


46
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享注:本文系原创,亦发表于作者微信公众号,转载请注明出处。
上一篇文章《如何用Go语言快速方便操作HBase2.0.x —— 基于github.com/pingcap/go-hbase的Hack实践》(以下简称“Hack实践”)中笔者介绍了如何改造go-hbase库以使得Go语言开发应用程序兼容访问2.x版本的HBase系统。
最近在项目实践中,笔者又遇到了新的需求——对HBase检索的数据列结果按条件进行过滤,类似SQL语言的WHERE条件子句功能。
HBase是支持对扫描(等同于SQL的SELECT)结果进行过滤的,以下是一个命令行终端的例子:
假设我们有一个HBase数据表,名称'demo_tab',一共10行,对应行键是'row_1' ... 'row_10',两列分别称作'info:val_1', 'info:val_2'。现在要选取所有 val_1值为aa的记录。
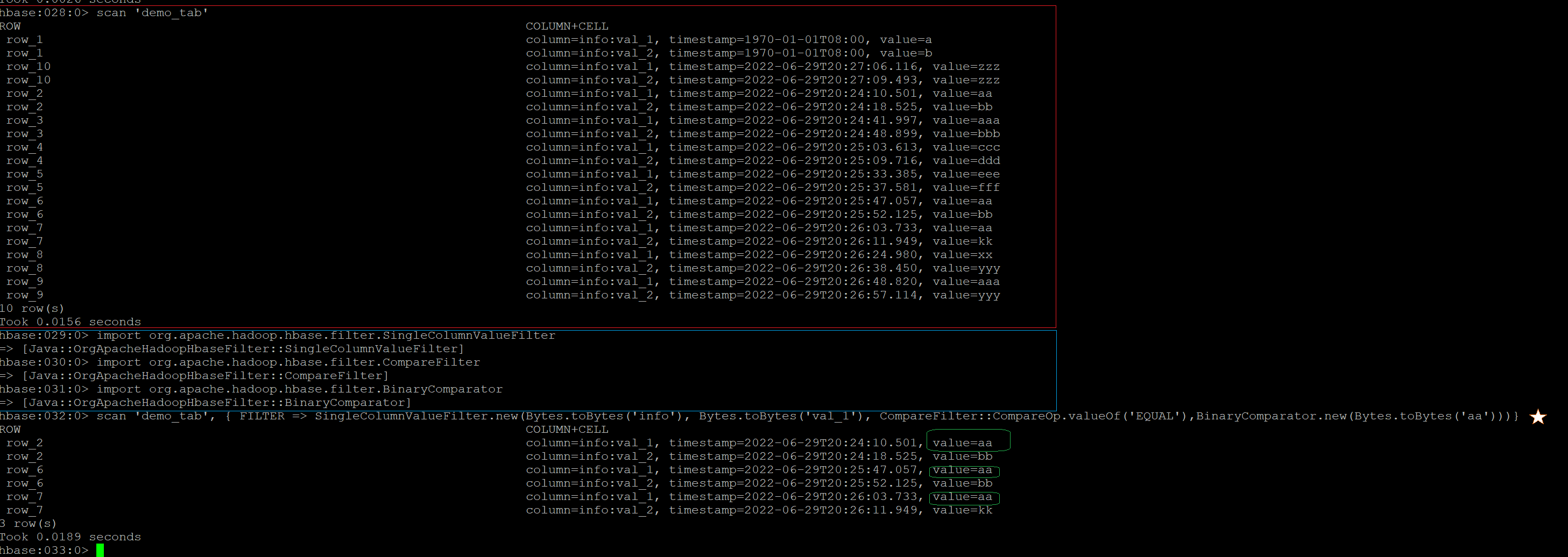
图1. HBase带有列过滤功能的数据扫描示例
由图1可见,红框是数据表中所有数据的记录,按照行键统计一共有10行。蓝色框部分是在执行前导入的组件,后文程序分析时候也会提到。星标的语句是带有列过滤的数据查询命令,具体目的是将'info:val_1'这一列等于'aa'的所有行输出。下面结果用绿色框标记了'info:val_1'这一列的值,可以看到结果符合命令行给出的条件。
本文就是介绍如何用Go语言开发一个程序,实现上述功能。继续用在《Hack实践》一文提到并修改的go-hbase包,在这个项目中,笔者发现go-hbase包提供的scan接口功能很简单,只有最直接的数据扫描,仅支持有限的几个参数,包括设定行键起止范围,时间区间范围等,并没有提供对扫描结果进行条件过滤的功能,也就是图1给出的列过滤功能无法直接实现。那么能否自己实现这个功能呢?在分析了这个程序包后,笔者发现有关列过滤等机制的协议部分已经包含在程序包中,只要适当改造程序接口就可以实现这个功能。下面笔者就介绍一下魔改go-hbase包实现列过滤查询的经验。
为方便起见,这里再次贴一下go-hbase程序包的代码树形结构。
|
├── action.go ├── action_test.go ├── admin.go ├── admin_test.go ├── call.go ├── client.go ├── client_ops.go ├── client_test.go ├── column.go ├── column_test.go ├── conn.go ├── del.go ├── del_test.go ├── get.go ├── get_test.go ├── iohelper │ ├── multireader.go │ ├── pbbuffer.go │ └── utils.go ├── LICENSE ├── proto │ ├── AccessControl.pb.go │ ├── Admin.pb.go │ ├── Aggregate.pb.go │ ├── Authentication.pb.go │ ├── Cell.pb.go │ ├── Client.pb.go │ ├── ClusterId.pb.go │ ├── ClusterStatus.pb.go │ ├── Comparator.pb.go │ ├── Encryption.pb.go │ ├── ErrorHandling.pb.go │ ├── Filter.pb.go │ ├── FS.pb.go │ ├── HBase.pb.go │ ├── HFile.pb.go │ ├── LoadBalancer.pb.go │ ├── MapReduce.pb.go │ ├── Master.pb.go │ ├── MultiRowMutation.pb.go │ ├── RegionServerStatus.pb.go │ ├── RowProcessor.pb.go │ ├── RPC.pb.go │ ├── SecureBulkLoad.pb.go │ ├── Snapshot.pb.go │ ├── Tracing.pb.go │ ├── VisibilityLabels.pb.go │ ├── WAL.pb.go │ └── ZooKeeper.pb.go ├── protobuf │ ├── AccessControl.proto │ ├── Admin.proto │ ├── Aggregate.proto │ ├── Authentication.proto │ ├── Cell.proto │ ├── Client.proto │ ├── ClusterId.proto │ ├── ClusterStatus.proto │ ├── Comparator.proto │ ├── Encryption.proto │ ├── ErrorHandling.proto │ ├── Filter.proto │ ├── FS.proto │ ├── HBase.proto │ ├── HFile.proto │ ├── LoadBalancer.proto │ ├── MapReduce.proto │ ├── Master.proto │ ├── MultiRowMutation.proto │ ├── RegionServerStatus.proto │ ├── RowProcessor.proto │ ├── RPC.proto │ ├── SecureBulkLoad.proto │ ├── Snapshot.proto │ ├── Tracing.proto │ ├── VisibilityLabels.proto │ ├── WAL.proto │ └── ZooKeeper.proto ├── put.go ├── put_test.go ├── README.md ├── result.go ├── result_test.go ├── scan.go ├── scan_test.go ├── service_call.go ├── types.go └── utils.go |
图2. 代码树形结构
首先开始研究的就是代码根目录下scan.go文件,从名字就可以猜测到这个是scan功能的实现的入口。这个接口工作的机制大致是:
对外开放的工作接口最重要的就是Next(),这里面实际触发了Scan操作。进一步挖掘,发现Next()方法内部调用的getData()方法才是核心, 顺便提到一点,Go语言中,程序包对外开放访问的方法或者数据变量都以大写首字母开头,小写的方法、数据和定义都仅仅包内可见。getData()代码片段由图3所示。
