














1,412
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享 本篇博客主要介绍了本人入门CUDA编程的过程,也是《CUDA编程基础与实践》读后感。在此过程中,我完成了对于二维离散傅里叶变换的CUDA加速,运行时间比手写C++代码提高百万倍。本篇博客包含的知识有下面几个方面,二维离散傅里叶变换,CUDA编程的线程组织,GPU加速的关键,CUDA核函数,GPU的内存组织及利用,CUDA流概念。代码在https://github.com/Aries-HJH/CUDA_DFT2 文章最后也有。
本篇博客的运行设备是NVIDIA TX2,GPU型号是NVIDIA Tegra X2。具体参数如下图所示:
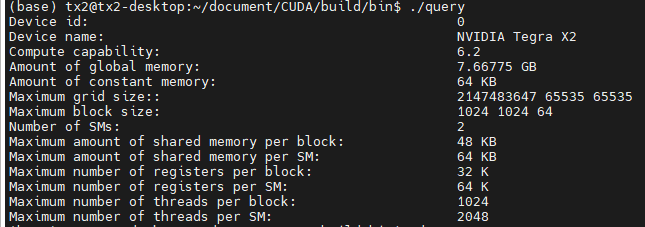
只要知道了GPU的计算能力就可以查到它所有的信息,比上图更加详细。这个计算能力的版本号标识了GPU可支持的功能。它由主版本号和副版本号组成,具有相同主版本号的设备具有相同的核心架构。 主要版本号为 8 用于 NVIDIA Ampere GPU 架构的设备,7 用于 Volta 架构的设备,6 用于Pascal 架构的设备,5 用于 Maxwell 架构的设备,3 用于 Kepler 架构的设备,2 个用于 Fermi 架构的设备,1 个用于 Tesla 架构的设备。例如6.2,主版本是6,这意味着TX2的GPU使用的是Pascal结构。副版本号是一种增量式的改进。
如果想知道计算能力对应的各项信息,可以查询 https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capabilities 中table15.
一个GPU由多个流处理器构成,而每个SM有若干个CUDA核心,每个SM是相对独立的。NVIDIA GPU 架构围绕可扩展的多线程流式多处理器 (SM) 阵列构建。 当主机 CPU 上的 CUDA 程序调用内核网格时,网格的块被枚举并分发到具有可用执行能力的多处理器。 一个线程块的线程在一个多处理器上并发执行,多个线程块也可以在一个多处理器上并发执行。 当线程块终止时,新块在空出的多处理器上启动。
详细内容请看这个链接 https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#hardware-implementation
二维傅里叶变换(DFT)公式:
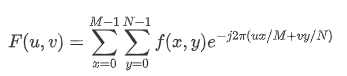
其中f(x,y)是大小为MxN的数字图像
相应的反变换公式:
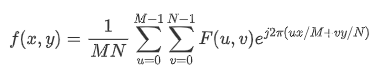
这样的公式不方便编程,根据欧拉公式展开:
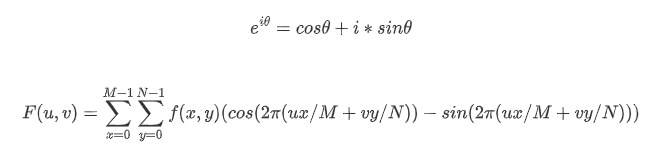
同理反变换为:
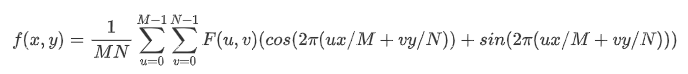
我引用的是博主lsaac320的文章 链接为 https://blog.csdn.net/Isaac320/article/details/122085537
struct ComplexNum {
double real;
double imagin;
};
....
clock_t start_time, end_time;
start_time = clock();
DFT2D(dst, img, w, h);//dst:结果谱,img:图像,w:宽,h:高
end_time = clock();
cout << "DFT2 time: " << (float) (end_time - start_time) / CLOCKS_PER_SEC << "s" << endl;
....
