
 谢谢大佬
谢谢大佬




1,404
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享目标检测是计算机视觉中比较简单的任务,用来在一张图篇中找到某些特定的物体,目标检测不仅要求我们识别这些物体的种类,同时要求我们标出这些物体的位置。

上面的图片中,分别是计算机视觉的三类任务:分类,目标检测
YOLO在2016年被提出,发表在计算机视觉顶会CVPR(Computer Vision and Pattern Recognition)上。
YOLO的全称是you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。因为只需要看一次,YOLO被称为Region-free方法,相比于Region-based方法,YOLO不需要提前找到可能存在目标的Region。
因为YOLO这样的Region-free方法只需要一次扫描,也被称为单阶段(1-stage)模型。Region-based方法方法也被称为两阶段(2-stage)方法。
注释:两阶段--先通过计算机图形学(或者深度学习)的方法,对图片进行分析,找出若干个可能存在物体的区域,将这些区域裁剪下来,放入一个图片分类器中,由分类器分类。
YOLO 的预测是基于整个图片的,并且它会一次性输出所有检测到的目标信息,包括每个物体的信息有五个,分别是物体的中心位置(x,y)和它的高(h)和宽(w),最后是它的类别。
本文主要介绍的yolov5-6.0
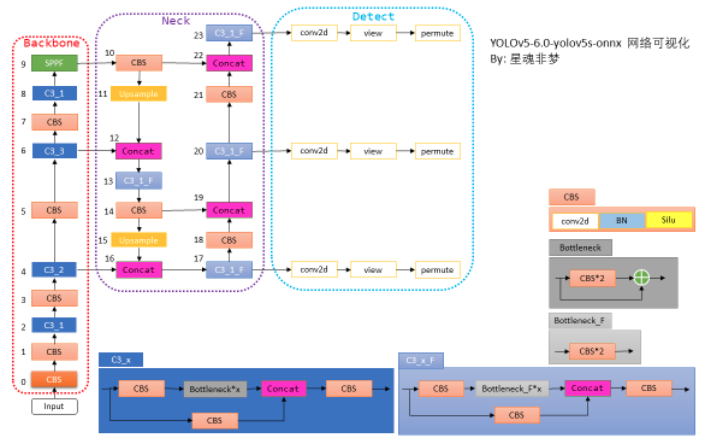
在yolov5-6.0相对于以前的的版本,更新的主要特征有:
(1)在自己想要保存的文件夹内,右键打开终端,输入下面代码进行代码下载
git clone https://github.com/ultralytics/yolov5.git
(2)下载成功后,进入yolov5的文件夹,开始配置代码环境
# 新建虚拟环境
conda create -n yolov5
# 激活虚拟环境
conda activate yolov5
# 安装python包
pip install -r requirements.txt
(3)onnx模型转换
onnx定义了一种可扩展的计算图模型、一系列内置的运算(op)和标准数据类型.可将pytorch模型转成通用的onnx模型框架,然后从ONNX模型转成TensorRT的engine模型
运行以下代码进行模型下载和pytorch模型转换成onnx模型,以yolov5s的模型、图片设置:1*3*640*640为例
python export.py --weights yolov5s6.pt --img 640 --batch 1
onnx导出的工程总结:
(4) 查看onnx模型的结构
netron是一个深度学习模型可视化库,支持onnx、keras、tensorlfow等模型格式
netron的安装命令如下:
pip install netron
安装成功后,在终端输入netron,会弹出地址http://localhost:8080,打开该地址并选择要可视化的模型。
(1)创建一个日记记录器,用于实时反馈模型转换时出现的问题
TRTLogger logger;
(2)构建 Builder 网络元数据,这是模型搭建的入口,网络的 TensorRT 内部表示以及可执行程序引擎,都是由该对象的成员方法生成的
auto builder = make_nvshared(nvinfer1::createInferBuilder(logger));
(3)负责设置模型的一些参数,如是否开启 fp16 模式、int8 模式等。BuilderConfig 是建立在 Builder 基础之上的
auto config = make_nvshared(builder->createBuilderConfig());
(4)构建 Network 计算图,这是最为核心的一个模块
auto network = make_nvshared(builder->createNetworkV2(1));
(5)加载onnx解析器,并加载要转换的onnx模型
auto parser = make_nvshared(nvonnxparser::createParser(*network,logger));
if(!parser->parseFromFile("yolov5s.onnx",1)) // onnx加载后,怎么与network关联起来
{
printf("Failed to parse yolov5s.onnx\n");
// 注意这里的几个指针还没有释放,是有内存泄漏的,后面考虑更优雅的解决
return false;
}
(6)config配置,包括是否多batch,精度选择是FP32、FP16或者INT8等
// 多batch推理
int maxBatchSize = 10;
config->setMaxWorkspaceSize(1<<28);
// 如果模型有多个输入,则必须多个profile
auto profile = builder->createOptimizationProfile();
auto input_tensor = network->getInput(0);
auto input_dims = input_tensor->getDimensions();
// 指定模型的精度 可选fp32(默认),fp16,int8 配置int8时,需要标定数据才能生成正确的int8模型,所以本案例没写int8的实现
// yolov5s:FP32--46MB FP16:25MB
input_dims.d[0] = 1;
config->setFlag(nvinfer1::BuilderFlag::kFP16);
// 配置最小、最优、最大范围
input_dims.d[0] = 1;
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kMIN, input_dims);
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kOPT, input_dims);
input_dims.d[0] = maxBatchSize;
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kMAX, input_dims);
config->addOptimizationProfile(profile);
(7)生成engine模型
auto engine = make_nvshared(builder->buildEngineWithConfig(*network, *config));
(8)将模型序列化,并储存为文件
auto model_data = make_nvshared(engine->serialize());
FILE *f = fopen("yolov5s.trtmodel", "wb");
fwrite(model_data->data(), 1, model_data->size(), f);
