


1,405
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享虚拟助理已经成为我们日常生活的一部分。我们问虚拟助理几乎任何我们想知道的事情。除了为我们的日常生活提供便利之外,虚拟助手在企业应用程序方面也有巨大的帮助。例如,我们使用在线虚拟代理来帮助解决复杂的技术问题、提交保险索赔或预订酒店。我们还使用全自动呼叫来帮助扩展客户关系管理。所有这些应用程序都要求企业部署一个生产级、健壮、基于语音的虚拟助手,以扩展到数亿最终用户。
由于其自然性,语音界面已成为促进高质量人机界面的关键因素。然而,对于许多开发人员来说,基于语音的虚拟助理仍然是一个重大的技术挑战,尤其是在大规模部署时。
要成功部署基于语音的生产级虚拟助手,必须确保完全支持以下方面:
这篇文章的目的是让您了解两个生产级、企业级、虚拟助手解决方案: NVIDIA Riva 和 Rasa 的示例应用程序。我们展示了您可以轻松构建第一个基于语音的虚拟应用程序,这些应用程序可以部署和扩展。此外,我们还演示了 Riva 的性能,以展示其生产级功能。
视频 1 。虚拟助手的演示视频。
虚拟助手系统包括以下组件:
NLU 和 DM 组件来自 Rasa ,而 Riva 提供 TTS 和 ASR 功能。
Rasa 是一个开源的机器学习框架,用于构建基于文本和语音的 AI 助手。在最基本的层面上,助理必须能够做两件事:
Rasa 助理使用机器学习来完成这两项任务。 Rasa 允许您构建健壮的助手,从真实用户对话中学习,以大规模处理关键任务。
对于此虚拟助手,您可以使用 Rasa NLU 和 DM 功能。有关更多信息,请参阅 Rasa documentation 。
Riva 是用于构建会话式 AI 应用的英伟达 AI 语音 SDK 。 Riva 提供 ASR 和 TTS 功能,您可以使用这些功能来向虚拟助手提供语音接口。 Riva SDK 在 NVIDIA GPU 上运行,在高吞吐量水平下提供最快的推断时间。
对于这个虚拟助手, ASR 解决方案必须具有低延迟和高精度,同时能够支持高吞吐量。 TTS 必须具有低延迟和支持自定义语音字体。 Riva 提供了这两种字体,非常适合构建基于语音的虚拟助手。有关 Riva 性能的更多信息,请参阅 NVIDIA Riva Speech Skills 。
以下是四个组件如何交互以创建基于语音的虚拟助手。图 1 显示了虚拟助手的体系结构。
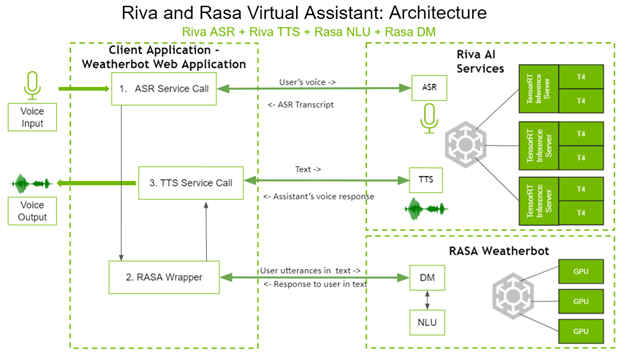 图 1 . Riva 和具有 Rasa NLU 体系结构的 Rasa 虚拟助手。
图 1 . Riva 和具有 Rasa NLU 体系结构的 Rasa 虚拟助手。
在左侧,客户端应用程序是 weatherbot web 应用程序。用户通过语音直接与客户端应用程序交互,并通过扬声器接收答案。
用户所说的问题通过调用 Riva ASR 服务进行转录。这个转录的文本将被发送到 Rasa 包装器,该包装器反过来对 Rasa DM 和 Rasa NLU 进行 API 调用,以决定适当的下一个操作。根据选择的下一个操作, Rasa DM 还可以在需要时处理实现。 Rasa 服务器的文本响应通过 gRPC 调用发送到 Riva TTS 服务器, gRPC 调用将相应的音频返回给用户。
如您所见, Riva AI 服务和 Rasa 都部署在具有 GPU 的系统上,以获得更好的性能。
在这篇文章中,我们将引导您完成为天气领域构建虚拟助手的过程。本文的重点不是用 Rasa NLU 和 DM 构建聊天机器人,而是展示 Rasa NLU 和 Rasa DM 与 Riva ASR 和 TTS 的集成,以构建基于语音的虚拟助手。
虚拟助手需要一个用户界面,因此您可以使用 Python 的 Flask 框架创建一个简单的网站。
有关此解决方案的更多信息以及代码,请参阅 Riva documentation 中的 Virtual Assistant (with Rasa) section 。
要使虚拟助手正常工作,必须启动并运行 Riva 服务器。要使 Riva AI 服务启动、运行并可通过 gRPC 端点访问,请遵循 Riva Quick Start Guide 中的说明。
在本节中,将 Riva ASR 与 Rasa 助手集成,如 ASR . py 文件中所示。
Riva ASR 可在流式或批处理模式下使用。在流模式下,捕获并识别连续的音频流,生成转录文本流。在批处理模式下,设置长度的音频剪辑被转录为文本。对于这个用例,在流模式下使用 Riva ASR 。
代码概述
import grpc import riva.modules.client.src.riva_proto.audio_pb2 as ri import riva.modules.client.src.riva_proto.riva_asr_pb2 as risr import riva.modules.client.src.riva_proto.riva_asr_pb2_grpc as risr_srv
首先导入必要的 Riva 客户端依赖项:
class ASRPipe(object): def __init__(self): . . . . self.chunk = int(self.sampling_rate / 10) # 100ms self._buff = queue.Queue() self._transcript = queue.Queue() self.closed = False
创建 ASRPipe 类来处理 Riva ASR 操作。在 __init__ 方法中,分别为音频流和转录文本流创建 _buff 和 _transcript 队列。
