




1,409
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
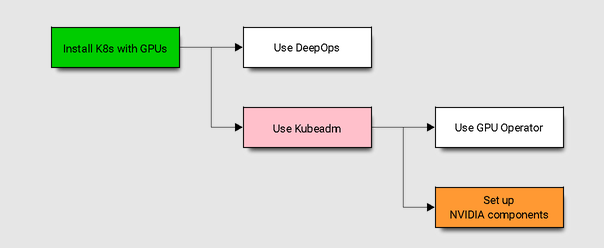
Kubernetes (K8s) 是一个开源系统,用于自动化容器化应用程序的部署、扩展和管理。Kubernetes 包括对 GPU 的支持和对 Kubernetes 的增强,因此用户可以轻松配置和使用 GPU 资源来加速 AI 和 HPC 工作负载。
DeepOps——GPU 基础设施和自动化工具。 使用 DeepOps 自动部署,特别是对于包含许多工作节点的群集。DeepOps是一个模块化的可测试脚本集合,可以自动部署Kubernetes,Slurm或两者的混合组合。它还安装了必要的GPU驱动程序,NVIDIA Container Toolkit for Docker()以及用于GPU加速工作的各种其他依赖项。封装了 NVIDIA GPU 的最佳实践,它可以根据需要进行自定义或作为单个组件运行。
DeepOps项目封装了部署GPU服务器集群和共享单个强大节点(如NVIDIA DGX Systems)的最佳实践。DeepOps还可以以模块化方式进行调整或使用,以满足特定于站点的集群需求。例如:
- NVIDIA DGX 服务器的本地数据中心,DeepOps 提供端到端功能来设置整个集群管理堆栈
- 运行 Kubernetes 的现有集群,其中 DeepOps 脚本用于部署 Kubeflow 和连接 NFS 存储
- 需要资源管理器/批处理调度程序的现有集群,其中DeepOps用于安装Slurm或Kubernetes
- 不需要调度程序的单台计算机,只需要 NVIDIA 驱动程序、Docker 和 NVIDIA 容器运行时.
有很多方法可以使用 NVIDIA 支持的组件(如驱动程序、插件和运行时)安装 Kubernetes。本文采用DeepOps 安装 Kubernetes。