fclose(f);
(1)创建一个日记记录器,用于实时反馈模型推理时出现的问题
TRTLogger logger;
(2)读取模型文件
auto engine_data = load_file("yolov5s.trtmodel");
(3)执行推理前,创建一个推理的runtime接口实例
auto runtime = make_nvshared(nvinfer1::createInferRuntime(logger));
(4)模型的反序列化
auto engine = make_nvshared(runtime->deserializeCudaEngine(engine_data.data(),engine_data.size()));
(5)context上下文,创建一些空间来存储中间值
auto execution_context = make_nvshared(engine->createExecutionContext());
(6)在主机内存和显卡分别设置相应的内存空间等操作
(7)图片的预处理
(8)模型推理
bool success = execution_context->enqueueV2((void **)bindings, stream, nullptr);
(9)图片的后处理
本文的环境配置如下
可以参考以上的环境进行配置(当然,没有必要一定要求和我这配置一样,你也可以安装tensorrt7、cuda10.2等)
qt的pro文件配置如下:
TEMPLATE = app # 项目程序的生成模式,默认是app表示生成可执行文件程序,如果是动态库项目就是TEMPLATE = lib。
CONFIG += console c++11
# 导入源文件,由于本案例所有的代码都写在main.cpp文件,所有导入的源文件只需要main.cpp
SOURCES += \
main.cpp
# 由于本案例没有新建.h头文件,所以没写导入头文件的设置
# opencv 配置
INCLUDEPATH += /usr/local/include \
/usr/local/include/opencv \
/usr/local/include/opencv2
DEPENDPATH += /usr/local/lib
LIBS += -L /usr/local/lib/libopencv_*.so
LIBS += -L /usr/local/lib/libopencv_*.so.4.1.0
LIBS += -fopenmp
#cuda cudnn
INCLUDEPATH += /usr/local/cuda/include
LIBS += -L/usr/local/cuda-11.4 # Path to cuda toolkit install
LIBS += -L/usr/local/cuda/lib64
LIBS += -lcudart -lcublas -lcurand -lcuda
#TensorRT
INCLUDEPATH += /home/***/software/TensorRT-8.2.1.8/include
LIBS += -L/home/***/software/TensorRT-8.2.1.8/lib
LIBS += -lnvcaffe_parser -lnvinfer_plugin -lnvparsers -lnvinfer -lnvonnxparser
在新建的main.cpp中,加入以下代码
// tensorRT include
// 编译用的头文件
#include <NvInfer.h>
// onnx解析器的头文件
#include <NvOnnxParser.h>
// 推理用的运行时头文件
#include <NvInferRuntime.h>
// cuda include
#include <cuda_runtime.h>
// opencv库
#include <opencv2/opencv.hpp>
// system include
#include <stdio.h>
#include <math.h>
#include <iostream>
#include <fstream>
#include <vector>
#include <memory>
#include <functional>
#include <unistd.h>
using namespace std;
// Runtime API 的错误处理方式:
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
// 日记等级设置,可以通过设置日记等级来控制哪些等级的日记需要被打印出来
inline const char* severity_string(nvinfer1::ILogger::Severity t){
switch(t){
case nvinfer1::ILogger::Severity::kINTERNAL_ERROR: return "internal_error";
case nvinfer1::ILogger::Severity::kERROR: return "error";
case nvinfer1::ILogger::Severity::kWARNING: return "warning";
case nvinfer1::ILogger::Severity::kINFO: return "info";
case nvinfer1::ILogger::Severity::kVERBOSE: return "verbose";
default: return "unknow";
}
}
// coco数据集的labels,关于coco:https://cocodataset.org/#home
static const char* cocolabels[] = {
"person", "bicycle", "car", "motorcycle", "airplane",
"bus", "train", "truck", "boat", "traffic light", "fire hydrant",
"stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse",
"sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack",
"umbrella", "handbag", "tie", "suitcase", "frisbee", "skis",
"snowboard", "sports ball", "kite", "baseball bat", "baseball glove",
"skateboard", "surfboard", "tennis racket", "bottle", "wine glass",
"cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich",
"orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake",
"chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv",
"laptop", "mouse", "remote", "keyboard", "cell phone", "microwave",
"oven", "toaster", "sink", "refrigerator", "book", "clock", "vase",
"scissors", "teddy bear", "hair drier", "toothbrush"
};
// hsv转bgr
static std::tuple<uint8_t, uint8_t, uint8_t> hsv2bgr(float h, float s, float v){
const int h_i = static_cast<int>(h * 6);
const float f = h * 6 - h_i;
const float p = v * (1 - s);
const float q = v * (1 - f*s);
const float t = v * (1 - (1 - f) * s);
float r, g, b;
switch (h_i) {
case 0:r = v; g = t; b = p;break;
case 1:r = q; g = v; b = p;break;
case 2:r = p; g = v; b = t;break;
case 3:r = p; g = q; b = v;break;
case 4:r = t; g = p; b = v;break;
case 5:r = v; g = p; b = q;break;
default:r = 1; g = 1; b = 1;break;}
return make_tuple(static_cast<uint8_t>(b * 255), static_cast<uint8_t>(g * 255), static_cast<uint8_t>(r * 255));
}
static std::tuple<uint8_t, uint8_t, uint8_t> random_color(int id){
float h_plane = ((((unsigned int)id << 2) ^ 0x937151) % 100) / 100.0f;;
float s_plane = ((((unsigned int)id << 3) ^ 0x315793) % 100) / 100.0f;
return hsv2bgr(h_plane, s_plane, 1);
}
// 打印日记信息
class TRTLogger : public nvinfer1::ILogger{
public:
virtual void log(Severity severity, nvinfer1::AsciiChar const* msg) noexcept override{
if(severity <= Severity::kWARNING){
// 打印带颜色的字符,格式如下:
// printf("\033[47;33m打印的文本\033[0m");
// 其中 \033[ 是起始标记
// 47 是背景颜色
// ; 分隔符
// 33 文字颜色
// m 开始标记结束
// \033[0m 是终止标记
// 其中背景颜色或者文字颜色可不写
// 部分颜色代码 https://blog.csdn.net/ericbar/article/details/79652086
if(severity == Severity::kWARNING){
printf("\033[33m%s: %s\033[0m\n", severity_string(severity), msg);
}
else if(severity <= Severity::kERROR){
printf("\033[31m%s: %s\033[0m\n", severity_string(severity), msg);
}
else{
printf("%s: %s\n", severity_string(severity), msg);
}
}
}
} logger;
// 通过智能指针管理nv返回的指针参数
// 内存自动释放,避免泄漏
template<typename _T>
shared_ptr<_T> make_nvshared(_T* ptr){
return shared_ptr<_T>(ptr, [](_T* p){p->destroy();});
}
// 判断文件是否存在
bool exists(const string& path){
#ifdef _WIN32
return ::PathFileExistsA(path.c_str());
#else
return access(path.c_str(), R_OK) == 0;
#endif
}
bool build_model(){
// 判断trt模型是否存在,如果已有trt模型,则跳过生成trt模型的步骤
if(exists("yolov5s.trtmodel")){
printf("yolov5s.trtmodel has exists.\n");
return true;
}
// 构建logger日记记录器
TRTLogger logger;
// 这是基本需要的组件
// 构建 Builder 网络元数据,这是模型搭建的入口,网络的 TensorRT 内部表示以及可执行程序引擎,都是由该对象的成员方法生成的
auto builder = make_nvshared(nvinfer1::createInferBuilder(logger));
// 负责设置模型的一些参数,如是否开启 fp16 模式、int8 模式等。BuilderConfig 是建立在 Builder 基础之上的
auto config = make_nvshared(builder->createBuilderConfig());
// 构建 Network 计算图,是 最为核心的一个模块。
auto network = make_nvshared(builder->createNetworkV2(1));
auto parser = make_nvshared(nvonnxparser::createParser(*network,logger));
if(!parser->parseFromFile("yolov5s.onnx",1)) // onnx加载后,怎么与network关联起来
{
printf("Failed to parse yolov5s.onnx\n");
// 注意这里的几个指针还没有释放,是有内存泄漏的,后面考虑更优雅的解决
return false;
}
// 多batch推理
int maxBatchSize = 10;
config->setMaxWorkspaceSize(1<<28);