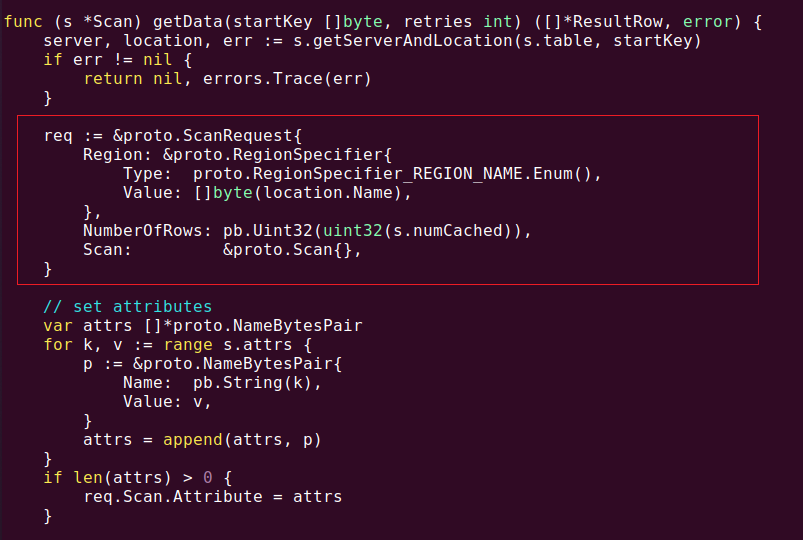
图3. getData() 方法代码片段
图3 红色方框标记出的部分看上去好像是与HBase交互的RPC协议部分,事实也是如此。到现在,整个scan.go文件中,还没有发现任何关于过滤器的内容。不过按图索骥,去查看RPC协议的实现,特别是proto.ScanRequest的定义,在proto/Client.pb.go中。
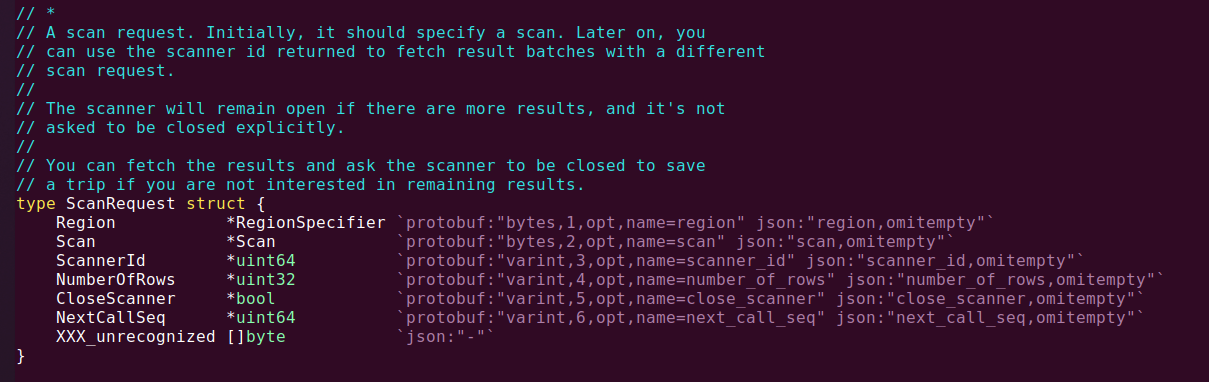
图4. ScanRequest数据结构
ScanRequest中有一个成员,叫做Scan,是一个指向proto.Scan结构的指针(见图4,在包内proto包名被省略),而且根据代码中的注解,这个结构明显要用于protobuf序列化与远程服务进行交互的。那么再看proto.Scan的定义(图5)。
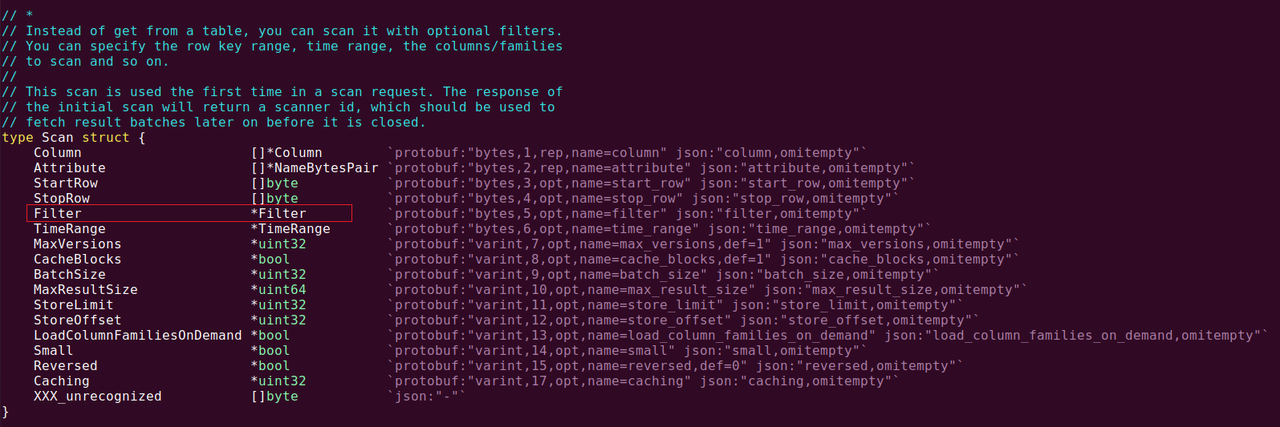
图5. proto.Scan数据结构
由图5可见,我用红色方框做了标记,这里赫然有一个 Filter成员。那么是不是我们要找的过滤器接口呢?按照线索,找到Filter定义,然后我把proto/Filter.go以及相关的proto/Comparator.go实现读过后,基本可以确定,这里就是过滤器的入口。而且,相关的过滤器使用协议部分都已经定义好,只要正确调用接口就可以了。
再回到图3,req := &proto.ScanRequest 这句赋值,就是连接外部请求和底层协议的桥梁,设定好一个过滤器,通过里面的 Scan: &proto.Scan{} 把过滤器传递给RPC,就可以实现想要的效果。
通过以上分析,就有了实现路径,只需要修改2处 代码:
1. 修改scan.go文件中,关于Scan结构体的定义,这个结构是开放给外部的接口,让用户将过滤器传递进来。图6 是scan.go中定义的Scan结构体修改前后代码对比,用红色框出。
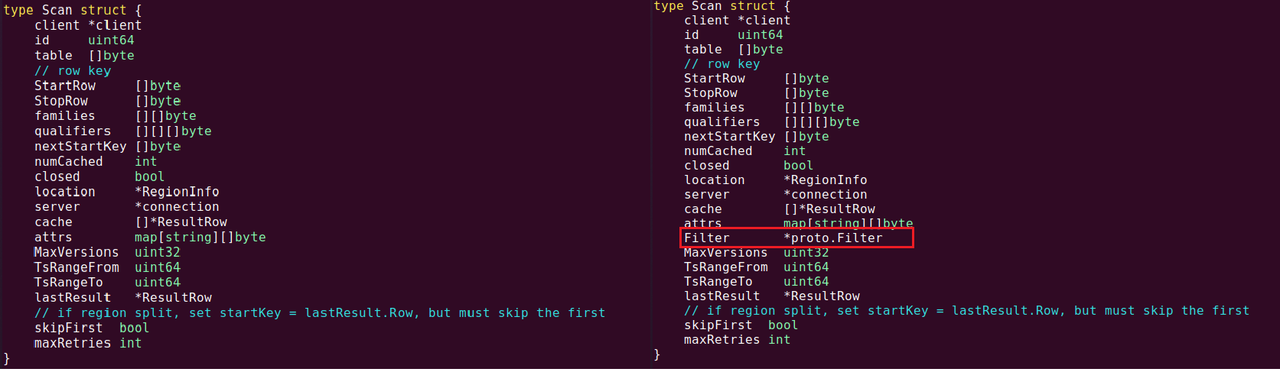
图6. Scan结构体修改前(左)和修改后(右)对比
2. 修改scan.go文件中,getData()方法内ScanRequest的赋值,将用户定义好的,在Scan结构体内部的过滤器传递给ScanRequest中的那个Scan指针,再通过底层协议机制把过滤器发送给HBase。图7 是修改后的getData()方法,可与图3对比。
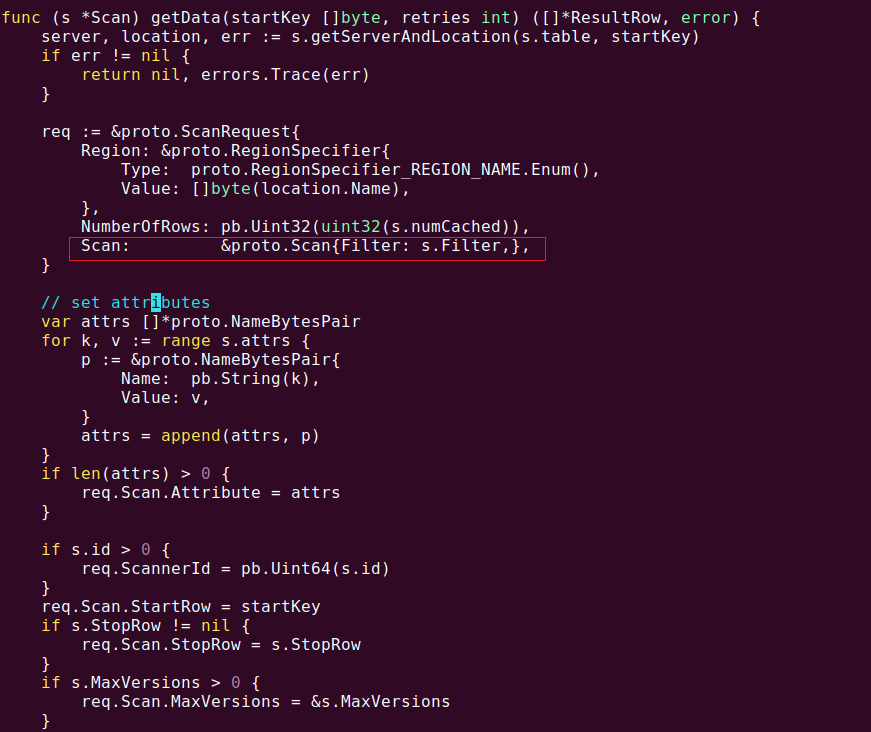
图7. 修改后的scan.go文件中getData()方法,修改用红框标出
至此,go-hbase程序包修改就已完成,看上去很简单,不过真正定位要修改的地方,还是要花一番功夫深入分析的。
按照笔者实践的经验,修改程序包只完成了工作一小部分,真正难点是如何正确使用它,在应用程序中将过滤器各个参数设置好,并正确序列化后传递给服务器端。为此,在这里给出两个例子,一个简单的完全对应图1应用的例子,用一个单列过滤器对数据进行等值判定过滤;另一个是复杂一些的例子,通过2个过滤器对2列数据进行联合过滤。通过这两个例子,用户可以在其上演变更复杂的应用。
这两个例子都在笔者工作环境中编译通过并正确运行,用户也可以将代码复制下来,搭建好一样的环境进行测试。
