbook。关于详细的API支持的Layer和OP可以参考API说明文档, 这里仅列出YOLACT使用到的部分Layer的API
下面我们将用到上表中描述的Layer API构建YOLACT并实现TensorRT的加速。
我们将从构建阶段和运行阶段两个部分说明如何通过TensorRT API搭建YOLACT并实现推理加速,因部分代码过长,整个项目的完整代码已经寄放在Github:https://github.com/DataXujing/yolact_tensorrt_api ,可以在Github获取完整项目代码。
import os
import numpy as np
import tensorrt as trt
import pycuda.autoinit
import pycuda.driver as cuda
params = np.load("./yolact_weights.npz")
logger = trt.Logger(trt.Logger.VERBOSE)
trt.init_libnvinfer_plugins(logger, '')
PLUGIN_CREATORS = trt.get_plugin_registry().plugin_creator_list
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
builder = trt.Builder(logger)
network = builder.create_network(EXPLICIT_BATCH)
config = builder.create_builder_config()
config.max_workspace_size = 1 << 30
yolact_trt_api,并使用上表中的TensorRT API进行逐层搭建,因代码过长,完整代码可以在Github:https://github.com/DataXujing/yolact_tensorrt_api获得。def yolact_trt_api(network,config):
#0.input: yolact_input 1x3x550x550 output: yolact_input
yolact_input = network.add_input("yolact_input",trt.DataType.FLOAT,(1,3,550,550))
origin_image_w = network.add_input("origin_image_w",trt.DataType.FLOAT,(1,1,1))
origin_image_h = network.add_input("origin_image_h",trt.DataType.FLOAT,(1,1,1))
#1.Conv_0: w: 661 [64,3,7,7]
# b: 662 [64] input: yolact_input, output: 660
conv_0 = network.add_convolution(input=yolact_input,num_output_maps=64,kernel_shape=(7, 7), kernel=params["661"],bias=params["662"])
conv_0.stride = (2,2)
conv_0.padding = (3,3)
conv_0.dilation = (1,1)
conv_0.num_groups= 1
#2.Relu_1: input: 660, output: 357
relu_1 = network.add_activation(input=conv_0.get_output(0), type=trt.ActivationType.RELU)
#3.MaxPool_2: input:357,output:358
maxpool_2 = network.add_pooling(input=relu_1.get_output(0), type=trt.PoolingType.MAX, window_size=(3, 3))
maxpool_2.stride = (2,2)
maxpool_2.padding = (1,1)
#=========== 此处省略N行代码=================
# ***添加plugin***
# 这里我们用了一个NMS的Plugin,该Plugin是我们基于TensorRT的BatchedNMS Plugin做的修改,我们称为MdcBatchedNMS Plugin
# 因Plugin的介绍不是本博文的重点,相关Plugin可以通过Github联系小编
mdcbatchednms_trt = network.add_plugin_v2(inputs=[reshape_box.get_output(0),softmax_244.get_output(0)], plugin=get_trt_plugin("MdcBatchedNMS_TRT"))
mdcbatchednms_trt.get_output(0).name = "num_detections"
network.mark_output(mdcbatchednms_trt.get_output(0))
mdcbatchednms_trt.get_output(1).name = "nmsed_boxes"
network.mark_output(mdcbatchednms_trt.get_output(1))
mdcbatchednms_trt.get_output(2).name = "nmsed_scores"
network.mark_output(mdcbatchednms_trt.get_output(2))
mdcbatchednms_trt.get_output(3).name = "nmsed_classes"
network.mark_output(mdcbatchednms_trt.get_output(3))
mdcbatchednms_trt.get_output(4).name = "nmsed_indices"
network.mark_output(mdcbatchednms_trt.get_output(4))
return network, config
# MdcBatchedNMS_TRT plugin层的构建
def get_trt_plugin(plugin_name):
plugin = None
for plugin_creator in PLUGIN_CREATORS:
if plugin_creator.name == plugin_name:
shareLocation = trt.PluginField("shareLocation", np.array([1],dtype=np.int64), trt.PluginFieldType.INT32)
backgroundLabelId = trt.PluginField("backgroundLabelId", np.array([0],dtype=np.int64), trt.PluginFieldType.INT32)
numClasses = trt.PluginField("numClasses", np.array([3],dtype=np.int64), trt.PluginFieldType.INT32)
topK = trt.PluginField("topK", np.array([1000],dtype=np.int64), trt.PluginFieldType.INT32)
keepTopK = trt.PluginField("keepTopK", np.array([20],dtype=np.int64), trt.PluginFieldType.INT32)
scoreThreshold = trt.PluginField("scoreThreshold", np.array([0.95],dtype=np.float32), trt.PluginFieldType.FLOAT32)
iouThreshold = trt.PluginField("iouThreshold", np.array([0.30],dtype=np.float32), trt.PluginFieldType.FLOAT32)
isNormalized = trt.PluginField("isNormalized", np.array([0],dtype=np.int64), trt.PluginFieldType.INT32)
clipBoxes = trt.PluginField("clipBoxes", np.array([0],dtype=np.int64), trt.PluginFieldType.INT32)
scoreBits = trt.PluginField("scoreBits", np.array([16],dtype=np.int64), trt.PluginFieldType.INT32)
plugin_version = trt.PluginField("plugin_version", np.array(["1"],dtype=np.string_), trt.PluginFieldType.CHAR)
field_collection = trt.PluginFieldCollection([shareLocation,backgroundLabelId,numClasses,topK,keepTopK,scoreThreshold,iouThreshold,
isNormalized,clipBoxes,scoreBits,plugin_version])
plugin = plugin_creator.create_plugin(name=plugin_name, field_collection=field_collection)
return plugin
network,config = yolact_trt_api(network,config)
plan = builder.build_serialized_network(network, config)
# engine = runtime.deserialize_cuda_engine(plan)
#save engine
with open("yolact_api.engine", "wb") as f:
f.write(plan)
#load engine
if os.path.exists("yolact_api.engine"):
