


571
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享非常高兴这学期选了孟宁老师的高级软件工程。就我个人而言,收获最大的是前面几节有关工具介绍的课,特别是那个打字网站真的是非常实用,我跟着练习从45WPM左右进步到了70WPM,打字速度真的是暴涨。
顺便也给大伙推荐一个打字练习网站: https://play.typeracer.com/

在这里你可以和其他一样闲得蛋疼的玩家比赛谁的打字速度更快.
Typing
打字练习网站: https://www.typingclub.com/sportal/program-3/8832.play
测评标准:准确率100%,速度大于50WPM(优秀)>30WPM(及格)
Visual Studio Code
常用命令:
|
打开文件夹 |
ctrl+k ctrl+o |
|
关闭文件夹 |
ctrl+k f |
|
新建文件 |
ctrl+n |
|
关闭文件 |
ctrl+w |
|
保存文件 |
ctrl+s |
|
文件内搜索 |
ctrl+f |
|
关闭所有文件 |
ctrl+k w |
|
单行注释/取消注释 |
ctrl+/ |
|
代码块注释/取消注释 |
ctrl+shift+/ |
VsCode如何满足五花八门的需求
进程隔离的插件模型
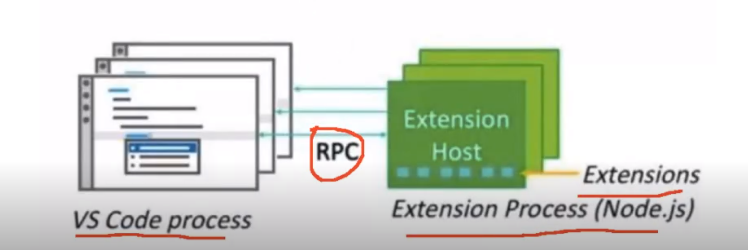
插件出问题不会干扰主进程的执行,保证了稳定性
用于代码理解和调试的第三方插件与VsCode主进程之间的桥梁
LSP: Language Server Protocol
DAP:Debug Adapter Protocol
Git
sudo apt install git # 在Linux上安装git
git clone https://github.com/YOUR_NAME/REPO_NAME.git # 通过clone远端的版本库从而在本地创建一个版本库
git init # 初始化一个本地版本库
git status # 查看当前工作区(workspace)的状态
git add [FILES] # 把文件添加到暂存区(Index)
git commit -m "wrote a commit log infro” # 把暂存区里的文件提交到仓库
git log # 查看当前HEAD之前的提交记录,便于回到过
git reset —hard HEAD^^/HEAD~100/commit-id/commit-id的头几个字符 # 回退
git reflog # 可以查看当前HEAD之后的提交记录,便于回到未来
git reset —hard commit-id/commit-id的头几个字符 # 回退
团队项目中的分叉合并
一、克隆或同步最新的代码到本地存储
git clone https://DOMAIN_NAME/YOUR_NAME/REPO_NAME.git
git pull
二、为自己的工作创建一个分支,该分支应该只负责单一功能模块或代码模块的版本控制;
git checkout -b mybranch
git branch
三、在该分支上完成某单一功能模块或代码模块的开发工作;多次进行如下操作:
git add FILES
git commit -m "commit log"
四、最后,先切换回master分支,将远程origin/master同步最新到本地存储库,再合并mybranch到master分支,推送到远程origin/master之后即完成了一项开发工作。
git checkout master
git pull
git merge --no-ff mybranch
git push
Vim
vim是从vi发展出来的一个文本编辑器。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。
在VSCode中Ctrl/⌘+Shift+X管理扩展插件中搜索vim即可安装使用
vim的三种模式
命令模式(Command mode),用户刚刚启动vi/vim,便进入了命令模式。此状态下敲击键盘动作会被vim识别为命令,而非输入字符。比如我们此时按下i,并不会输入一个字符,i被当作了一个命令。命令模式只有一些最基本的命令,因此仍要依靠底线命令模式输入更多命令
输入模式(Insert mode),在命令模式下按下i就进入了输入模式,按ESC退出输入模式,切换到命令模式。
底线命令模式(Last line mode),在命令模式下按下:(英文冒号)就进入了底线命令模式。底线命令模式可以输入单个或多个字符的命令,可用的命令非常多。基本的命令有q(退出程序)、w(保存文件)等。按ESC键可随时退出底线命令模式。
移动光标
|
h 或 向左箭头键(←) |
光标向左移动一个字符 |
|
l 或 向右箭头键(→) |
光标向右移动一个字符 |
|
j 或 向下箭头键(↓) |
光标向下移动一个字符 |
|
k 或 向上箭头键(↑) |
光标向上移动一个字符 |
|
gg |
移动到这个档案的第一行 |
|
G |
移动到这个档案的最后一行 |
|
n<Enter> |
n为数字,光标向下移动n行 |
删除
|
x, X |
在一行字当中,x 为向后删除一个字符 (相当于 [del] 按键), X 为向前删除一个字符(相当于 [backspace] 亦即是退格键) |
|
nx |
n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『10x』。 |
|
dd |
删除游标所在的那一整行 |
|
ndd |
n 为数字。删除光标所在的向下 n 行,例如 20dd 则是删除 20 行 |
复制粘贴
|
yy |
复制游标所在的那一行 |
|
p, P |
p为将已复制的数据在光标下一行贴上,P则为贴在游标上一行 |
|
nyy |
n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行 |