这里假设读者已经熟悉Go语言的语法,涉及编程语法细节不做过多介绍。proto.Comparator和proto.Filter是两个容器接口,可以认为是抽象的过滤器和比较器。根据具体实现,将实际设设置好的过滤器(这个例子中是SingleColumnValueFilter)和实际的比较器(例子中是BinarComparator)序列化后装入这两个容器,然后发出扫描请求。由于HBase中数据都是按照字节流存放的,没有数据类型概念,因此对于字符串数据,按照二进制字节串方式比较,这也是为什么例子中的比较接口用的ByteArrayComparable。另外,在Comparator和Fitler中,对应的实际比较器和过滤器的名字不要写错,要写全路径名。比如BinaryComparaotor要写成org.apache.hadoop.hbase.filter.BinaryComparator,我猜测服务器要根据传入的这个名称,找到具体的java组件包,也就是图1给出的例子中对应的import操作。这是一个非常容易出错的点,在实践中,笔者经过多方摸索,才知道这个名字正确设置方式。
package main
import (
"fmt"
"log"
hbase "github.com/pingcap/go-hbase" // 改造后的HBase程序包
pb "github.com/golang/protobuf/proto" // protobuf序列化工具
proto "github.com/pingcap/go-hbase/proto" // HBase程序包中的协议模块
)
func main() {
zkHosts := []string{"zk-node1:2181", "zk-node2:2181", "zk-node3:2181"} // zookeeper集群地址
dbCli, err := hbase.NewClient(zkHosts, "/hbase")
// 连接HBase
if err != nil {
log.Fatal("Failed to connect HBaser sever", err)
}
tblName, fmName, colName := "demo_tab", "info", "val_1" // 表名,列族,列名
filterVal := "aa" // 过滤值
myComparator := &proto.BinaryComparator{Comparable: &proto.ByteArrayComparable{Value: []byte(filterVal)}} // 实际的比较器,用于按照二进制字节比较 filterVal
srzComp, err1 := pb.Marshal(myComparator)
if err1 != nil {
log.Fatal("Failed to serialize myComparator ", err1)
}
valComparator := proto.Comparator{Name: pb.String("org.apache.hadoop.hbase.filter.BinaryComparator"), SerializedComparator: srzComp} // 序列化实际比较器,然后装入容器,注意名字
myFilter := &proto.SingleColumnValueFilter{
ColumnFamily: []byte(fmName), // 列族
ColumnQualifier: []byte(colName), // 列名