def start(self): . . . . self.channel = grpc.insecure_channel(riva_config["RIVA_SPEECH_API_URL"]) self.asr_client = risr_srv.RivaSpeechRecognitionStub(self.channel)
调用 start 函数以建立到 Riva 服务器的 gRPC 通道。
def fill_buffer(self, in_data): """Continuously collect data from the audio stream, into the buffer.""" self._buff.put(in_data)
虚拟助手中的 ASR 是一个后台过程,因为您始终需要网站收听用户音频。通过调用 fill_buffer 函数,音频流中的音频将连续添加到音频缓冲区 _buff 。
def main_asr(self): . . . . config = risr.RecognitionConfig( encoding=ri.AudioEncoding.LINEAR_PCM, sample_rate_hertz=self.sampling_rate, language_code=self.language_code, max_alternatives=1, enable_automatic_punctuation=self.enable_automatic_punctuation ) streaming_config = risr.StreamingRecognitionConfig( config=config, interim_results=self.stream_interim_results) if self.verbose: print("[Riva ASR] Starting Background ASR process") self.request_generator = self.build_request_generator() requests = (risr.StreamingRecognizeRequest(audio_content=content) for content in self.request_generator) def build_generator(cfg, gen): yield risr.StreamingRecognizeRequest(streaming_config=cfg) for x in gen: yield x yield cfg if self.verbose: print("[Riva ASR] StreamingRecognize Start") responses = self.asr_client.StreamingRecognize(build_generator( streaming_config, requests)) # Now, put the transcription responses to use. self.listen_print_loop(responses)
获得音频后,使用 main_asr 函数生成转录本。
在 main_asr 函数中,设置 Riva ASR 调用所需的配置参数,如语言、通道数、音频编码、采样率等。 main_asr 函数随后定义了 build_generator 函数:一个生成器,用于使用音频剪辑和 ASR 配置迭代调用 Riva ASR StreamingRecognizeRequest 函数。最后, main_asr 调用 Riva ASR StreamingRecognize 函数。该函数返回一个文本转录本流,其中包含指示中间和最终转录本的标志,然后返回给调用方。
在本节中,您将 Riva TTS 与 Rasa 助手集成,如 tts.py 和 tts_stream.py 文件中所示。
与 ASR 一样, TTS 也可以在流式或批处理模式下使用。使用 tts.py 中的批处理模式,可以将文本作为输入并生成音频剪辑。使用 tts_stream.py 中的流模式,可以将文本作为输入并生成音频流。
代码概述
import grpc import riva.modules.client.src.riva_proto.audio_pb2 as ri import riva.modules.client.src.riva_proto.riva_tts_pb2 as rtts import riva.modules.client.src.riva_proto.riva_tts_pb2_grpc as rtts_srv from riva.tts.tts_processing.main_pronunciation import RunPronunciation
首先导入必要的 Riva 客户端依赖项。
class TTSPipe(object): def __init__(self): . . . . self._buff = queue.Queue() self._flusher = bytes(np.zeros(dtype=np.int16, shape=(self.sample_rate, 1))) # Silence audio self.pronounce = RunPronunciation(pronounce_dict_path)
创建 TTSPipe 类来处理 Riva TTS 操作。在 __init__ 方法中,创建 _buff 队列以保存输入文本。