// 如果模型有多个输入,则必须多个profile
auto profile = builder->createOptimizationProfile();
auto input_tensor = network->getInput(0);
auto input_dims = input_tensor->getDimensions();
// 指定模型的精度 可选fp32(默认),fp16,int8 配置int8时,需要标定数据才能生成正确的int8模型
// yolov5s:FP32--46MB FP16:25MB INT8:13MB
input_dims.d[0] = 1;
config->setFlag(nvinfer1::BuilderFlag::kFP16);
// 配置最小、最优、最大范围
input_dims.d[0] = 1;
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kMIN, input_dims);
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kOPT, input_dims);
input_dims.d[0] = maxBatchSize;
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kMAX, input_dims);
config->addOptimizationProfile(profile);
auto engine = make_nvshared(builder->buildEngineWithConfig(*network, *config));
if (engine == nullptr)
{
printf("Build engine failed.\n");
return false;
}
// 将模型序列化,并储存为文件
auto model_data = make_nvshared(engine->serialize());
FILE *f = fopen("yolov5s.trtmodel", "wb");
fwrite(model_data->data(), 1, model_data->size(), f);
fclose(f);
return true;
}
// 读取文件里面的信息
vector<unsigned char> load_file(const string& file){
ifstream in(file, ios::in | ios::binary);
if (!in.is_open())
return {};
in.seekg(0, ios::end);
size_t length = in.tellg();
std::vector<uint8_t> data;
if (length > 0){
in.seekg(0, ios::beg);
data.resize(length);
in.read((char*)&data[0], length);
}
in.close();
return data;
}
void inference(){
// 构建logger日记记录器
TRTLogger logger;
// 读取模型的信息
auto engine_data = load_file("yolov5s.trtmodel");
auto runtime = make_nvshared(nvinfer1::createInferRuntime(logger));
// 反序列化
auto engine = make_nvshared(runtime->deserializeCudaEngine(engine_data.data(),engine_data.size()));
if(engine == nullptr)
{
printf("Deserialize cuda engine failed.\n");
// runtime->destroy();
return;
}
if(engine->getNbBindings()!=2)
{
printf("你的onnx导出有问题,必须是1个输入和1个输出,你这明显有:%d个输出.\n", engine->getNbBindings() - 1);
return;
}
// 创建流变量
cudaStream_t stream = nullptr;
checkRuntime(cudaStreamCreate(&stream));
// 创建上下文
auto execution_context = make_nvshared(engine->createExecutionContext());
// 配置网络输入的内存空间大小
int input_batch = 1;
int input_channel = 3;
int input_height = 640;
int input_width = 640;
int input_numel = input_batch * input_channel * input_height * input_width;
float* input_data_host = nullptr;
float* input_data_device = nullptr;
// 在主机内存和显卡分别设置相应的内存空间
checkRuntime(cudaMallocHost(&input_data_host,input_numel * sizeof(float)));
checkRuntime(cudaMalloc(&input_data_device,input_numel * sizeof(float)));
// 根据trt模型中的输出,来配置输出的内存空间大小
auto output_dims = engine->getBindingDimensions(1);
int output_numbox = output_dims.d[1];
int output_numprob = output_dims.d[2];
int num_classes = output_numprob -5;
int output_numel = input_batch * output_numbox * output_numprob;
float* output_data_host = nullptr;
float* output_data_device = nullptr;
checkRuntime(cudaMallocHost(&output_data_host, output_numel * sizeof(float)));
checkRuntime(cudaMalloc(&output_data_device, output_numel * sizeof(float)));
// 明确当前推理时,使用的数据输入大小
auto input_dims = engine->getBindingDimensions(0);
input_dims.d[0] = input_batch;