CompareOp: (*proto.CompareType)(pb.Int32(proto.CompareType_value["EQUAL"])),
Comparator: &valComparator, // 比较器
FilterIfMissing: pb.Bool(true),
LatestVersionOnly: pb.Bool(true),
} // 设置具体过滤器,这里比较操作使用 等于"EQUAL",其他操作参看go-hbase中代码
srzFilter, err2 := pb.Marshal(myFilter)
if err2 != nil {
log.Fatal("Failed to serialize myFilter", err2)
}
valFilter := &proto.Filter{Name: pb.String("org.apache.hadoop.hbase.filter.SingleColumnValueFilter"), SerializedFilter: srzFilter} // 序列化具体过滤器,然后转入容器Filter,注意过滤器名字
// 开始扫描并过滤数据
s := hbase.NewScan([]byte(tblName), 1000, dbCli) // 设置Scan
s.AddStringColumn(fmName, colName) // 添加列族和列名,这里只扫描1列,与图1扫全列略有不同
s.Filter = valFilter // 设定过去器,图6修改的接口
defer s.Close()
defer dbCli.Close()
for { // 输出扫描结果
res := s.Next()
if res == nil {
break
}
for col, kv := range res.Columns {
fmt.Println("row:", string(res.Row), "col: ", col, "val: ", string(kv.Value))
}
}
}
图8. 简单例子:单过滤器的应用
这个简单例子编译后运行,结果输入如图9所示,可见'info:val_1'这列值为aa的3行数据都被扫描输出。

图9. 单过滤器程序示例的输出结果
这节我们给出一个略微复杂的例子。按照'info:val_1' = 'aa' 且 'info:val_2' <> 'bb'的列输出,即val_1列等于'aa'并且'val_2列不等于'bb'的结果。这个预期输出应该是row_7,对应列值是'aa'和'kk'。
实现这个复杂例子,需要用到的是过滤器列表FilterList,其实就是在Filter容器之上,再加一层容器,将一个个Filter再序列化后装入到FilterList中,然后把FilterList再封一层Filter容器发送给服务器。具体实现见图10,理解代码可以自行阅读注释内容,这里不再进一步文字解释。为节省篇幅,复杂例子省去了错误处理,所有错误变量都略去不再处理。
package main
import (
"fmt"
"log"
hbase "github.com/pingcap/go-hbase"
pb "github.com/golang/protobuf/proto"
proto "github.com/pingcap/go-hbase/proto"
)
func main() {
