34
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
# NPU 程序设计实训 HW20 爬虫
import time
import requests
from bs4 import BeautifulSoup
def crawler(book_list):
sort_list = []
for page in range(1, 6):
url = f'https://www.qidian.com/rank/yuepiao?style=1&page={page}'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/'
'87.0.4280.66 Safari/537.36'}
ret = requests.get(url, headers=headers).text
soup = BeautifulSoup(ret, "html.parser")
books = soup.find_all(**{'data-eid': "qd_C40"})
for book in books:
book_name = book.get_text()
if book_name in book_list:
sort_list.append(book_name)
return {book_name:index+1 for index, book_name in enumerate(sort_list)}
# 函数测试
book_list = ["光阴之外", "我已不做大佬好多年", "这游戏也太真实了"]
print(crawler(book_list))
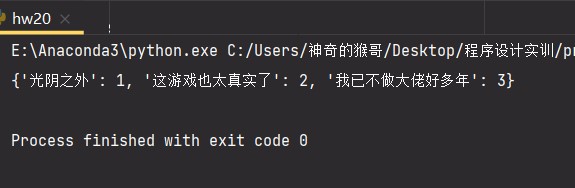
结果如图