


332
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Curve 块存储已在生产环境上线使用近三年,经受住了各种异常和极端场景的考验,性能和稳定性均超出核心业务需求预期
网易云音乐背景
网易云音乐是中国领先的在线音乐平台之一,为音乐爱好者提供互动的内容社区。网易云音乐打造了一个大型、富有活力且坚固、快速成长的业态,为用户提供以社区为中心的在线音乐服务及社交娱乐服务。其标志性重点产品包括“网易云音乐”及附属的社交娱乐产品,如“LOOK 直播”、“声波”及“音街”,通过科技驱动的工具让音乐爱好者自主发掘、享受、分享并创作不同的音乐和音乐衍生内容,并与他人互动。
云音乐云盘业务背景
云音乐使用云盘的业务主要包括主站、UGC、曲库等 Java 应用,其中主站是云音乐核心业务,需要提供最高等级的 SLA 保障(年可用率>=99.99%),面对提供上亿级用户量稳定的云音乐体验,这一直以来也是我们的重难点。2019 年之前云音乐主要使用 Ceph 云盘,众所周知,Ceph 在大规模场景下存在性能缺陷,且很难保证我们在各种异常(坏盘慢盘、存储机宕机、存储网络拥塞等)场景下云盘 IO 响应时延不受影响;Ceph 云盘的 IO 抖动问题,我们曾尝试花很多人力精力做优化改造,但都只是稍微有所缓解,无法彻底解决;性能问题也投入大量人力进行分析优化,但仍然不能达到预期,因此我们才立项了解 Curve 块存储分布式存储系统。