....
start_time = clock();
IDFT2D(dst, out3, w, h);//dst:谱,img:结果图像,w:宽,h:高
end_time = clock();
cout << "IDFT2 time: " << (float) (end_time - start_time) / CLOCKS_PER_SEC << "s" << endl;
....
int DFT2D(ComplexNum** dst, Mat img, int w, int h) {
for (int u = 0; u < h; u++) {
for (int v = 0; v < w; v++) {//遍历结果图像
double real = 0.0;
double imagin = 0.0;
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++) {//遍历将要计算的图像
double I = (double)img.at<uchar>(i, j);//公式计算
double x = M_PI * 2 * ((double)i * u / (double)w + (double)j * v / (double)h);
real += cos(x) * I;
imagin += -sin(x) * I;
}
}
dst[u][v].real = real;//保存结果
dst[u][v].imagin = imagin;
}
}
return 0;
}
int IDFT2D(ComplexNum** src, Mat out, int size_w, int size_h) {
for (int i = 0; i < size_h; i++) {
for (int j = 0; j < size_w; j++) {//遍历结果图像
double real = 0.0;
double imagin = 0.0;
for (int u = 0; u < size_h; u++) {//遍历将要计算的图像
for (int v = 0; v < size_w; v++) {
double R = src[u][v].real;//实部
double I = src[u][v].imagin;//虚部
double x = M_PI * 2 * ((double)i*u / (double)size_w + (double)j*v / (double)size_h);
real += R * cos(x) - I * sin(x);//公式
imagin += I * cos(x) + R * sin(x);
}
}
double g = sqrt(real*real + imagin * imagin)*1.0 /(size_w*size_h);
out.at<uchar>(i, j) = (uchar)g;//结果保存
}
}
return 0;
}
C++版在TX2上的运行结果如图:

| 原图(150*150) | 中心化后的谱 | 逆变换后的结果 |
|---|---|---|
|
|
|
这是本篇博客的主要部分
想要编写出CUDA并行函数需要知道CUDA中的线程是如何组织的。GPU仅仅只是一个设备,它需要命令才可以工作。所以代码中必须要有GPU使用的代码,即设备代码。
主机是通过核函数来调用设备的,核函数类似与C++中的函数,但是它被限定词修饰,限定词包括下面几个
1. 核函数的调用格式是 Kernel_function<<<1, 1>>>(); 想让核函数工作,我们就需要告诉他你要用多少个线程?
核函数的线程组织通常成若干个线程块。<<<grid_size, block_size>>>中第一个数是线程块的个数,第二个是线程块中的线程数,核函数的全部线程块构成一个网格,总共的线程数就是网格大小乘线程块大小。这两个参数可以是多维的(在不同的设备中支持不同的维度,具体查看计算能力表),即可以定义 dim3 grid_size(3, 3); dim3 block_size(2, 2); 。大概的线程组织如图(图片引自 https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html Figure4)。
2. 告诉核函数线程配置之后,我们还需要知道如何找到这些线程?
核函数内部有内建变量:
接下来我们看一些例子:
#include <stdio.h>
__global__ void hello_from_gpu() {
const int bidx = blockIdx.x;
const int bidy = blockIdx.y;
const int tidx = threadIdx.x;
const int tidy = threadIdx.y;
printf("Hello World from block (%d, %d) and thread (%d, %d)!\n", bidx, bidy, tidx, tidy);
}
int main(void) {
dim3 grid_size(2, 2);
dim3 block_size(3, 2);
hello_from_gpu<<<grid_size, block_size>>>();//核函数调用
cudaDeviceSynchronize();//同步主机与设备,刷新缓冲区,这样才能显示文字。
return 0;
}
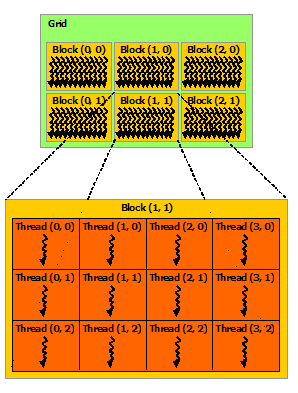
运行结果:
每个线程块在执行时是独立的!没有先后。如果是多维的配置,gridDim和blockDim便会有x, y, z成员,x是最内层,变化最快,z是外层,变化慢。TX2设备最多三维。注意:线程块中的线程是有数量限制的,TX2最多有1024个
根据《CUDA编程基础与实践》,基本框架如下:
头文件包含
常量定义
C++ 自定义函数和CUDA核函数的声明(原型)
int main(void)
{
分配主机与设备内存
初始化主机中的数据
将某些数据从主机复制到设备
调用核函数在设备中进行计算
将某些数据从设备复制到主机
释放主机与设备内存
}
C++ 自定义函数和CUDA 核函数的定义(实现)
主要代码:
主函数
.....