DeepOps目前支持以下Linux发行版:
- NVAIDA DGX OS 4, 5
- Ubuntu 18.04 LTS, 20.04 LTS
- CentOS 7,8
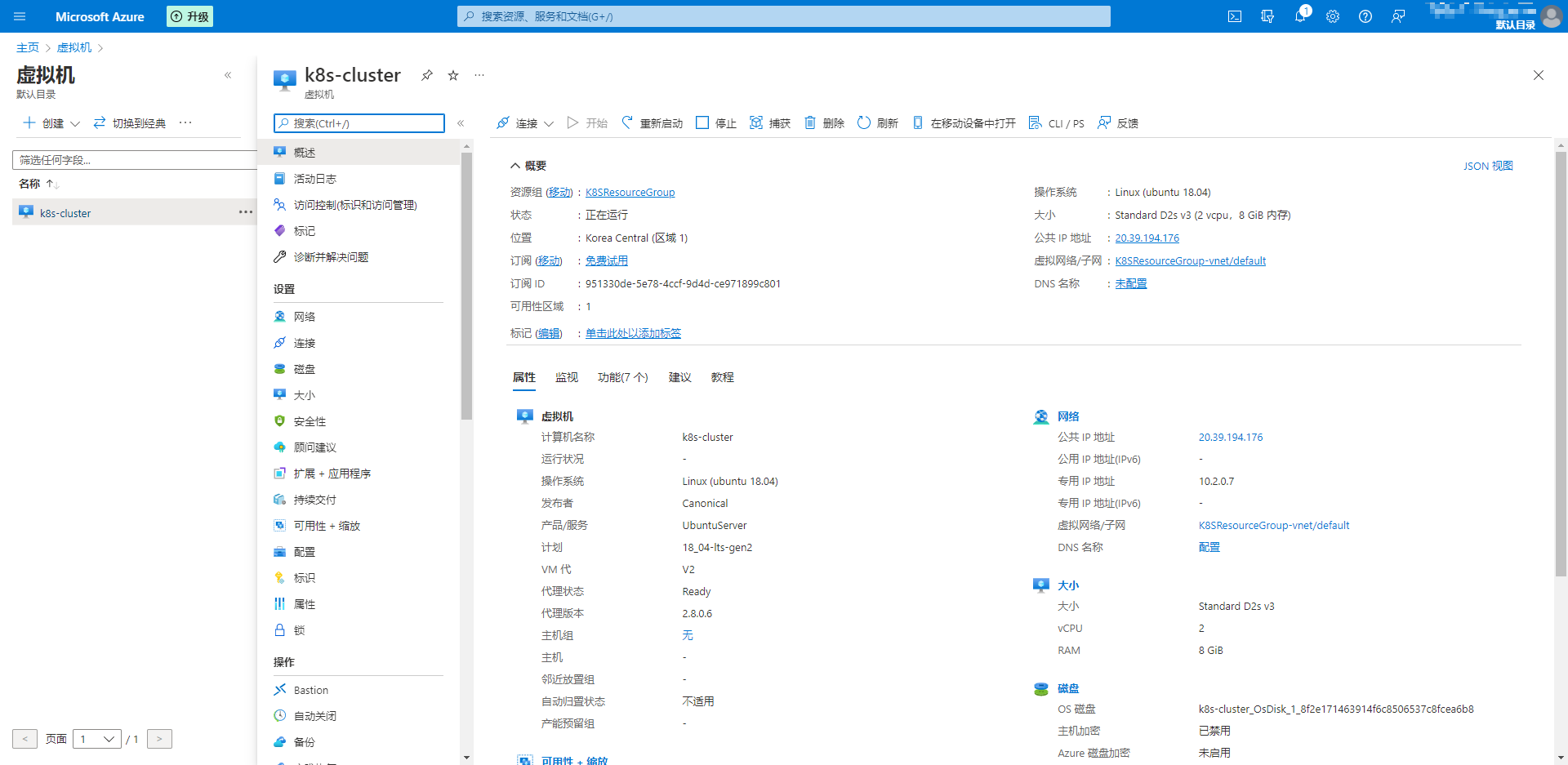
# 虚拟机型号:
# 操作系统:Linux (Ubuntu 20.04.4)
# 大小:Standard D2s v3 (2 vcpu,8 GiB 内存)
# 克隆 DeepOps 存储库
git clone https://github.com/NVIDIA/deepops.git
# 进入deepops目录
cd deepops
# 安装必备软件并复制默认配置
./scripts/setup.sh
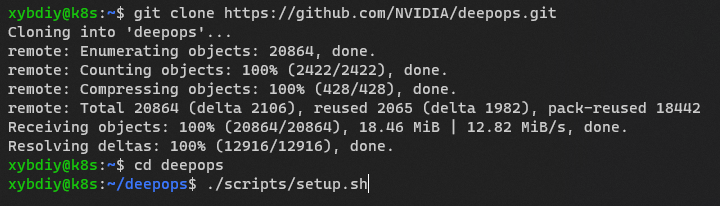
如图所示,安装配置完成。
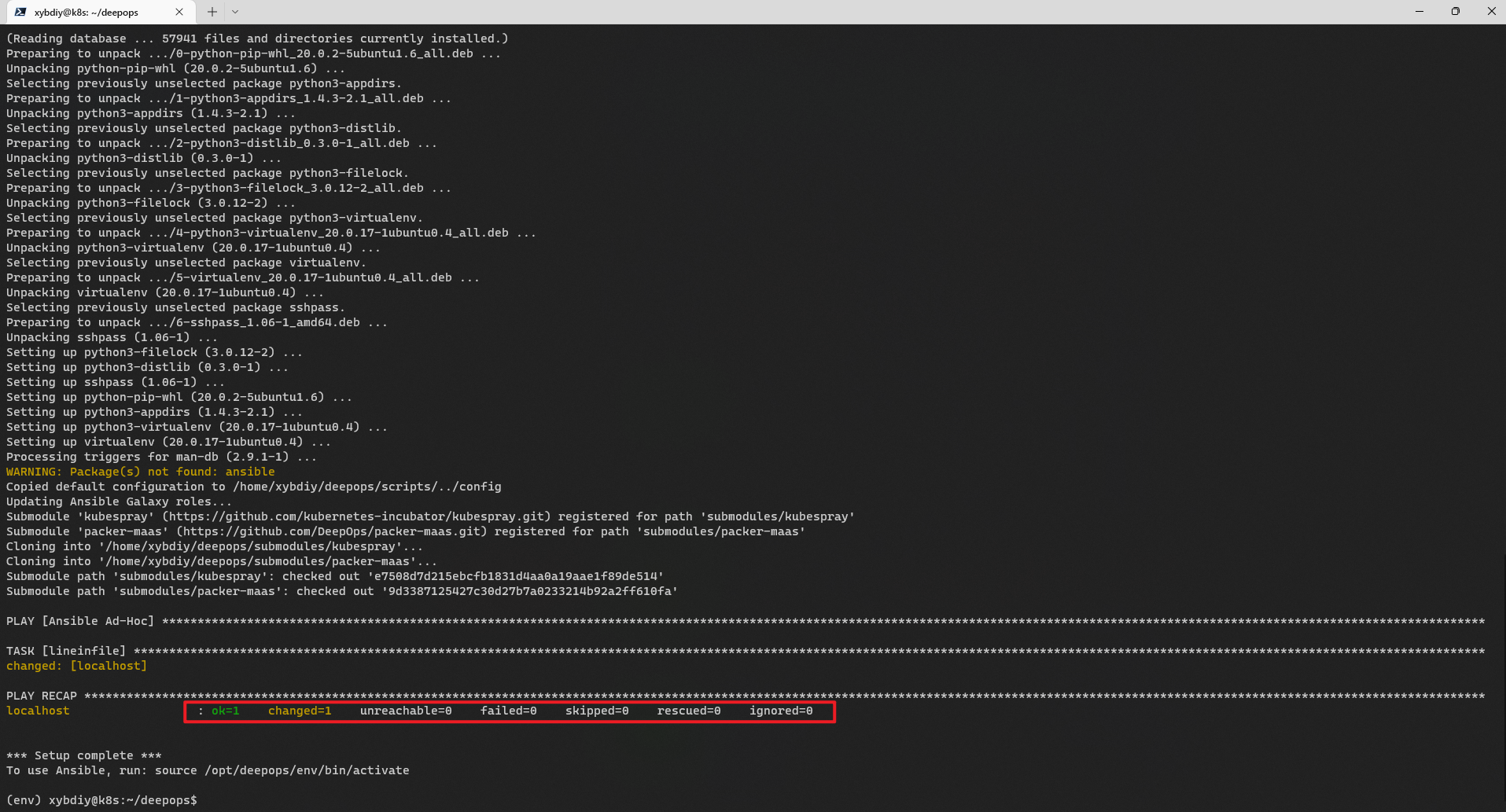
# 编辑配置信息,设置集群中的主机名称,如下图所示。
vi config/inventory
# 验证配置信息是否正确
ansible all -m raw -a "hostname"
# 使用 Ansible 安装 Kubernetes
ansible-playbook -l k8s-cluster -k -u xybdiy -K playbooks/k8s-cluster.yml
# 配置访问权限
cp config/artifacts/admin.conf ~/.kube/config
export KUBECONFIG=~/.kube/config
# 验证 Kubernetes 集群是否正在运行
kubectl get nodes
编辑 config/inventory 配置文件
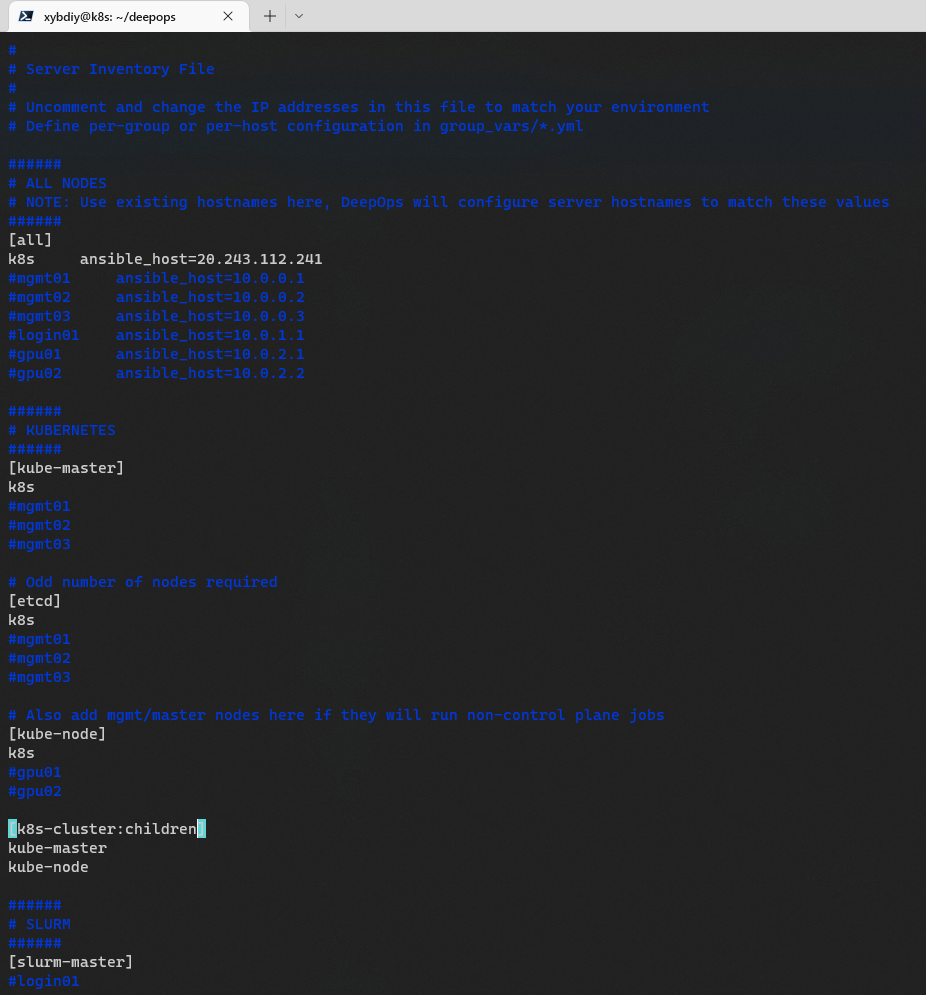
验证上述配置信息是否正确💚,如图所示。