# If a serialized engine exists, load it instead of building a new one.
print("Reading engine from file {}".format("yolact_api.engine"))
with open("yolact_api.engine", "rb") as f, trt.Runtime(logger) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
stream = cuda.Stream()
input_data = np.arange(1*3*550*550,dtype=np.float32).reshape(1,3,550,550)
input_data_w = np.array([1920],dtype=np.float32).reshape(1,1,1)
input_data_h = np.array([1080],dtype=np.float32).reshape(1,1,1)
inputH0 = np.ascontiguousarray(input_data.reshape(-1))
inputD0 = cuda.mem_alloc(inputH0.nbytes)
inputH1 = np.ascontiguousarray(input_data_w.reshape(-1))
inputD1 = cuda.mem_alloc(inputH1.nbytes)
inputH2 = np.ascontiguousarray(input_data_h.reshape(-1))
inputD2 = cuda.mem_alloc(inputH2.nbytes)
# 内存到显存的数据copy
cuda.memcpy_htod_async(inputD0,inputH0,stream)
cuda.memcpy_htod_async(inputD1,inputH1,stream)
cuda.memcpy_htod_async(inputD2,inputH2,stream)
context.execute_async_v2([int(inputD0),int(inputD1),int(inputD2),int(outputD0),int(outputD1),int(outputD2),int(outputD3),int(outputD4),int(outputD5),int(outputD6)],stream.handle)
cuda.memcpy_dtoh_async(outputH0,outputD0,stream)
cuda.memcpy_dtoh_async(outputH1,outputD1,stream)
cuda.memcpy_dtoh_async(outputH2,outputD2,stream)
cuda.memcpy_dtoh_async(outputH3,outputD3,stream)
cuda.memcpy_dtoh_async(outputH4,outputD4,stream)
cuda.memcpy_dtoh_async(outputH4,outputD5,stream)
cuda.memcpy_dtoh_async(outputH4,outputD6,stream)
stream.synchronize()
按照上述过程即可完整的基于TensorRT构建YOLACT并进行加速推断,其过程可以迁移到其他网络的搭建和构建,过程是一致的。
通过TensorRT API的方式我们主要实现了如下内容:

[1]. https://arxiv.org/pdf/1904.02689.pdf
[2]. https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html
[3]. https://docs.nvidia.com/deeplearning/tensorrt/api/c_api
[4]. https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/
[5]. https://developer.nvidia.com/nvidia-tensorrt-download
[6]. https://github.com/NVIDIA/trt-samples-for-hackathon-cn/tree/master/cookbook
[7]. https://github.com/dbolya/yolact/
[8]. https://blog.csdn.net/wh8514/article/details/105520870
[9]. https://github.com/DataXujing/yolact_tensorrt_api



很不错的内容,干货满满,已支持师傅,期望师傅能输出更多干货,并强烈给师傅五星好评
另外,如果可以的话,期待师傅能给正在参加年度博客之星评选的我一个五星好评,您的五星好评都是对我的支持与鼓励(帖子中有大额红包惊喜哟,不要忘记评了五星后领红包哟)
⭐ ⭐ ⭐ ⭐ ⭐ 博主信息⭐ ⭐ ⭐ ⭐ ⭐
博主:橙留香Park
本人原力等级:5
链接直达:https://bbs.csdn.net/topics/611387568
微信直达:Blue_Team_Park
⭐ ⭐ ⭐ ⭐ ⭐ 五星必回!!!⭐ ⭐ ⭐ ⭐ ⭐
点赞五星好评回馈小福利:抽奖赠书 | 总价值200元,书由君自行挑选(从此页面参与抽奖的同学,只需五星好评后,参与抽奖)