def start(self): . . . . self.channel = grpc.insecure_channel( riva_config["Riva_SPEECH_API_URL"]) self.tts_client = rtts_srv.RivaSpeechSynthesisStub(self.channel)
调用 start 函数以建立到 Riva 服务器的 gRPC 通道。
def fill_buffer(self, in_data): """To collect text responses and fill TTS buffer.""" if len(in_data): self._buff.put(in_data)
要转换为音频的文本通过调用 fill_buffer 方法添加到缓冲区 _buff 。
def get_speech(self): . . . . while not self.closed: if not self._buff.empty(): # Enter if queue/buffer is not empty. try: text = self._buff.get(block=False, timeout=0) req = rtts.SynthesizeSpeechRequest() req.text = self.pronounce.get_text(text) req.language_code = self.language_code req.encoding = self.audio_encoding req.sample_rate_hz = self.sample_rate req.voice_name = self.voice_name duration = 0 self.current_tts_duration = 0 responses = self.tts_client.SynthesizeOnline(req) for resp in responses: datalen = len(resp.audio) // 4 data32 = np.ndarray(buffer=resp.audio, dtype=np.float32, shape=(datalen, 1)) data16 = np.int16(data32 * 23173.26) speech = bytes(data16.data) duration += len(data16)*2/(self.sample_rate*1*16/8) self.current_tts_duration += duration yield speech except Exception as e: print('[Riva TTS] ERROR:', e) . . . .
get_speech 方法用于执行 TTS 。
在 get_speech 方法中,设置 Riva TTS 调用所需的配置参数,如语言、音频编码、采样率和语音名称。然后 get_speech 方法调用 Riva TTS SynthesizeOnline 方法,将文本作为输入,并返回生成的音频流。循环此响应并以可配置的持续时间产生音频输出块,从而产生流式音频输出。
现在,您将使用 rasa.py 文件调用 NLU 和 DM 的 Rasa 服务器。
class RASAPipe(object): def __init__(self, user_conversation_index): . . . . self.user_conversation_index = user_conversation_index
创建 RASAPipe 类以处理对 NLU 和 DM 的 Rasa 服务器的所有调用。
def request_rasa_for_question(self, message): rasa_requestdata = {"message": message, "sender": self.user_conversation_index} x = requests.post(self.messages_url, json = rasa_requestdata) rasa_response = x.json() processed_rasa_response = self.process_rasa_response(rasa_response) return processed_rasa_response
此类的主要函数是 request_rasa_for_question 方法,它将用户输入作为文本,使用此文本和公开的 Rasa API 上的发送方 ID 调用 Rasa ,从 Rasa 获取响应,然后将此响应返回给调用方。
接下来,创建推断管道,如 chatbot.py 文件所述。
class ChatBot(object): def __init__(self, user_conversation_index, verbose=False): self.id = user_conversation_index self.asr = ASRPipe() self.rasa = RASAPipe(user_conversation_index) self.tts = TTSPipe() self.thread_asr = None self.pause_asr_flag = False self.enableTTS = False
在 chatbot.py 中,有 ChatBot 类。每个会话有一个 ChatBot 实例,负责处理该会话的所有 ASR 、 TTS 和 Rasa 操作。创建 ChatBot 类的实例时,您将在其初始化期间创建 ASR 、 Rasa 和 TTS 类的实例。