cudaMalloc((void **)&d_img, M);//分配cuda内存空间
cudaMalloc((void **)&dft_cuda, N * sizeof(ComplexNum));
cudaMemcpy(d_img, h_img, M, cudaMemcpyHostToDevice);//将拉平成一维数组的图像从主机转移到设备
const int block_size = 128;
const int grid_size = N / 128;
clock_t start_time, end_time;
start_time = clock();
cudadft2<<<grid_size+1, block_size>>>(d_img, dft_cuda, N, w, h);//调用核函数
end_time = clock();
cout << "DFT2 time: " << (float) (end_time - start_time) * 1000 / CLOCKS_PER_SEC << "ms" << endl;
cudaMemcpy(dft_img, dft_cuda, N * sizeof(ComplexNum), cudaMemcpyDeviceToHost);//将计算好的数组从设备转移到主机,因为在主机做尺度的变换很慢,这一行后续会进行改进。
.....
.....
start_time = clock();
cudaIdft2<<<grid_size+1, block_size>>>(d_img, dft_cuda, N, w, h);//调用核函数
end_time = clock();
cout << "IDFT2 time: " << (float) (end_time - start_time) * 1000 / CLOCKS_PER_SEC << "ms" << endl;
cudaMemcpy(h_img, d_img, M, cudaMemcpyDeviceToHost);//将计算后的数组从设备转移到主机,因为图像一大,在主机做变换很慢,这一行后续会进行改进。
....
傅里叶变换的核函数
void __global__ cudadft2(double *d_img, ComplexNum *dft_img, const int N, int w, int h) {
int n = blockDim.x * blockIdx.x + threadIdx.x;//计算线程索引,[0-N],每一个线程都做一次底下的运算。
if (n < N) {//超过数据的线程就不算了,不必要。
double real = 0.0;//实部
double imagin = 0.0;//虚部
for (int i = 0; i < N; i++) {
double x = M_PI * 2 * ((double)(i / w) * (double)(n / w) / (double)w + (double)(i % w) * (double)(n % w) / (double)h);//公式中的计算式,拉成一维后,这里的图像原坐标值需要简单计算。
double I = d_img[i];
real += cos(x) * I;
imagin += -sin(x) * I;
}
dft_img[n].real = real;//保存结果
dft_img[n].imagin = imagin;
}
}
傅里叶逆变换的核函数
void __global__ cudaIdft2(double *d_img, ComplexNum *dft_img, const int N, int w, int h) {
int n = blockDim.x * blockIdx.x + threadIdx.x;//计算线程索引,[0-N],每一个线程都做一次底下的运算。
if (n < N) {//超过数据的线程就不算了,不必要。
double real = 0.0;//实部
double imagin = 0.0;//虚部
for (int i = 0; i < N; i++) {
double R = dft_img[i].real;
double I = dft_img[i].imagin;
double x = M_PI * 2 * ((double)(n / w)*(i / w) / (double)w + (double)(n % w) * (i % w) / (double)h);
real += R * cos(x) - sin(x) * I;//公式中的计算式
imagin += I * cos(x) + R * sin(x);
}
double g = sqrt(real*real + imagin * imagin)*1.0 /(w * h);
d_img[n] = g;//保存结果
}
}
运行结果

| 原图(150*150) | 中心化的谱 | 逆变换的结果 |
|---|---|---|
|
|
|
设备内存分配与释放:CUDA中的内存分配可由 cudaMalloc() 实现。内存的释放可由 cudaFree() 实现。
主机与设备之间的数据传递,这两者在运行的时候不可以跨设备访问数据,我们需要将数据转移之后在处理。这里可以使用 cudaMemcpy() 转移。在这里展示一下这个函数的原型,比较重要。
cudaError_t cudaMemcpy(
void *dst,
const void *src,
size_t, count,
enum cudaMemcpyKind kind
);
dst: 目标地址。 src:源地址。count:复制数据的字节数。kind:数据传递方向,4个值。
数据与线程:根据线程位置(标识)处理数据。在本例中,因为是并行执行,并且每一个线程计算所需的数据不与其他线程关联,所以我们只需要索引到线程的标识,控制它做事即可。例如本例的线程n,n = blockDim.x * blockIdx.x + threadIdx.x;
if的存在:线程分配时,往往由于数据量不能整除blocksize,gridsize的值就要多取一个,那么这样就会多出一些不必要的线程操作,所以用if规避一下。
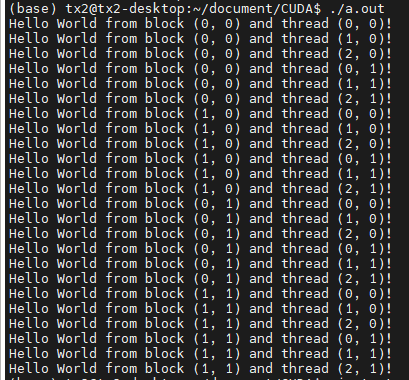