Curve 块存储介绍
Curve 块存储可以良好适配主流云计算平台,并且具备高性能、易运维、稳定不抖动等优势。我们在实际应用中,使用 Curve 块存储对接 Cinder 作为云主机云盘存储后端,对接 Nova 作为云主机系统盘,对接 Glance 作为镜像存储后端。在创建云主机过程中,Nova 会通过 Curve 块存储提供的 Python SDK 克隆出新卷作为云主机系统盘使用。在创建云盘过程中,Cinder 会通过 Python SDK 创建空卷或者通过已有的卷快照克隆出新卷,之后可以挂载到云主机上作为云盘使用。云主机使用 Libvirt 作为虚拟化管控服务,使用 QEMU/KVM 作为虚拟化引擎。Curve 块存储为 Libvirt/QEMU 提供了驱动库,编译后就可以直接使用 Curve 卷作为远端存储,不需要把 Curve 块存储卷挂载到本地。
为什么选择 Curve
1. 业务侧
i. 根据我们云音乐应用场景,Ceph 云盘主要存在二大痛点:
ii. Curve 云盘优势:
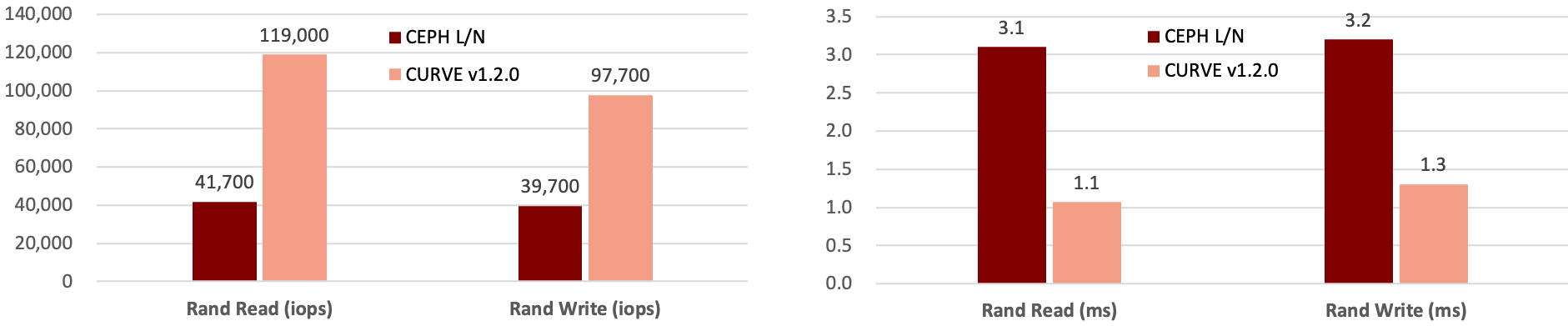
2. 运维侧
i. 根据我们云音乐运维场景,Ceph 的痛点主要有如下:
ii. 相对来说 Curve 在上述几个方面具备显著优势:
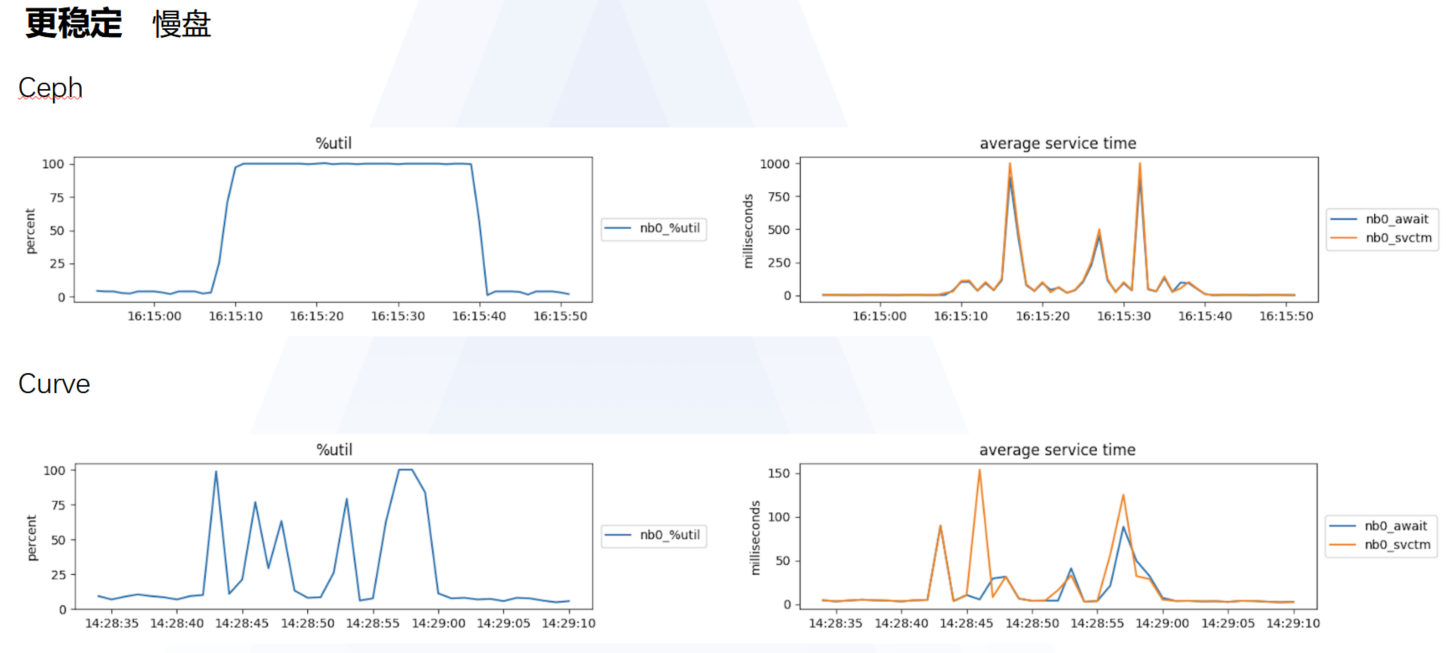