def server_asr(self): self.asr.main_asr() def start_asr(self, sio): self.thread_asr = sio.start_background_task(self.server_asr)
首先调用 start_asr 方法,该方法负责在单独的专用线程中作为后台进程启动 ASR 操作。
def asr_fill_buffer(self, audio_in): if not self.pause_asr_flag: self.asr.fill_buffer(audio_in) def get_asr_transcript(self): return self.asr.get_transcript()
然后, asr_fill_buffer 函数调用 ASRPipe 实例 fill_buffer 函数,将来自用户的输入音频流添加到 ASR 缓冲区。当 Riva ASR 开始将转录文本流式传输回来时, get_asr_transcript 函数被调用,将转录文本返回给调用者。
def rasa_tts_pipeline(self, text): response_text = self.rasa.request_rasa_for_question(text) if len(response_text) and self.enableTTS == True: self.tts_fill_buffer(response_text) return response_text
对于转录的文本,调用 rasa_tts_pipeline 方法,负责管道化 Rasa 和 Riva TTS 功能。该方法首先调用 R ASAP ipe 实例 request_rasa_for_question 方法。这会将用户输入文本发送到 Rasa ,其中 Rasa NLP 和 Rasa DM 确定适当的操作并以文本消息的形式返回回复。然后将此文本消息传递给 tts_fill_buffer 并返回给调用者。
def tts_fill_buffer(self, response_text): if self.enableTTS: self.tts.fill_buffer(response_text) def get_tts_speech(self): return self.tts.get_speech()
前面调用的 tts_fill_buffer 依次调用 TTSPipe 实例 fill_buffer 方法,用输入文本填充 TTS 缓冲区。当 TTS 准备好音频流时,调用 get_tts_speech 方法,并将此音频流回到调用者。
如您所见,您已经将 Rasa 和 TTS 功能管道化为一个简单的方法 rasa_tts_pipeline 。
在启动 virtual assistant 服务器之前,必须按照 Network Configuration 部分中的说明正确配置 API 端点。
要启动基于语音的虚拟助手,请按照 Running the Demo 部分中的说明操作。
在执行上述步骤的同时,初始化 Rasa 操作服务器和 Rasa 服务器的各个容器。这一过程漫长而繁琐。有关更简单方法的更多信息,请参阅 Rasa 的 Docker Compose Installation 。
您可以通过两个关键方法提高上述基于语音的虚拟助手的准确性。
对话驱动开发( CDD )是倾听用户意见并利用这些见解改进 AI 助手的过程。开发优秀的人工智能助手是一项挑战,因为用户会说出你无法预料的事情。然而,机会在于,在每次对话中,用户都会准确地告诉你他们想要什么。通过在对话 AI 开发的每个阶段练习 CDD ,您可以让您的助手从真实的用户语言和行为中学习。
Rasa X 是一种实践 CDD 的工具。以下是使用 Rasa X 的 CDD 中的每个步骤:
CDD 不是一个线性过程。你会发现自己在每一个动作之间来回跳跃。这是一个产品、设计和开发之间的协作过程,揭示了用户的需求。随着时间的推移,它可以确保您的助手适应用户的需求,而不是期望用户调整他们的行为,这样助手就不会崩溃。有关更多信息,请参阅 Rasa X Installation Guide 。
在许多情况下,您必须针对特定用例培训、调整和优化模型。定制模型的最重要的方法是提高准确性,它是在预训练的 Riva 模型中使用自定义数据和英伟达 TAO 工具包进行传输学习。
NVIDIA TAO Toolkit 是一个人工智能模型自适应框架,使您能够使用自定义数据微调预训练模型,而无需大型训练数据集或深入的人工智能专业知识。 TAO 工具包支持对话 AI 管道所需的各种模型,从语音识别和自然语言理解到文本到语音。
TAO 工具包最重要的区别在于,它借助预定义的 Python 脚本抽象出 AI / DL 框架的复杂性。用户在专用的预制 Docker 容器中执行所有操作。脚本以清晰的层次结构组织,遵循与支持的模型相关联的域和特定于域的任务。对于每个模型,工具箱组织用户应该遵循的操作顺序,从数据准备、培训和模型微调到导出进行推理。
有关更多信息,请参阅 TAO Toolki t documentation 。
在本文中,您构建了一个基于语音的虚拟助手,并了解了如何将 Riva ASR 和 TTS 与 Rasa NLP 和 DM 集成。您还了解了英伟达 Riva SDK 以及如何 Riva ASR 和 TTS 工作。
Riva documentation 中有更多的示例 notebooks 和 applications ,我们鼓励您尝试。加入 Riva forum 以连接 Riva 社区。了解有关 Rasa 的更多信息,并加入 Rasa forum 以了解其他人正在构建什么!