图片引用于《CUDA编程基础与实践》,箭头方向为数据可以移动的方向。
有常量缓存的全局内存。可见范围与生命周期与全局内存一样,但是常量内存可读不可写。常量内存访问速度比全局内存高,代价是一个线程束的线程要读取相同常量内存的数据。
具有缓存的全局内存。可见范围与生命周期与全局内存一样。有缓存,会更快一些。
核函数中定义的不加任何限定符的变量一般存放在寄存器中。比如本例中的线程编号n。寄存器变量尽可以被一个线程知道。访问速度最高,数量有限。
核函数中定义的不加任何限定符的变量有可能存放在局部内存中。从硬件上说,局部内存是全局内存的一部分,延迟很高。
全局内存对于整个网格的所有线程都可见,没有存放在GPU上,具有较高的延时和较低的访问速度。全局内存的生命周期不由核函数决定,由主机端决定。《CUDA编程基础与实践》中讲到CUDA中还有一种内部构造对用户不透明的全局内存,CUDA Array。
由于全局内存延时高,费米架构之后的GPU都采用L1缓存和L2缓存减少延时。
这里先解释一下线程束,线程束是线程块的细分结构,在TX2中由32个线程组成。
关于全局内存的访问,有合并与非合并之分。合并访问指的是一个线程束对全局内存的一次访问请求导致最少数量的数据传输。在仅仅使用L2缓存的情况下,一次传输指的是将32字节的数据从全局内存通过L2传到SM。在单精度数据(4字节)下,线程束需要128字节的数据。那么需要4次传输。这需要保证全局内存数据首地址是32字节的整数倍。这一点cudaMalloc已经帮我们做到了,它分配的内存首地址是256字节的整数倍。
下面是几种内存访问模式(以下例子来自《CUDA编程基础与实践》):
顺序的合并访问。
void __global__ add(float *x, float *y, float *z)
{
int n = threadIdx.x + blockIdx.x * blockDim.x;
z[n] = x[n] + y[n];
}
add<<<128,32>>>(x,y,z);
第一个线程块的线程束访问数组中第0~31个元素,对应128字节的连续数据,4次传输。
乱序合并访问。
void __global__ add(float *x, float *y, float *z)
{
int tid_permuted = threadIdx.x ^ 0x1;
int n = tid_permuted + blockIdx.x * blockDim.x;
z[n] = x[n] + y[n];
}
add<<<128,32>>>(x,y,z);
0~31的整数,交换两个相邻的数。虽然是乱着找, 但是还就是那么一点数据,并没有越过界限,不用多次传输。
不对齐的非合并访问。
void __global__ add(float *x, float *y, float *z)
{
int n = threadIdx.x + blockIdx.x * blockDim.x + 1;
z[n] = x[n] + y[n];
}
add<<<128,32>>>(x,y,z);
这下坏了,第一个线程块中的线程束访问的是1~32个元素,首地址却是256字节的整数倍。这个线程束想访问随后一个字节的数据,它就需要再做一次数据传输。
跨越式非合并访问。
void __global__ add(float *x, float *y, float *z)
{
int n = blockIdx.x + threadIdx.x * gridDim.x;
z[n] = x[n] + y[n];
}
add<<<128,32>>>(x,y,z);
这下线程束访问的就是不是一片连续的数据了,找32个数据需要传输32次。
广播式非合并访问
void __global__ add(float *x, float *y, float *z)
{
int n = threadIdx.x + blockIdx.x * blockDim.x;
z[n] = x[n] + y[n];
}
add<<<128,32>>>(x,y,z);
第一个线程块中的线程数一致访问数组x的0号元素。一次传输,但只用了4字节数据,合并度不高。
在上述例子中我们访问内存的方式是顺序合并访问,每个线程块的线程束访问的都是连续的128字节数据。为了对比我们将其稍作修改,使其变成跨越式的非合并访问,意思是线程束中的线程访问的不是连续的128字节数据。
跨越式非合并访问代码:
void __global__ cudadft2(double *d_img, ComplexNum *dft_img, const int N, int w, int h) {
//int n = blockDim.x * blockIdx.x + threadIdx.x;
int n = blockIdx.x + threadIdx.x * gridDim.x; //跨越式非合并访问,写入
if (n < N) {
double real = 0.0;
double imagin = 0.0;
for (int i = 0; i < N; i++) {
double x = M_PI * 2 * ((double)(i / w) * (double)(n / w) / (double)w + (double)(i % w) * (double)(n % w) / (double)h);
double I = d_img[i];
real += cos(x) * I;
imagin += -sin(x) * I;
}
dft_img[n].real = real;
dft_img[n].imagin = imagin;
}
}
| 原图(300*300) | 模式 | 时间 | 结果 |
|---|---|---|---|
| 顺序合并访问 |
|
|
| 跨越式非合并访问 |
|
|
注意:pascal架构之后的GPU,会自动使用函数__ldg()读取全局内存,从而对数据的读取进行缓存,缓解非合并带来的影响。
编写到这个地步,影响整体代码速度的是主机的处理部分,包括生成图像谱,中心化等等。我决定将它们也并行化,后续会给出整体代码。其中有一个内容是求scale,这是为了将谱变到图像数据CV_8UC1范围内,它需要求最大值与最小值,C++代码如下:
int Transcale(Mat& src, Mat& out) {
int sw = src.cols;
int sh = src.rows;
//求最大最小值
double max = src.at<double>(0, 0);//p[0];
double min = src.at<double>(0, 0);//p[0];
for (int i = 0; i < sh; i++) {
for (int j = 0; j < sw; j++) {
if (src.at<double>(i, j) > max) max = src.at<double>(i, j);
if (src.at<double>(i, j) < min) min = src.at<double>(i, j);
}
}
double scale = 255.0 / (max - min);
//中心化
for (int u = 0; u < sh; u++) {
for (int v = 0; v < sw; v++) {
if ((u<(sh/2)) && (v<(sw/2)))
out.at<uchar>(u, v) = (uchar)((src.at<double>((u + sh/2), (v + sw / 2)) - min)*scale);
else if ((u<(sh/2)) && (v>=(sw/2)))
out.at<uchar>(u, v) = (uchar)((src.at<double>((u + sh/2), (v - sw / 2)) - min)*scale);
else if ((u>=(sw/2)) && (v<(sw/2)))
out.at<uchar>(u, v) = (uchar)((src.at<double>((u - sh/2), (v + sw / 2)) - min)*scale);
else if ((u>=(sh/2)) && (v>=(sw/2)))
out.at<uchar>(u, v) = (uchar)((src.at<double>((u - sh/2), (v - sw / 2)) - min)*scale);
}
}
return 0;
}
由代码可见,当图像尺寸变大时,这里会非常慢,所以将其并行化。用规约的思想,意思就是一个数组,现将其前一半与后一半对应相比,这一下就只剩一半了,不停反复,最后第一个数据就是答案(这些操作都是线程块内的操作,所以一个线程块128个线程,第一个数据就是这128个数据的答案,最终会有grid_size个数据,还得要找其中的最大值,这一块可以在主机中,也可以在设备中操作,推荐设备找的快)。并行化时使用了共享内存,减少了全局内存的访问次数。
本例使用了设备与主机搭配着找最值,主要是为了用一下统一内存。下面介绍一下共享内存和统一内存,代码中有他们的使用方式。
共享内存存在与芯片上,速度很快。共享内存对整个线程块可见,生命周期与线程块一致。共享内存是为了减少对全局内存的访问。
想要定义一个共享内存,只要加上一个限定符 **__shared__**。
统一内存是一种逻辑上的概念,既不是主机内存,也不是显存,是CPU和GPU都可以访问的内存,最低要求GPU具有开普勒架构。
优势在于:
动态的统一内存可以用cudaMallocManaged() 进行分配,原型如下,参数flags默认为cudaMenAttachGlobal,代表这段内存可以被所有设备访问。使用cudaFree() 释放。
cudaError_t cudaMallocManaged( void **devPtr, size_t size, unsigned flags = 0);
静态的看代码。
CUDA代码如下:
//静态统一内存变量
__device__ __managed__ double opt[2] = {0, 0};// opt[0]: max, opt[1]: min
// 找最大值
void __global__ cudaGetMax(double *d_img, double *d_imgy, int N) {
int tid = threadIdx.x;
int bid = blockIdx.x;
int n = bid * blockDim.x + tid;
__shared__ double s_dimg[128]; //定义共享内存
s_dimg[tid] = (n < N) ? d_img[n] : 0.0; //讲数据保存在共享内存中
__syncthreads(); //同步线程块中的线程,确保前面的指令所有线程都运行完毕
// 规约比大小
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
if (tid < offset) {
if ( s_dimg[tid] < s_dimg[tid + offset])
s_dimg[tid] = s_dimg[tid + offset];
}
__syncthreads();
}
//确保一个线程块只执行一次
if (tid == 0) {
d_imgy[bid] = s_dimg[0];
}
}
//尺度转换 opt[0] 最大值, opt[1]最小值
void __global__ cudaTransscale(uchar* ucharimg, double* d_img, int h, int w, int N) {
int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n < N) {
if( ((int(n / w) < (h / 2))) && ((int(n % w) < (w / 2))))
ucharimg[n] = (uchar)((d_img[ (int(n / w) + h/2) * w + (int(n % w) + w / 2)] - opt[1]) * (255.0 / (opt[0] - opt[1])));
else if( ((int(n / w) < (h / 2))) && ((int(n % w) >= (w / 2))))
ucharimg[n] = (uchar)((d_img[ (int(n / w) + h/2) * w + (int(n % w) - w / 2)] - opt[1]) * (255.0 / (opt[0] - opt[1])));