zkHosts := []string{"zk-node1:2181", "zk-node2:2181", "zk-node3:2181"} // zookeeper集群地址
dbCli, _ := hbase.NewClient(zkHosts, "/hbase")
// 连接HBase
tblName, fmName, colName1, colName2 := "demo_tab", "info", "val_1", "val_2" // 两个列val_1, val_2
filterVal1, filterVal2 := "aa", "bb"
// 定义两个比较值,分别比较val_1, val_2的值,如果两列用同一个值比较,只需要定义一个
myComparator1 := &proto.BinaryComparator{Comparable: &proto.ByteArrayComparable{Value: []byte(filterVal1)}}
myComparator2 := &proto.BinaryComparator{Comparable: &proto.ByteArrayComparable{Value: []byte(filterVal2)}}
// 分别序列化
srzComp1, _ := pb.Marshal(myComparator1)
srzComp2, _ := pb.Marshal(myComparator2)
valComparator1 := proto.Comparator{Name: pb.String("org.apache.hadoop.hbase.filter.BinaryComparator"), SerializedComparator: srzComp1} // 比较器1
valComparator2 := proto.Comparator{Name: pb.String("org.apache.hadoop.hbase.filter.BinaryComparator"), SerializedComparator: srzComp2} // 比较器2
myFilter1 := &proto.SingleColumnValueFilter{
ColumnFamily: []byte(fmName),
ColumnQualifier: []byte(colName1),
CompareOp: (*proto.CompareType)(pb.Int32(proto.CompareType_value["EQUAL"])),
Comparator: &valComparator1,
FilterIfMissing: pb.Bool(true),
LatestVersionOnly: pb.Bool(true),
} // 过滤器1,使用“等于”条件
myFilter2 := &proto.SingleColumnValueFilter{
ColumnFamily: []byte(fmName),
ColumnQualifier: []byte(colName2),
CompareOp: (*proto.CompareType)(pb.Int32(proto.CompareType_value["NOT_EQUAL"])),
Comparator: &valComparator2,
FilterIfMissing: pb.Bool(true),