复原和重做(常用)
|
u |
复原前一个动作。 |
|
[Ctrl]+r |
重做上一个动作。 |
基本搜索
|
/word |
向光标之下寻找一个名称为 word 的字符串。 |
|
?word |
向光标之上寻找一个字符串名称为 word 的字符串。 |
|
n |
重复前一个搜寻的动作。 |
|
N |
反向进行前一个搜寻动作。 |
基本搜索替换
|
:n1,n2s/word1/word2/g |
n1 与 n2 为数字。在第 n1 与 n2 行之间寻找 word1 这个字符串,并将该字符串取代为 word2 |
|
s是substitute的简写,表示执行替换字符串操作g(global)表示全局替换; |
c(comfirm)表示操作时需要确认;i(ignorecase)表示不区分大小写 |
|
:1,$s/word1/word2/g 或:%s/word1/word2/g |
从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 ! |
|
:1,$s/word1/word2/gc 或 :%s/word1/word2/gc |
从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !且在取代前显示提示字符给用户确认 (confirm) 是否需要取代! |
切换到编辑模式
|
i, I 进入输入模式(Insert mode): |
i 为『从目前光标所在处输入』, I 为『在目前所在行的第一个非空格符处开始输入』。 |
|
a, A 进入输入模式(Insert mode): |
a 为『从目前光标所在的下一个字符处开始输入』, A 为『从光标所在行的最后一个字符处开始输入』。 |
|
o, O 进入输入模式(Insert mode): |
这是英文字母 o 的大小写。o 为『在目前光标所在的下一行处输入新的一行』; O 为在目前光标所在处的上一行输入新的一行! |
|
r, R 进入取代模式(Replace mode): |
r 只会取代光标所在的那一个字符一次;R会一直取代光标所在的文字,直到按下 ESC 为止; |
|
[Esc] 退出编辑模式,回到一般模式中(常用) |
编辑模式在vi画面的左下角处会出现『--INSERT--』或『--REPLACE--』的字样 |
命令行模式
|
:w |
将编辑的数据写入硬盘档案中 |
|
:q |
离开 vi |
|
:wq |
储存后离开,若为 :wq! 则为强制储存后离开 |
代码中批量添加注释
批量注释:Ctrl + v 进入块选择模式,然后移动光标选中你要注释的行(VSCode可以鼠标选择代码块),再按大写的 I 进入行首插入模式输入注释符号如 // 或 #,输入完毕之后,按两下 ESC,Vim 会自动将你选中的所有行首都加上注释,保存退出完成注释。
取消注释:Ctrl + v 进入块选择模式,选中你要删除的行首的注释符号,注意 // 要选中两个,选好之后按 d 即可删除注释,ESC 保存退出。
批量注释:使用下面命令在指定的行首添加注释。使用命令格式: :起始行号,结束行号s/^/注释符/g(注意冒号),如:10,20s#^#//#g,:10,20s/^/#/g
取消注释:使用名命令格式: :起始行号,结束行号s/^注释符//g(注意冒号),如:10,20s#^//##g,:10,20s/#//g
命令行环境下vim的配置
|
:set nu |
显示行号,设定之后,会在每一行的前缀显示该行的行号 |
|
:set nonu |
与 set nu 相反,为取消行号! |
正则表达式十步通关
正则表达式 -- 对字符串操作的一种逻辑公式
字符串搜索:
参考: https://blog.csdn.net/lxcnn/article/details/4146148
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。当然,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部。
捕获组有两种形式,一种是普通捕获组,另一种是命名捕获组,通常所说的捕获组指的是普通捕获组。

1. 通过控制结构简化代码(if else/while/switch)
2. 通过数据结构简化代码
3. 一定要有错误处理
4. 注意性能优先的代价
5. 拒绝修修补补要不断重构代码
模块化软件设计
基本原理
模块化(Modularity)是在软件系统设计时保持系统内各部分相对独立,以便每一个部分可以被独立地进行设计和开发。这个做法背后的基本原理是关注点的分离 (SoC, Separation of Concerns) 分解成易解决的小问题,降低思考负担。
每个模块只有一个功能,易于开发,并且bug会集中在少数几个模块内,容易定位软件缺陷,也更加容易维护。
软件设计中的模块化程度便成为了软件设计有多好的一个重要指标,一般我们使用耦合度(Coupling)和内聚度(Cohesion)来衡量软件模块化的程度。
内聚度是指一个软件模块内部各种元素之间互相依赖的紧密程度。 理想的内聚是功能内聚,也就是一个软件模块只做一件事,只完成一个主要功能点或者一个软件特性(Feather)。
基本方法
KISS(keep it simple&stupid)原则
一行代码只做一件事
一个块代码只做一件事
一个函数只做一件事
一个软件模块只做一件事
基本概念
接口就是互相联系的双方共同遵守的一种协议规范,在我们软件系统内部一般的接口方式是通过定义一组API函数来约定软件模块之间的沟通方式。
在面向过程的编程中,接口一般定义了数据结构及操作这些数据结构的函数;而在面向对象的编程中,接口是对象对外开放(public)的一组属性和方法的集合。函数或方法具体包括名称、参数和返回值等。
基本要素
1. 接口的目的
2. 接口的前置条件
3. 接口的协议规范(如http协议,png图片格式,json数据格式定义etc..)