else if( ((int(n / w) >= (h / 2))) && ((int(n % w) < (w / 2))))
ucharimg[n] = (uchar)((d_img[ (int(n / w) - h/2) * w + (int(n % w) + w / 2)] - opt[1]) * (255.0 / (opt[0] - opt[1])));
else if( ((int(n / w) >= (h / 2))) && ((int(n % w) >= (w / 2))))
ucharimg[n] = (uchar)((d_img[ (int(n / w) - h/2) * w + (int(n % w) - w / 2)] - opt[1]) * (255.0 / (opt[0] - opt[1])));
}
}
主函数部分:
......
// get Max
cudaGetMax<<<grid_size+1, block_size>>>(d_img, d_imgy, N);
cudaMemcpy(h_imgy, d_imgy, sizeof(double) * (grid_size+1), cudaMemcpyDeviceToHost);
opt[0] = h_imgy[0];
for(int i = 1; i < grid_size+1; i++) {
if (h_imgy[i] > opt[0]) opt[0] = h_img[i];
}
// get Min
cudaGetMin<<<grid_size+1, block_size>>>(d_img, d_imgy, N);
cudaMemcpy(h_imgy, d_imgy, sizeof(double) * (grid_size+1), cudaMemcpyDeviceToHost);
opt[1] = h_imgy[0];
for(int i = 0; i < grid_size+1; i++) {
if (h_imgy[i] < opt[1]) opt[1] = h_imgy[i];
}
......
一个CUDA流指的是由主机出发的在一个设备中执行的CUDA操作序列。来自于两个不同的CUDA流中的操作不一定按照某个次序执行,有可能并发或交错执行。任何CUDA操作都在CUDA流中。在本例中,我们的操作在默认的空流中执行。非默认的CUDA流在主机端产生与销毁,函数如下:
//定义CUDA流
cudaStream_t [变量];
//创建
cudaError_t cudaStreamCreate(cudaStream_t*);
//销毁
cudaError_t cudaStreamDestroy(cudaStream_t);
主机发布cuda流之后会立即获得程序控制权,这样才可以外部并行。
#include <iostream>
#include <stdio.h>
#include <opencv2/opencv.hpp>
#include <math.h>
#include <omp.h>
#include <ctime>
using namespace std;
using namespace cv;
__device__ __managed__ double opt[2] = {0, 0};// opt[0]: max, opt[1]: min
struct ComplexNum {
double real;
double imagin;
};
void flatten(double* h_img, Mat img, int w, int h) {
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++) {
h_img[i * w + j] = (double)img.at<uchar>(i, j);
}
}
}
void __global__ cudaGenerateMat(ComplexNum* dft_img, double* d_img, int h, int w, int N) {
int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n < N) {
double R = dft_img[n].real;
double I = dft_img[n].imagin;
double g = sqrt(R*R + I*I);
g = log(g+1);
d_img[n] = g;
}
}
void __global__ cudaTransscale(uchar* ucharimg, double* d_img, int h, int w, int N) {
int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n < N) {
if( ((int(n / w) < (h / 2))) && ((int(n % w) < (w / 2))))
ucharimg[n] = (uchar)((d_img[ (int(n / w) + h/2) * w + (int(n % w) + w / 2)] - opt[1]) * (255.0 / (opt[0] - opt[1])));
else if( ((int(n / w) < (h / 2))) && ((int(n % w) >= (w / 2))))
ucharimg[n] = (uchar)((d_img[ (int(n / w) + h/2) * w + (int(n % w) - w / 2)] - opt[1]) * (255.0 / (opt[0] - opt[1])));
else if( ((int(n / w) >= (h / 2))) && ((int(n % w) < (w / 2))))
ucharimg[n] = (uchar)((d_img[ (int(n / w) - h/2) * w + (int(n % w) + w / 2)] - opt[1]) * (255.0 / (opt[0] - opt[1])));