LatestVersionOnly: pb.Bool(true),
} // 过滤器2,使用“不等于”条件
srzFilter1, _ := pb.Marshal(myFilter1)
srzFilter2, _ := pb.Marshal(myFilter2)
valFilter1 := &proto.Filter{Name: pb.String("org.apache.hadoop.hbase.filter.SingleColumnValueFilter"), SerializedFilter: srzFilter1} // 装入Filter
valFilter2 := &proto.Filter{Name: pb.String("org.apache.hadoop.hbase.filter.SingleColumnValueFilter"), SerializedFilter: srzFilter2} // 装入Filter
filterList := &proto.FilterList{
Operator: (*proto.FilterList_Operator)(pb.Int32(proto.FilterList_Operator_value["MUST_PASS_ALL"])),
// 这里MUST_PASS_ALL 相当于AND,列表中过滤条件必须全部满足
Filters: []*proto.Filter{valFilter1, valFilter2},
} // 定义FitlerList
srzFilterList, _ := pb.Marshal(filterList) // 序列化
topFilter := &proto.Filter{Name: pb.String("org.apache.hadoop.hbase.filter.FilterList"), SerializedFilter: srzFilterList} // 将FilterList装入Filter,使用Filter统一接口传递给服务器,注意这里名称
s := hbase.NewScan([]byte(tblName), 1000, dbCli)
s.AddStringColumn(fmName, colName1) // 将val_1加入扫描
s.AddStringColumn(fmName, colName2)
// 将val_2加入扫描
s.Filter = topFilter
defer s.Close()
defer dbCli.Close()
for { // 输出结果
res := s.Next()
if res == nil {
break
}
for col, kv := range res.Columns {
fmt.Println("row:", string(res.Row), "col: ", col, "val: ", string(kv.Value))
}
}
}
图10. 复杂例子:多列多条件过滤
上面例子编译后运行,结果输入如图11所示,可见输出只有row_6这行,输出两列值分别是aa和kk,满足过滤条件。

图11. 多列多值过滤器输出结果
笔者结合项目经验,总结了如何通过修改go-hbase包,实现列过滤器的方法,并给了两个实际应用样例。经过实际测试,可以验证方案是有效的。随着使用深入,实践经验的逐步积累,笔者会将更多使用Go语言进行大数据开发的经验分享出来。

受益匪浅
