34
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
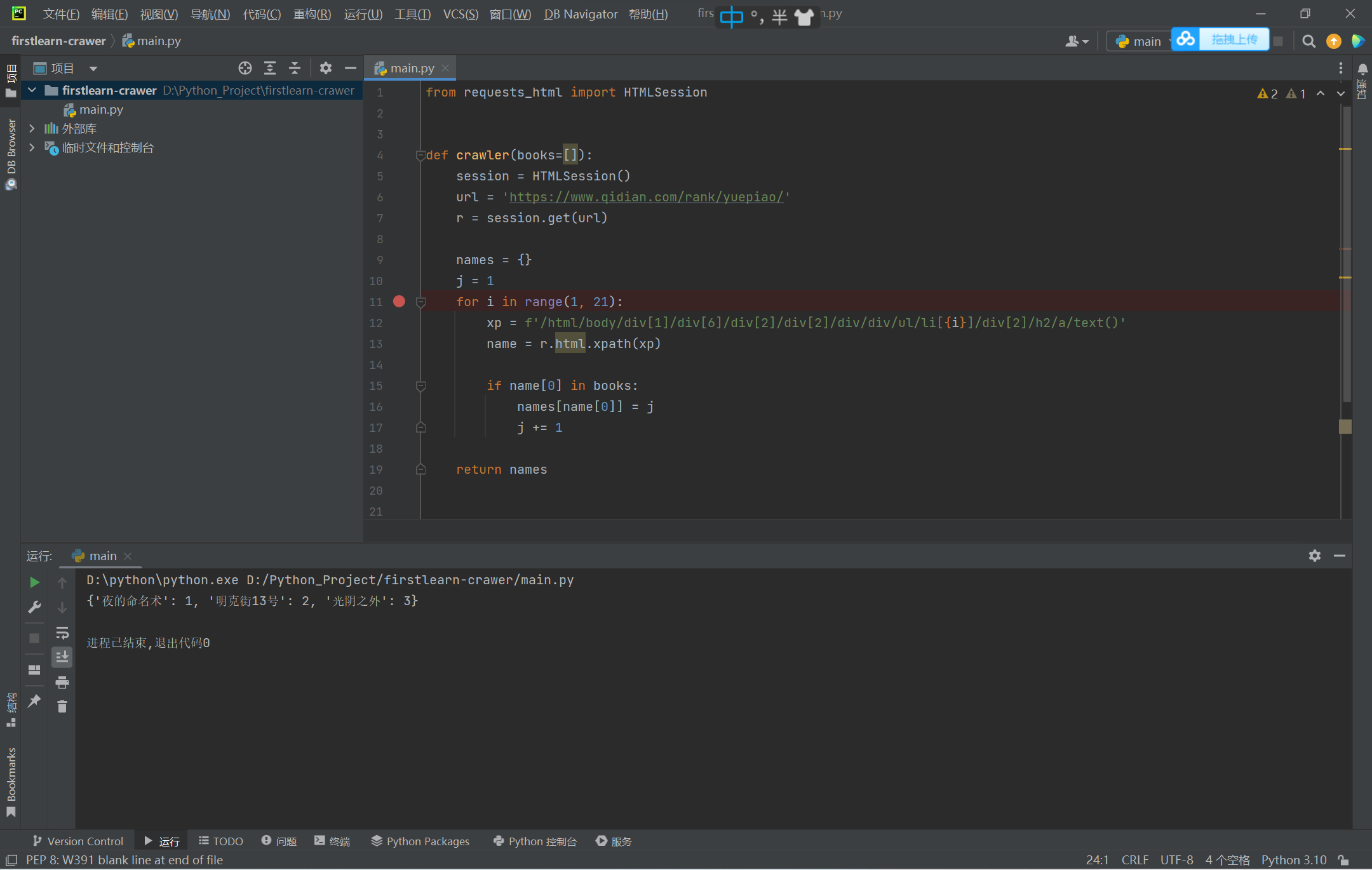
from requests_html import HTMLSession
def crawler(books=[]):
session = HTMLSession()
url = 'https://www.qidian.com/rank/yuepiao/'
r = session.get(url)
names = {}
j = 1
for i in range(1, 21):
xp = f'/html/body/div[1]/div[6]/div[2]/div[2]/div/div/ul/li[{i}]/div[2]/h2/a/text()'
name = r.html.xpath(xp)
if name[0] in books:
names[name[0]] = j
j += 1
return names
print(crawler(['光阴之外', '夜的命名术', '明克街13号']))