(env) xybdiy@k8s:~/deepops$ ansible all -m raw -a "hostname"
PLAY [Ansible Ad-Hoc] *******************************************************************************************************************************************************************************************
TASK [raw] ******************************************************************************************************************************************************************************************************
changed: [k8s]
PLAY RECAP ******************************************************************************************************************************************************************************************************
k8s : ok=1 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0

K8S集群使用DeepOps安装部署完成。
使用DeepOps安装K8S集群,结果如图所示。
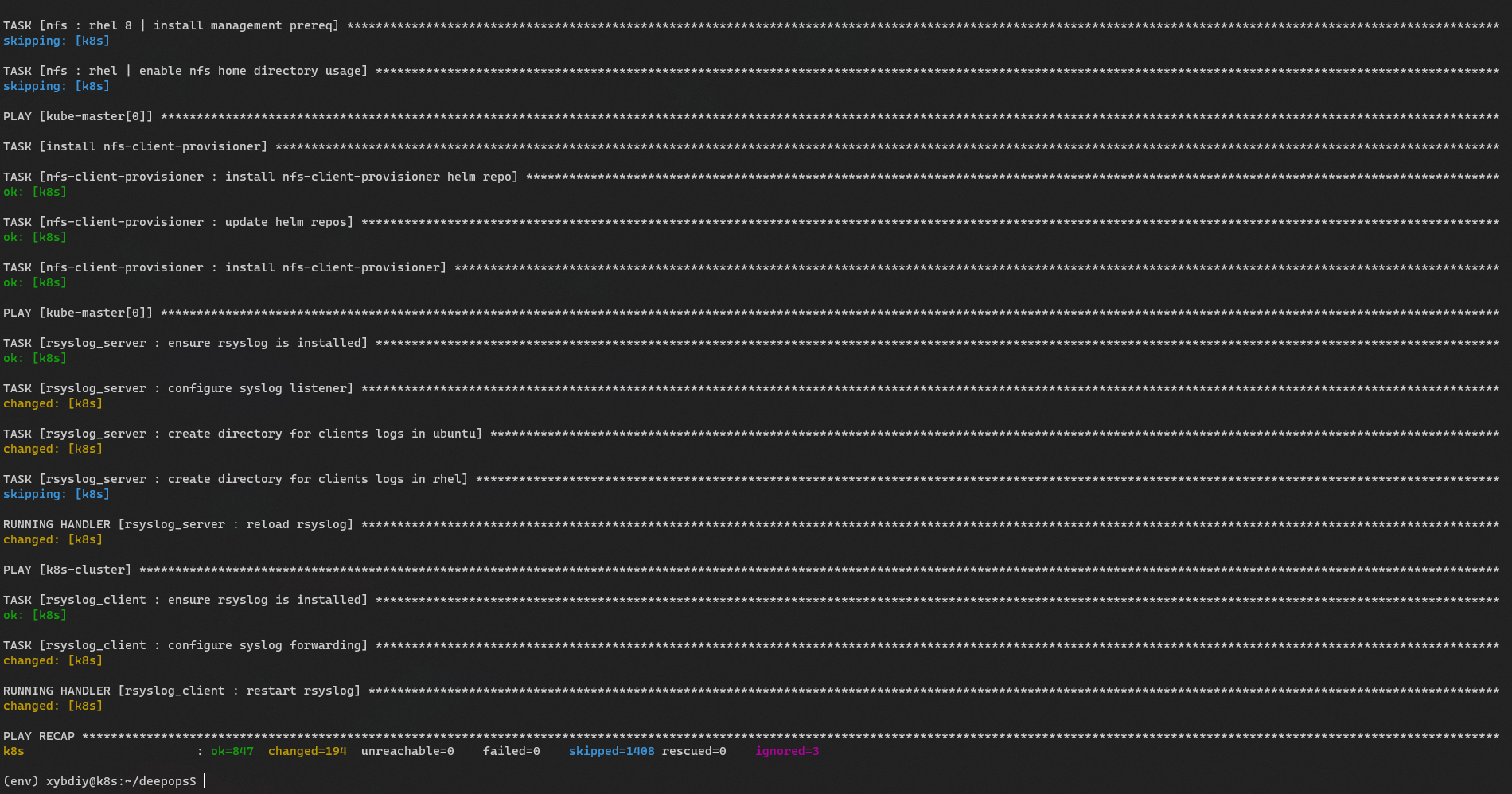