4. 接口的后置条件
5. 接口的质量属性(如响应时间)
RESTful API
GET用来获取资源;
POST用来新建资源(也可以用于更新资源);
PUT用来更新资源;
DELETE用来删除资源。
耦合方式
1. 公共耦合
当软件模块之间 共享数据区 或 变量名 的软件模块之间即是公共耦合,显然两个软件模块之间的接口定义不是通过显式的调用方式,而是 隐式 的共享了共享了数据区或变量名。
2. 数据耦合
在软件模块之间仅通过显式的调用传递 基本数据类型 即为数据耦合。
3. 标记耦合
在软件模块之间仅通过显式的调用传递复杂的数据结构(结构化数据)即为标记耦合,这时数据的结构成为调用双方软件模块隐含的规格约定,因此耦合度要比数据耦合高。但相比公共耦合没有经过显式的调用传递数据的方式耦合度要低。
通用接口定义的基本方法
1. 参数化上下文(使用参数传递信息,不依赖上下文环境,即不使用闭包函数)
2. 移除前置条件(sum函数中使用数组传递参数,不再限定参数个数)
3. 简化后置条件(移除参数之间的关系,使sum返回的是数组全部元素的和)
需求的类型
1. 功能需求:根据所需的活动描述所需的行为
2. 质量需求或非功能需求:描述软件必须具备的一些质量特性
3. 设计约束(设计约束): 设计决策,例如选择平台或接口组件
4. 过程约束(过程约束): 对可用于构建系统的技术或资源的限制
需求分析的两种方法
1. 原型化方法
原型化方法可以很好地整理出用户接口方式(UI,User Interface),比如界面布局和交互操作过程。
2. 建模的方法
建模的方法可以快速给出有关事件发生顺序或活动同步约束的问题,能够在逻辑上形成模型来整顿繁杂的需求细节。
基本概念
用例(Use Case)的核心概念中首先它是一个业务过程(business process),经过逻辑整理抽象出来的一个业务过程,这是用例的实质。什么是业务过程?在待开发软件所处的业务领域内完成特定业务任务(business task)的一系列活动就是业务过程。
四个必要条件
必要条件一 :它是不是一个业务过程?
必要条件二:它是不是由某个参与者触发开始?
必要条件三:它是不是显式地或隐式地终止于某个参与者?
必要条件四: 它是不是为某个参与者完成了有用的业务工作?