execution_context->setBindingDimensions(0, input_dims);
// 读取视频流
cv::VideoCapture cap("/home/***/视频/2.mp4");
cv::Mat image;
cap>>image;
// 通过双线性插值对图像进行resize
float scale_x = input_width / (float)image.cols;
float scale_y = input_height / (float)image.rows;
float scale = std::min(scale_x,scale_y);
float i2d[6],d2i[6];
// resize图像,源图像和目标图像几何中心的对齐
i2d[0] = scale;
i2d[1] = 0;
i2d[2] = (-scale * image.cols + input_width + scale - 1) * 0.5;
i2d[3] = 0;
i2d[4] = scale;
i2d[5] = (-scale * image.rows + input_height + scale - 1) * 0.5;
cv::Mat m2x3_i2d(2, 3, CV_32F, i2d); // image to dst(network), 2x3 matrix
cv::Mat m2x3_d2i(2, 3, CV_32F, d2i); // dst to image, 2x3 matrix
cv::invertAffineTransform(m2x3_i2d, m2x3_d2i); // 计算一个反仿射变换
cv::Mat input_image(input_height, input_width, CV_8UC3);
while(1)
{
clock_t startTime, endTime;
startTime = clock();
// 获取图像
cap >> image;
// 仿射变换
cv::warpAffine(image,input_image,m2x3_i2d,input_image.size(),cv::INTER_LINEAR, cv::BORDER_CONSTANT, cv::Scalar::all(114)); // 对图像做平移缩放旋转变换,可逆
int image_area = input_image.cols * input_image.rows;
unsigned char *pimage = input_image.data;
float *phost_b = input_data_host + image_area * 0;
float *phost_g = input_data_host + image_area * 1;
float *phost_r = input_data_host + image_area * 2;
for (int i = 0; i < image_area; ++i, pimage += 3)
{
// 注意这里的顺序rgb调换了
*phost_r++ = pimage[0] / 255.0f;
*phost_g++ = pimage[1] / 255.0f;
*phost_b++ = pimage[2] / 255.0f;
}
std::cout << "预处理时间: " << (double)(clock() - startTime) / CLOCKS_PER_SEC << "s" << std::endl;
auto startTime1 = clock();
// 图像的数据由主机内存传到显存上
checkRuntime(cudaMemcpyAsync(input_data_device, input_data_host, input_numel * sizeof(float), cudaMemcpyHostToDevice, stream));
// 设置模型推理的输入输出
float *bindings[] = {input_data_device, output_data_device};
// 模型推理
bool success = execution_context->enqueueV2((void **)bindings, stream, nullptr);
checkRuntime(cudaMemcpyAsync(output_data_host, output_data_device, sizeof(float) * output_numel, cudaMemcpyDeviceToHost, stream));
checkRuntime(cudaStreamSynchronize(stream));
std::cout << "推理时间: " << (double)(clock() - startTime1) / CLOCKS_PER_SEC << "s" << std::endl;
startTime1 = clock();
// decode box:从不同尺度下的预测狂还原到原输入图上(包括:预测框,类被概率,置信度)
vector<vector<float>> bboxes;
float confidence_threshold = 0.25;
float nms_threshold = 0.5;
for (int i = 0; i < output_numbox; ++i)
{
float *ptr = output_data_host + i * output_numprob;
float objness = ptr[4];
// 先初步进行阈值判断 confidence = objness
if (objness < confidence_threshold)
continue;
float *pclass = ptr + 5;
int label = std::max_element(pclass, pclass + num_classes) - pclass;
float prob = pclass[label];
float confidence = prob * objness;
// 再进行阈值判断 confidence = prob * objness
if (confidence < confidence_threshold)
continue;
// 中心点、宽、高
float cx = ptr[0];
float cy = ptr[1];
float width = ptr[2];
float height = ptr[3];
// 预测框
float left = cx - width * 0.5;
float top = cy - height * 0.5;
float right = cx + width * 0.5;
float bottom = cy + height * 0.5;
// 对应图上的位置---通过仿射变换,映射到原图上
float image_base_left = d2i[0] * left + d2i[2];
float image_base_right = d2i[0] * right + d2i[2];