# 查看K8S部署的节点信息状态
(env) xybdiy@k8s:~/deepops$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s Ready control-plane,master 24m v1.22.8
NVIDIA device plugin 通过k8s daemonset的方式部署到每个k8s的node节点上,实现了Kubernetes device plugin的接口。
提供以下功能:
开始安装 nvidia-device-plugin插件,安装此插件是为了在k8s中使用GPU
执行命令
# 这是一个简单的静态守护程序集,旨在演示的基本功能。
# 在 Kubernetes 中启用 GPU 支持,执行以下命令
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.12.0/nvidia-device-plugin.yml
# 查看容器
kubectl get pods -A
# 通过检查kube-system命名空间中的pod来验证是否已安装此插件
kubectl get pods -n kube-system | grep -i nvidia
# 查看节点详细信息
kubectl describe node
# 运行 GPU 作业。部署守护程序集后,容器现在可以使用以下资源类型请求 NVIDIA GPU:nvidia.com/gpu
$ cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
EOF
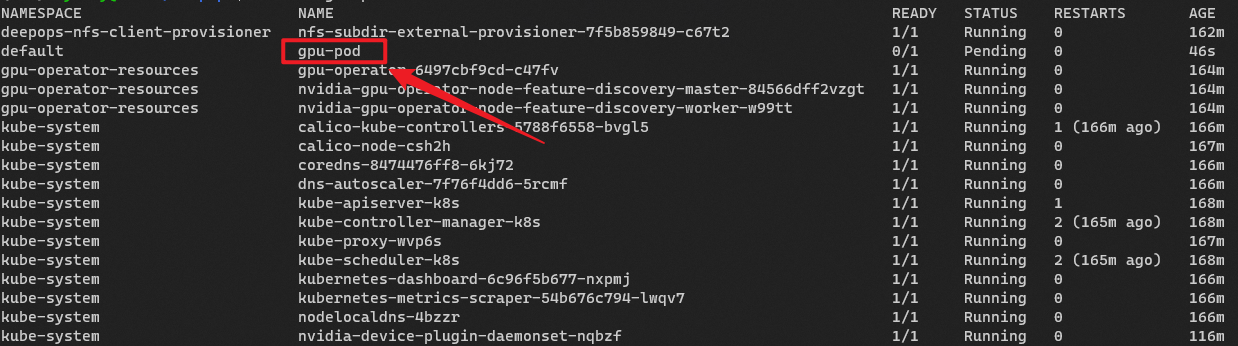
# 查看容器
kubectl get pods -A
执行命令结果
(env) xybdiy@k8s:~/deepops$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.6.0/nvidia-device-plugin.yml