三个抽象层级
1. 抽象用例(Abstract use case)。只要用一个干什么、做什么或完成什么业务任务的动名词短语,就可以非常精简地指明一个用例。
2. 高层用例(High level use case)。需要给用例的范围划定一个边界,也就是用例在什么时候什么地方开始,以及在什么时候什么地方结束;
3. 扩展用例(Expanded use case)。需要将参与者和待开发软件系统为了完成用例所规定的业务任务的交互过程一步一步详细地描述出来,一般我们使用一个两列的表格将参与者和待开发软件系统之间从用例开始到用例结束的所有交互步骤都列举出来。
设计模式的本质是面向对象设计原则的实际运用总结出的经验模型。目的是包容变化,即通过使用设计模式和多态等特殊机制,将变化的部分和不变的部分进行适当隔离。(高内聚,低耦合)
正确使用设计模式具有以下优点:
可以提高程序员的思维能力、编程能力和设计能力。
使程序设计更加标准化、代码编制更加工程化,使软件开发效率大大提高,从而缩短软件的开发周期。
使设计的代码可重用性高、可读性强、可靠性高、灵活性好、可维护性强。
设计模式由四个部分组成:
该设计模式的名称;
该设计模式的目的,即该设计模式要解决什么样的问题;
该设计模式的解决方案;
该设计模式的解决方案有哪些约束和限制条件。
根据作用对象分两类:
类模式:用于处理类与子类之间的关系,这些关系通过继承来建立,是静态的,在编译时刻便确定下来了。比如模板方法模式等属于类模式。
对象模式:用于处理对象之间的关系,这些关系可以通过组合或聚合来实现,在运行时刻是可以变化的,更具动态性。由于组合关系或聚合关系比继承关系耦合度低,因此多数设计模式都是对象模式。
七大原则
1. 单一职责原则 (Single Responsibility Principle)
2. 开放关闭原则 (OpenClosed Principle)
3. 里氏替换原则 (Liskov Substitution Principle)
4. 依赖倒转原则 (Dependence Inversion Principle)
5. 接口隔离原则 (Interface Segregation Principle)不考
6. 迪米特法则(Law Of Demeter)
7. 组合/聚合复用原则 (Composite/Aggregate Reuse Principle)
主要区别在于,MVC中,用户对于M的操作是通过C传递的,然后C将改变传给V,并且M将在发生变化时通知V,然后V通过C获取变化;在MVVM中,用户直接与V交互,通过VM将变化传递给M,然后M改变之后通过VM将数据传递给V,从而实现解耦。
另一个区别是,当M的数据需要进行解析后V才能使用时,C若承担解析的任务,就会变得很臃肿;在MVVM中,VM层承担了数据解析的工作,这时C就只需要持有VM,而不需要直接持有M了。从而完成了数据的解耦。
1. 克隆,完整地借鉴相似项目的设计方案,甚至代码,只需要完成一些细枝末节处的修改适配工作。
2. 重构,构建软件架构模型的基本方法,通过指引我们如何进行系统分解,并在参考已有的软件架构模型的基础上逐步形成系统软件架构的一种基本建模方法。
几种架构的分解方法
面向功能的分解方法,用例建模即是一种面向功能的分解方法;
面向特征的分解方法,根据数量众多的某种系统显著特征在不同抽象层次上划分模块的方法;面向数据的分解方法,在业务领域建模中形成概念业务数据模型即应用了面向数据的分解方法;
面向并发的分解方法,在一些系统中具有多种并发任务的特点,那么我们可以将系统分解到不同的并发任务中(进程或线程),并描述并发任务的时序交互过程;
面向事件的分解方法,当系统中需要处理大量的事件,而且往往事件会触发复杂的状态转换关系,这时系统就要考虑面向事件的分解方法,并内在状态转换关系进行清晰的描述;
面向对象的分解方法,是一种通用的分析设计范式,是基于系统中抽象的对象元素在不同抽象层次上分解的系统的方法。
架构的描述方法
分解视图 Decomposition View
依赖视图 Dependencies View
泛化视图 Generalization View
执行视图 Execution View
实现视图 Implementation View
部署视图 Deployment View
工作任务分配视图 Workassignment View
基本要素
1. 团队的规模
2. 团队的凝聚力
3. 团队协作的基本条件
评价团队的方法
CMM/CMMI用于评价软件生产能力并帮助其改善软件质量的方法,成为了评估软件能力与成熟度的一套标准,它侧重于软件开发过程的管理及工程能力的提高与评估,是国际软件业的质量管理标准。
CMMI共有5个级别,代表软件团队能力成熟度的5个等级,数字越大,成熟度越高,高成熟度等级表示有比较强的软件综合开发能力。
一级,初始级,软件组织对项目的目标与要做的努力很清晰,项目的目标可以实现。但主要取决于实施人员。
二级,管理级,软件组织在项目实施上能够遵守既定的计划与流程,有资源准备,权责到人,对项目相关的实施人员进行了相应的培训,对整个流程进行监测与控制,并联合上级单位对项目与流程进行审查。这级能保证项目的成功率。
三级,已定义级,软件组织能够根据自身的特殊情况及自己的标准流程,将这套管理体系与流程予以制度化。科学管理成为软件组织的文化与财富。
四级,量化管理级,软件组织的项目管理实现了数字化,降低了项目实施在质量上的波动。
五级,持续优化级,软件组织能够充分利用信息资料,对软件组织在项目实施的过程中可能出现的问题予以预防。能够主动地改善流程,运用新技术,实现流程的优化。
敏捷方法的敏捷宣言
个体和互动 高于 流程和工具
工作的软件 高于 详尽的文档
客户合作 高于 合同谈判
响应变化 高于 遵循计划
尽管右项有其价值,我们更重视左项的价值。
代码中的软件工程: https://gitee.com/mengning997/se
作者:281

就我个人而言,收获最大的是前面几节有关工具介绍的课,特别是那个打字网站
这是最大收获? 练习打字?