float image_base_top = d2i[0] * top + d2i[5];
float image_base_bottom = d2i[0] * bottom + d2i[5];
bboxes.push_back({image_base_left, image_base_top, image_base_right, image_base_bottom, (float)label, confidence});
}
// nms非极大抑制 按照置信度进行排列
std::sort(bboxes.begin(), bboxes.end(), [](vector<float> &a, vector<float> &b)
{ return a[5] > b[5]; });
std::vector<bool> remove_flags(bboxes.size());
std::vector<vector<float>> box_result;
box_result.reserve(bboxes.size());
auto iou = [](const vector<float> &a, const vector<float> &b)
{
float cross_left = std::max(a[0], b[0]);
float cross_top = std::max(a[1], b[1]);
float cross_right = std::min(a[2], b[2]);
float cross_bottom = std::min(a[3], b[3]);
float cross_area = std::max(0.0f, cross_right - cross_left) * std::max(0.0f, cross_bottom - cross_top);
float union_area = std::max(0.0f, a[2] - a[0]) * std::max(0.0f, a[3] - a[1]) + std::max(0.0f, b[2] - b[0]) * std::max(0.0f, b[3] - b[1]) - cross_area;
if (cross_area == 0 || union_area == 0)
return 0.0f;
return cross_area / union_area;
};
for (int i = 0; i < bboxes.size(); ++i)
{
if (remove_flags[i])
continue;
auto &ibox = bboxes[i];
box_result.emplace_back(ibox);
for (int j = i + 1; j < bboxes.size(); ++j)
{
if (remove_flags[j])
continue;
auto &jbox = bboxes[j];
if (ibox[4] == jbox[4])
{
// iou判断
if (iou(ibox, jbox) >= nms_threshold)
remove_flags[j] = true;
}
}
}
// 可视化
for (int i = 0; i < box_result.size(); ++i)
{
auto &ibox = box_result[i];
float left = ibox[0];
float top = ibox[1];
float right = ibox[2];
float bottom = ibox[3];
int class_label = ibox[4];
float confidence = ibox[5];
cv::Scalar color;
tie(color[0], color[1], color[2]) = random_color(class_label);
cv::rectangle(image, cv::Point(left, top), cv::Point(right, bottom), color, 3);
auto name = cocolabels[class_label];
auto caption = cv::format("%s %.2f", name, confidence);
int text_width = cv::getTextSize(caption, 0, 1, 2, nullptr).width + 10;
cv::rectangle(image, cv::Point(left - 3, top - 33), cv::Point(left + text_width, top), color, -1);
cv::putText(image, caption, cv::Point(left, top - 5), 0, 1, cv::Scalar::all(0), 2, 16);
}
cv::imshow("图像坐标系", image);
cv::waitKey(1);
std::cout << "后处理时间: " << (double)(clock() - startTime1) / CLOCKS_PER_SEC << "s" << std::endl;
endTime = clock(); //计时结束
std::cout << "预处理+推理+后处理的总时间: " << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << std::endl;
}
checkRuntime(cudaStreamDestroy(stream));
checkRuntime(cudaFreeHost(input_data_host));
checkRuntime(cudaFreeHost(output_data_host));
checkRuntime(cudaFree(input_data_device));
checkRuntime(cudaFree(output_data_device));
}
int main(){
if(!build_model()){
return -1;
}
inference();
return 0;
}
注释:
(1)如果出现找不到onnx文件的话,一般是onnx的文件路径没给对,在第157行重新设置一下路径
(2)需要重新在第276行设置一下视频的路径,否则会报错
本案例在CPU:I7 10750H和GPU:1660ti,FP16和FP32的实际测试效果如下:
| 预处理时间 | 网络推理时间 | 后处理时间 |
| 0.019595s | 0.007355s | 0.01052s |
| 0.019518s | 0.004706s | 0.010462s |
在本案例的代码中,预处理耗时较大,后期需要进一步优化代码

cudaStreamSynchronize(stream); it spend 100+ms这个正常吗?

大佬,仿射变换那里可以细说下吗,这里这么写的原因没看懂





写的很详细,可以加Q私聊吗


好详细,必须好评

牛