else if( ((int(n / w) >= (h / 2))) && ((int(n % w) >= (w / 2))))
ucharimg[n] = (uchar)((d_img[ (int(n / w) - h/2) * w + (int(n % w) - w / 2)] - opt[1]) * (255.0 / (opt[0] - opt[1])));
}
}
void resMat(double* d_img, Mat& out, int h, int w) {
for (int u = 0; u < h; u++) {
for (int v = 0; v < w; v++) {
out.at<uchar>(u, v) = (uchar)d_img[u * w + v];
}
}
}
void __global__ cudaresMat(double* d_img, uchar* ucharimg, int h, int w, int N) {
int n = blockDim.x * blockIdx.x + threadIdx.x;
ucharimg[n] = (uchar)d_img[n];
}
void __global__ cudadft2(double *d_img, ComplexNum *dft_img, const int N, int w, int h) {
int n = blockDim.x * blockIdx.x + threadIdx.x;
//int n = blockIdx.x + threadIdx.x * gridDim.x;
if (n < N) {
double real = 0.0;
double imagin = 0.0;
for (int i = 0; i < N; i++) {
double x = M_PI * 2 * ((double)(i / w) * (double)(n / w) / (double)w + (double)(i % w) * (double)(n % w) / (double)h);
double I = d_img[i];
real += cos(x) * I;
imagin += -sin(x) * I;
}
dft_img[n].real = real;
dft_img[n].imagin = imagin;
}
}
void __global__ cudaIdft2(double *d_img, ComplexNum *dft_img, const int N, int w, int h) {
int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n < N) {
double real = 0.0;
double imagin = 0.0;
for (int i = 0; i < N; i++) {
double R = dft_img[i].real;
double I = dft_img[i].imagin;
double x = M_PI * 2 * ((double)(n / w)*(i / w) / (double)w + (double)(n % w) * (i % w) / (double)h);
real += R * cos(x) - sin(x) * I;
imagin += I * cos(x) + R * sin(x);
}
double g = sqrt(real*real + imagin * imagin)*1.0 /(w * h);
d_img[n] = g;
}
}
void __global__ cudaGetMax(double *d_img, double *d_imgy, int N) {
int tid = threadIdx.x;
int bid = blockIdx.x;
int n = bid * blockDim.x + tid;
__shared__ double s_dimg[128];
s_dimg[tid] = (n < N) ? d_img[n] : 0.0;
__syncthreads();
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
if (tid < offset) {
if ( s_dimg[tid] < s_dimg[tid + offset])
s_dimg[tid] = s_dimg[tid + offset];
}
__syncthreads();
}
if (tid == 0) {
d_imgy[bid] = s_dimg[0];
}
}
void __global__ cudaGetMin(double *d_img, double *d_imgy, int N) {
int tid = threadIdx.x;
int bid = blockIdx.x;
int n = bid * blockDim.x + tid;
__shared__ double s_dimg[128];
s_dimg[tid] = (n < N) ? d_img[n] : 0.0;
__syncthreads();
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
if (tid < offset) {
if ( s_dimg[tid] > s_dimg[tid + offset])
s_dimg[tid] = s_dimg[tid + offset];
}
__syncthreads();
}
if (tid == 0) {
d_imgy[bid] = s_dimg[0];
}
}
int main(int argc, char* argv[]) {
if (argc < 2) {
cout << "Parameter is not enough, one parameter is missing." << endl;
return 0;
}
Mat img = imread(argv[1], 0);
int w = img.cols;
int h = img.rows;
// malloc host data
const int N = w * h;
const int M = sizeof(double) * N;