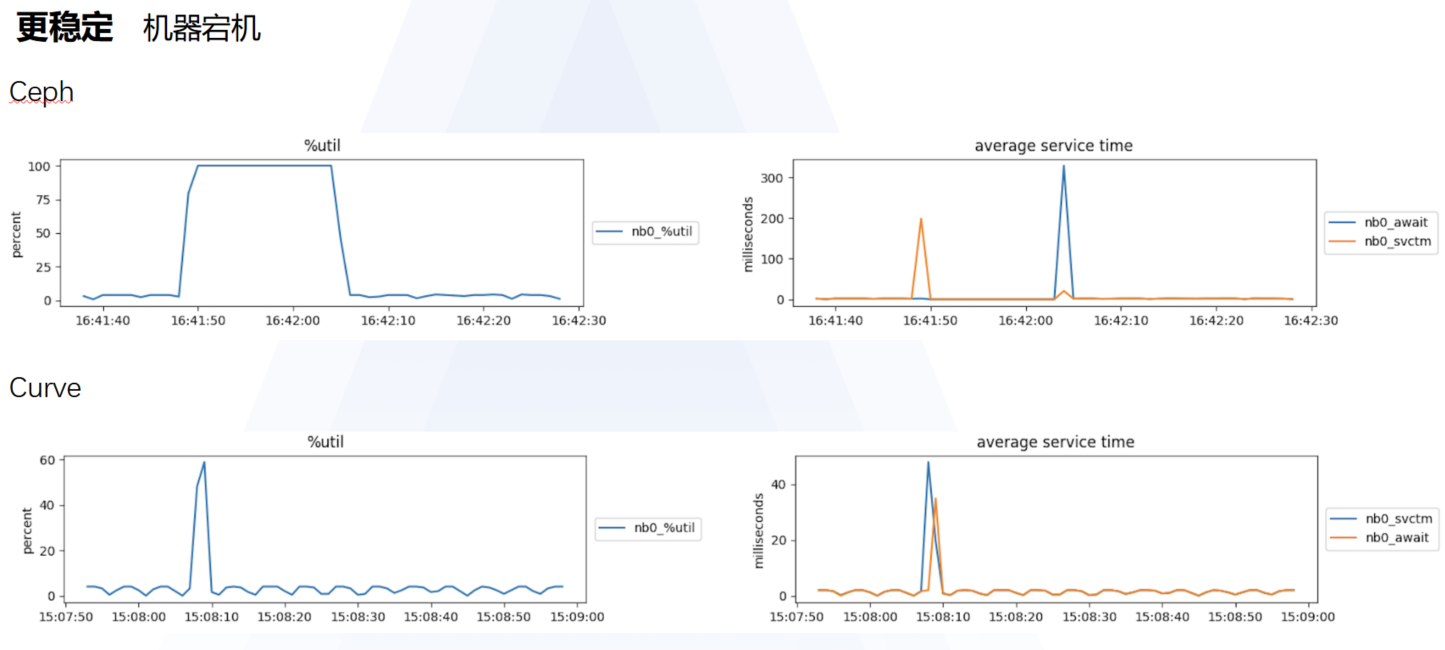
使用 Curve 落地成果
Curve 块存储已在生产环境上线使用近三年,经受住了各种异常和极端场景的考验,性能和稳定性均超出核心业务需求预期,常见故障场景下未产生明显 IO 抖动,服务端及客户端版本升级也未影响业务正常运行,这充分证明我们当时的选择是正确的,另外还要感谢 Curve 团队的同学在我们使用的过程中给予的帮助。目前:云音乐使用 Curve 块存储作为云主机的云盘和系统盘,其中系统盘通常为固定容量 40GB 或 60GB 两种规格,云盘容量最小 50GB,最大支持 4TB(此为软性限制,Curve 云盘实际支持创建 PB 级卷)。
后续规划
结合 Curve 块存储方面:
目前 Curve 团队也在全力开发共享文件存储服务,网易内部基于 OpenStack 的私有云 2.0 平台已经逐渐演进到基于 Kubernetes 的 3.0 平台,业务对于 ReadWriteMany 的类型的 PVC 卷的需求已经越来越迫切,Curve 团队开发了 Curve 分布式共享文件系统,该系统支持将数据存储到 Curve 块存储后端或者兼容 S3 协议的对象存储服务,后续也将尽快上线使用。
参考:
① https://github.com/opencurve/curve/blob/master/docs/cn/nebd.md