daemonset.apps/nvidia-device-plugin-daemonset created
(env) xybdiy@k8s:~/deepops$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
deepops-nfs-client-provisioner nfs-subdir-external-provisioner-7f5b859849-c67t2 1/1 Running 0 135m
default gpu-demo-vectoradd 0/1 Pending 0 21m
gpu-operator-resources gpu-operator-6497cbf9cd-c47fv 1/1 Running 0 137m
gpu-operator-resources nvidia-gpu-operator-node-feature-discovery-master-84566dff2vzgt 1/1 Running 0 137m
gpu-operator-resources nvidia-gpu-operator-node-feature-discovery-worker-w99tt 1/1 Running 0 137m
kube-system calico-kube-controllers-5788f6558-bvgl5 1/1 Running 1 (139m ago) 139m
kube-system calico-node-csh2h 1/1 Running 0 140m
kube-system coredns-8474476ff8-6kj72 1/1 Running 0 139m
kube-system dns-autoscaler-7f76f4dd6-5rcmf 1/1 Running 0 139m
kube-system kube-apiserver-k8s 1/1 Running 1 141m
kube-system kube-controller-manager-k8s 1/1 Running 2 (138m ago) 141m
kube-system kube-proxy-wvp6s 1/1 Running 0 140m
kube-system kube-scheduler-k8s 1/1 Running 2 (138m ago) 141m
kube-system kubernetes-dashboard-6c96f5b677-nxpmj 1/1 Running 0 139m
kube-system kubernetes-metrics-scraper-54b676c794-lwqv7 1/1 Running 0 139m
kube-system nodelocaldns-4bzzr 1/1 Running 0 139m
kube-system nvidia-device-plugin-daemonset-nqbzf 1/1 Running 0 89m
(env) xybdiy@k8s:~/deepops$ kubectl get pods -n kube-system | grep -i nvidia
nvidia-device-plugin-daemonset-nqbzf 1/1 Running 0 87m
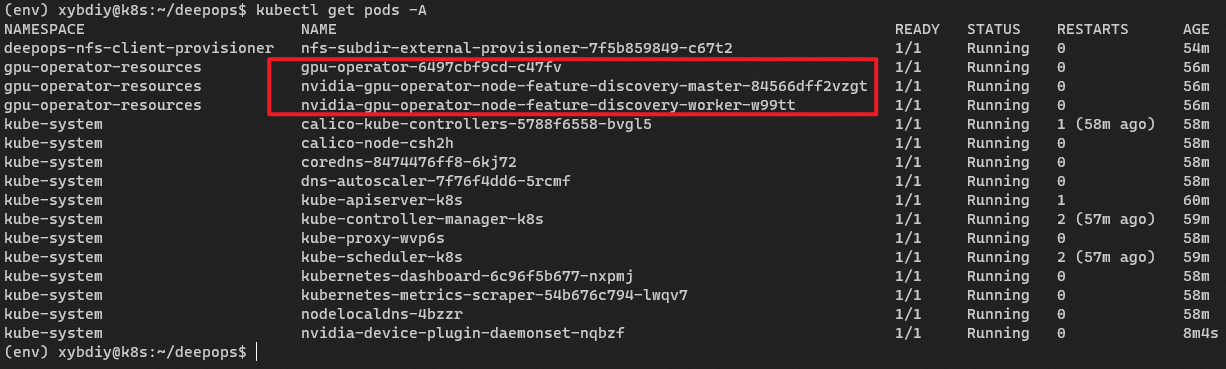
查看容器
安装 Kubernetes — NVIDIA Cloud Native Technologies 文档
NVIDIA/deepops: Tools for building GPU clusters (github.com)
deepops/docs/k8s-cluster at master · NVIDIA/deepops (github.com)

好文啊,按照你的操作步骤,复现了一下,可以实现,支持~


感谢大佬,解决问题了!!