// host image
double *h_img = (double*) malloc(M);
//host Complex
ComplexNum *dft_img = (ComplexNum*)malloc(sizeof(ComplexNum) * N); //dft
flatten(h_img, img, w, h);
const int block_size = 128;
const int grid_size = N / 128;
//cuda image
double *d_img;
double *d_imgy;
double *h_imgy = (double*)malloc(sizeof(double) * (grid_size+1));
cudaMalloc((void **)&d_imgy, sizeof(double) * (grid_size+1));
// cuda dft image
ComplexNum *dft_cuda;
cudaMalloc((void **)&d_img, M);
cudaMalloc((void **)&dft_cuda, N * sizeof(ComplexNum));
// Transfer data to the device
cudaMemcpy(d_img, h_img, M, cudaMemcpyHostToDevice);
clock_t start_time, end_time;
start_time = clock();
cudadft2<<<grid_size+1, block_size>>>(d_img, dft_cuda, N, w, h);
end_time = clock();
cout << "DFT2 time: " << (double) (end_time - start_time) * 1000 / CLOCKS_PER_SEC << "ms" << endl;
// generate Mat
uchar *cudaucharimg;
cudaMalloc((void **)&cudaucharimg, sizeof(uchar)*N);
// generate the fourier spectrum
cudaGenerateMat<<<grid_size+1, block_size>>>(dft_cuda, d_img, h, w, N);
// get Max
cudaGetMax<<<grid_size+1, block_size>>>(d_img, d_imgy, N);
cudaMemcpy(h_imgy, d_imgy, sizeof(double) * (grid_size+1), cudaMemcpyDeviceToHost);
opt[0] = h_imgy[0];
for(int i = 1; i < grid_size+1; i++) {
if (h_imgy[i] > opt[0]) opt[0] = h_img[i];
}
// get Min
cudaGetMin<<<grid_size+1, block_size>>>(d_img, d_imgy, N);
cudaMemcpy(h_imgy, d_imgy, sizeof(double) * (grid_size+1), cudaMemcpyDeviceToHost);
opt[1] = h_imgy[0];
for(int i = 0; i < grid_size+1; i++) {
if (h_imgy[i] < opt[1]) opt[1] = h_imgy[i];
}
// save fourier spectrum
uchar* ucharimg = (uchar*)malloc(sizeof(uchar) * N);
cudaTransscale<<<grid_size+1, block_size>>>(cudaucharimg, d_img, h, w, N);
cudaMemcpy(ucharimg, cudaucharimg, sizeof(uchar) * N, cudaMemcpyDeviceToHost);
Mat rg = Mat(h, w, CV_8UC1, ucharimg);
imwrite("./cuda_p.jpg", rg);
// inverse fourier transform
start_time = clock();
cudaIdft2<<<grid_size+1, block_size>>>(d_img, dft_cuda, N, w, h);
end_time = clock();
cout << "IDFT2 time: " << (double) (end_time - start_time) * 1000 / CLOCKS_PER_SEC << "ms" << endl;
cudaresMat<<<grid_size+1, block_size>>>(d_img, cudaucharimg, h, w, N);
cudaMemcpy(ucharimg, cudaucharimg, sizeof(uchar) * N, cudaMemcpyDeviceToHost);
Mat res = Mat(h, w, CV_8UC1, ucharimg);
imwrite("res.jpg", res);
free(ucharimg);
free(h_imgy);
free(h_img);
free(dft_img);
cudaFree(d_imgy);
cudaFree(dft_cuda);
cudaFree(cudaucharimg);
cudaFree(d_img);
return 0;
}
学习了CUDA的线程组织与核函数的基本结构,CUDA的内存组织,和如何使用,加速效果理想。但还是太慢,还需学习与改进。
“我的NVIDIA开发者之旅” | 征文活动进行中...

当输入图片的宽高不一致时,为什么会有问题呀

当N很大很大时,核函数里还是有for循环会影响速度,这个循环还有办法并行吗?





写的很好,现在这种高质量的帖子不多见了

写的好哇

看完很有感触,写的很棒,继续加油!

在共享内存的那一部分,限定符应该是__shared__,本想加粗的。




